
Intel’s Gracemont Small Core Eclipses Last-Gen Big Core Performance

Two years ago Intel introduced Tremont. This was a ground-up new high-efficiency core (E-Core) designed to bring a step-function improvement in both performance and power consumption over the prior generation. The result was a highly dense core that reached Haswell’s level of performance. Today, at Intel’s 2021 Architecture Day, they introduced its successor – Gracemont.
This article is part of a series of articles covering Intel’s 2021 Architecture Day:
- Intel’s Gracemont Small Core Eclipses Last-Gen Big Core Performance
- Intel Details Golden Cove For Next-Generation Client and Server CPUs
- Intel Unveils Alder Lake: Next-Generation Mainstream Heterogeneous Multi-Core SoC
- Intel Unveils Sapphire Rapids: Next-Generation Server CPUs
- Intel Introduces Thread Director For Heterogeneous Multi-Core Workload Scheduling
- Intel’s Mount Evans: Intel’s First ASIC DPU
- Intel Unveils Xe HPG – Discrete Graphics For Gamers
- Intel Unveils Xe HPC And Ponte Vecchio
Overview
Gracemont top-level design targets are very similar to Tremont which was the starting point for the new small core. Tremont was set out to be a high energy-efficiency core with ‘Core-class’ components such as a branch predictor, prefetcher, and other important performance mechanisms. With, Gracemont, Intel took this a step further. Its primary goal was to be the most energy-efficient x86 core to date while providing higher IPC than Intel’s previous-generation big core performance – Skylake (which found its way to many other successor SoCs such as Kaby Lake and Coffee Lake). Some other constraints included efficient implementation on Intel 7 for dense implementations such that those cores could be used in relatively large numbers to scale multi-core workloads.
Front-End
Gracemont builds on the previous Tremont microarchitecture. A significant amount of effort was made in improving the effective instruction stream throughput throughout the core. Intel says that it has significantly beefed up the branch predictor including increasing the BTB to 5K entries. This, in turn, helped keep the instruction pointer queue populated more accurately. Backing up the instruction fetch on Gracemont is a 64 KiB instruction cache. Not only is this double the capacity of Tremont, but it’s also the largest instruction cache of any x86 code designed to date.
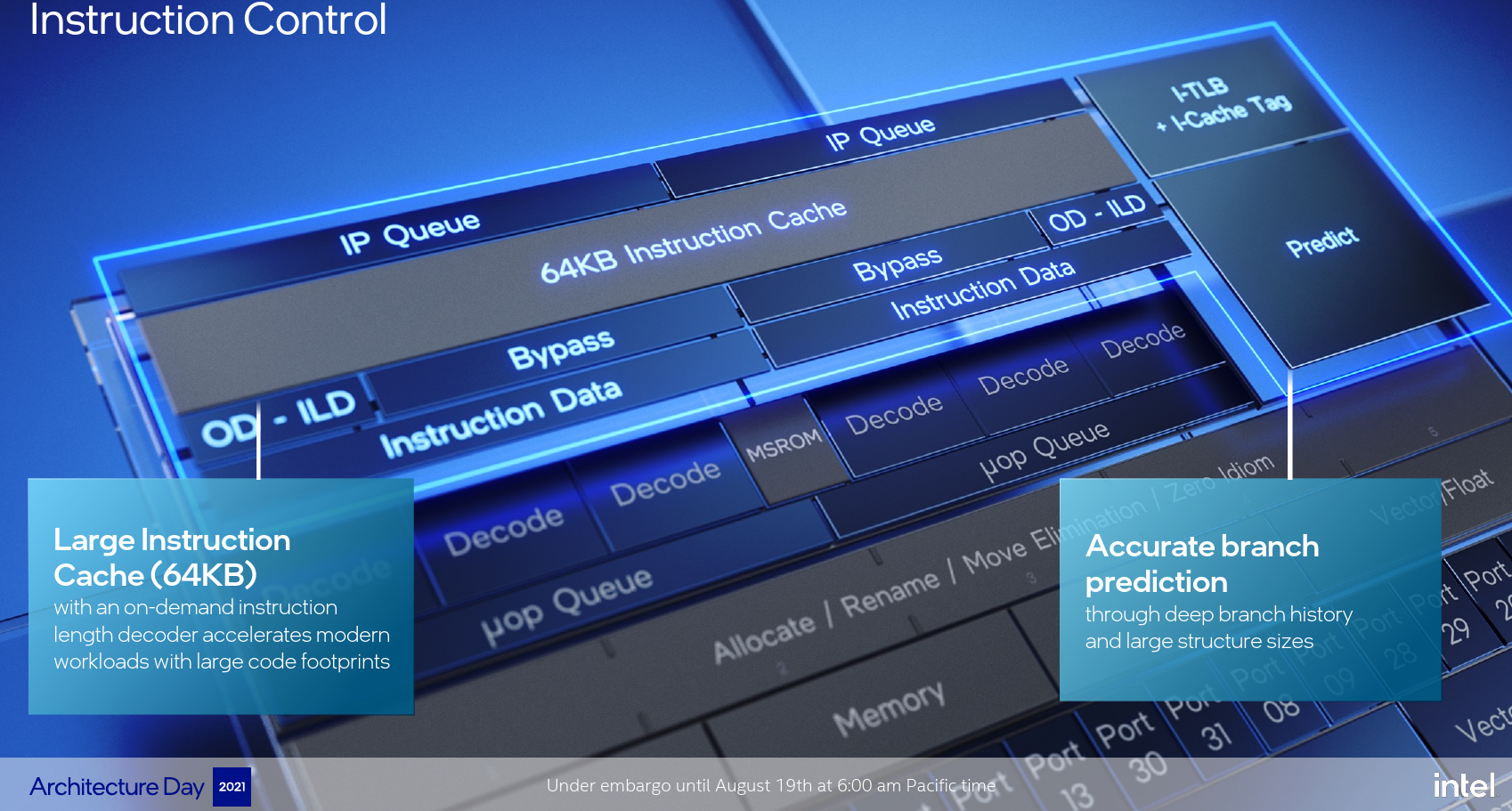
The new instruction cache on Gracemont is actually very unique. x86 instruction encoding is all over the place and in the worst (and very rare) case can be as long as 15 bytes long. Pre-decoding an instruction is a costly linear operation and you can’t seek the next instruction before determining the length of the prior one. Gracemont, like Tremont, does not have a micro-op cache like the big cores do, so instructions do have to be decoded each time they are fetched. To assist that process, Gracemont introduced a new on-demand instruction length decoder or OD-ILD for short. The OD-ILD generates pre-decode information which is stored alongside the instruction cache. This allows instructions fetched from the L1$ for the second time to bypass the usual pre-decode stage and save on cycles and power.
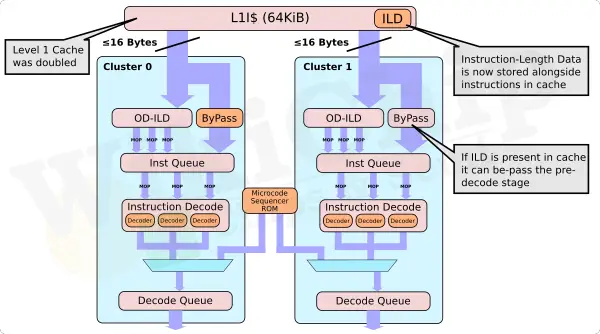
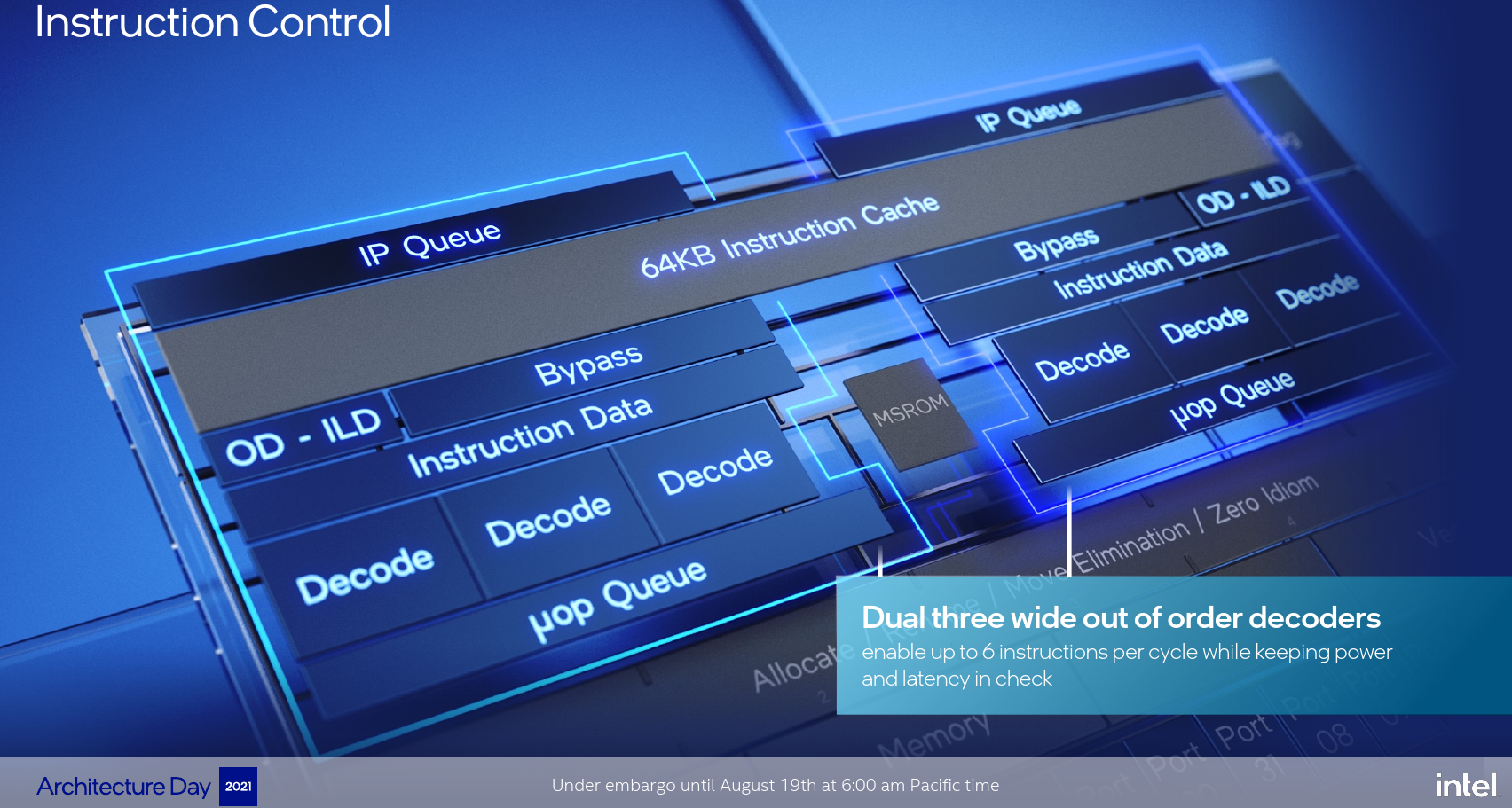
Like Tremont, Gracemont continues with its novel 3-Way Symmetric Decode which can fetch and decode two instruction streams – possibly out-of-order. A hardware-driven load balancer is also capable of taking long chains of sequential instructions and automatically inserts toggle points to ensure parallelism.
Back-End
To increase the data parallelism, the out-of-order window was enlarged to 256 entries. This is actually a huge size for a small core. Gracemont has a large OoO window than both Skylake and Zen 2. It does fall significantly behind Sunny Cove and Golden Cove.
| x86 uArch ROB Sizes | |||||||
|---|---|---|---|---|---|---|---|
| Tremont | Gracemont | Skylake | Sunny Cove | Golden Cove | Zen 2 | Zen 3 | CHA |
| 208 | 256 | 224 | 352 | 512 | 224 | 256 | 192 |
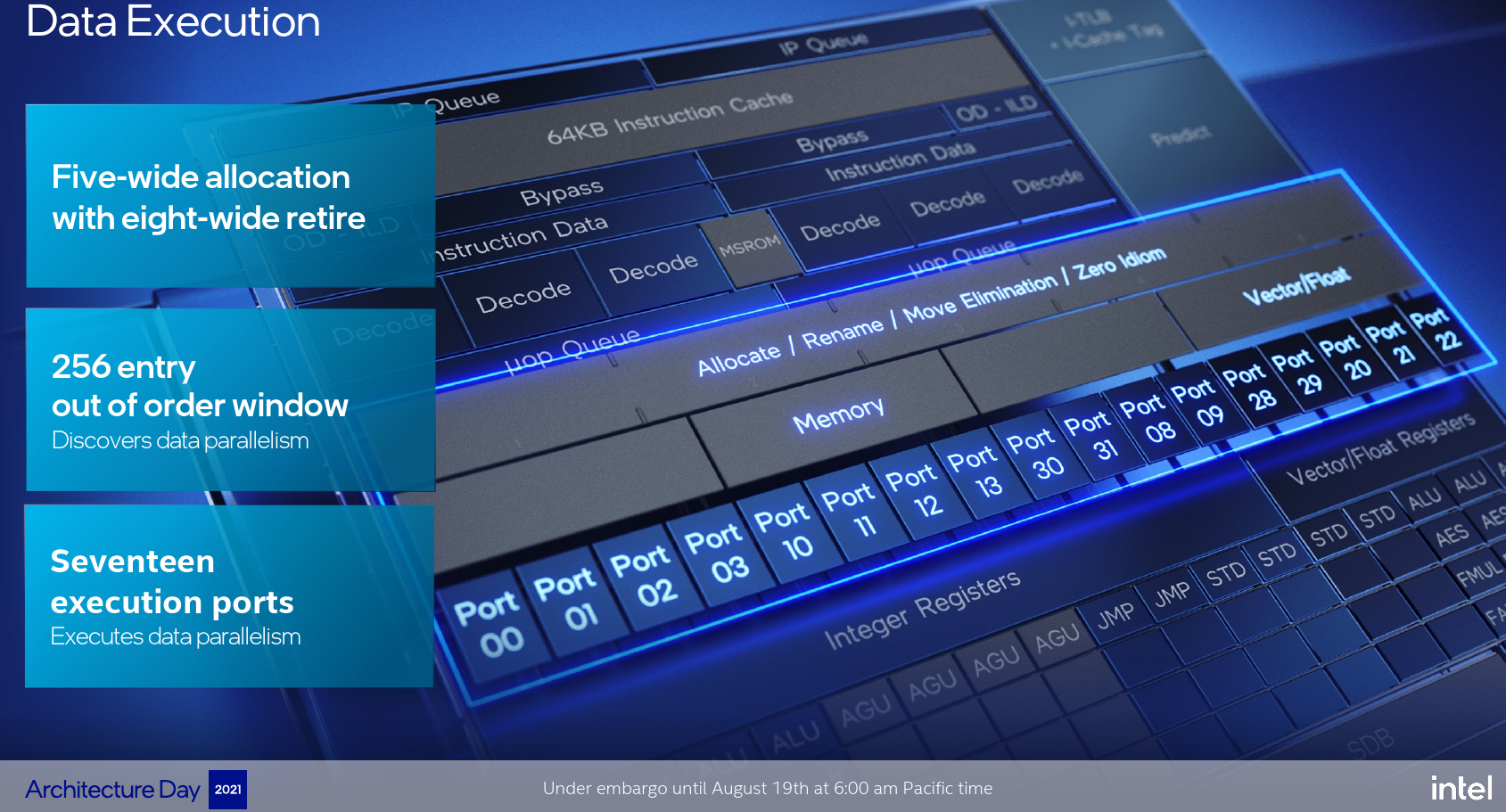
On the execution engine side, Gracemont went all out on execution units. While Tremont already featured a fairly wide 10-port back-end, Gracemont takes the cake with seventeen individual execution points.
On the integer cluster, Gracemont added another integer ALU pipe for a total of 4 ALUs. The four general-purpose integers ALUs are now complemented by a dual multiply/divide pipelines. Additionally, Gracemont can now resolve up to two branches/cycle – double what Tremont was capable of.
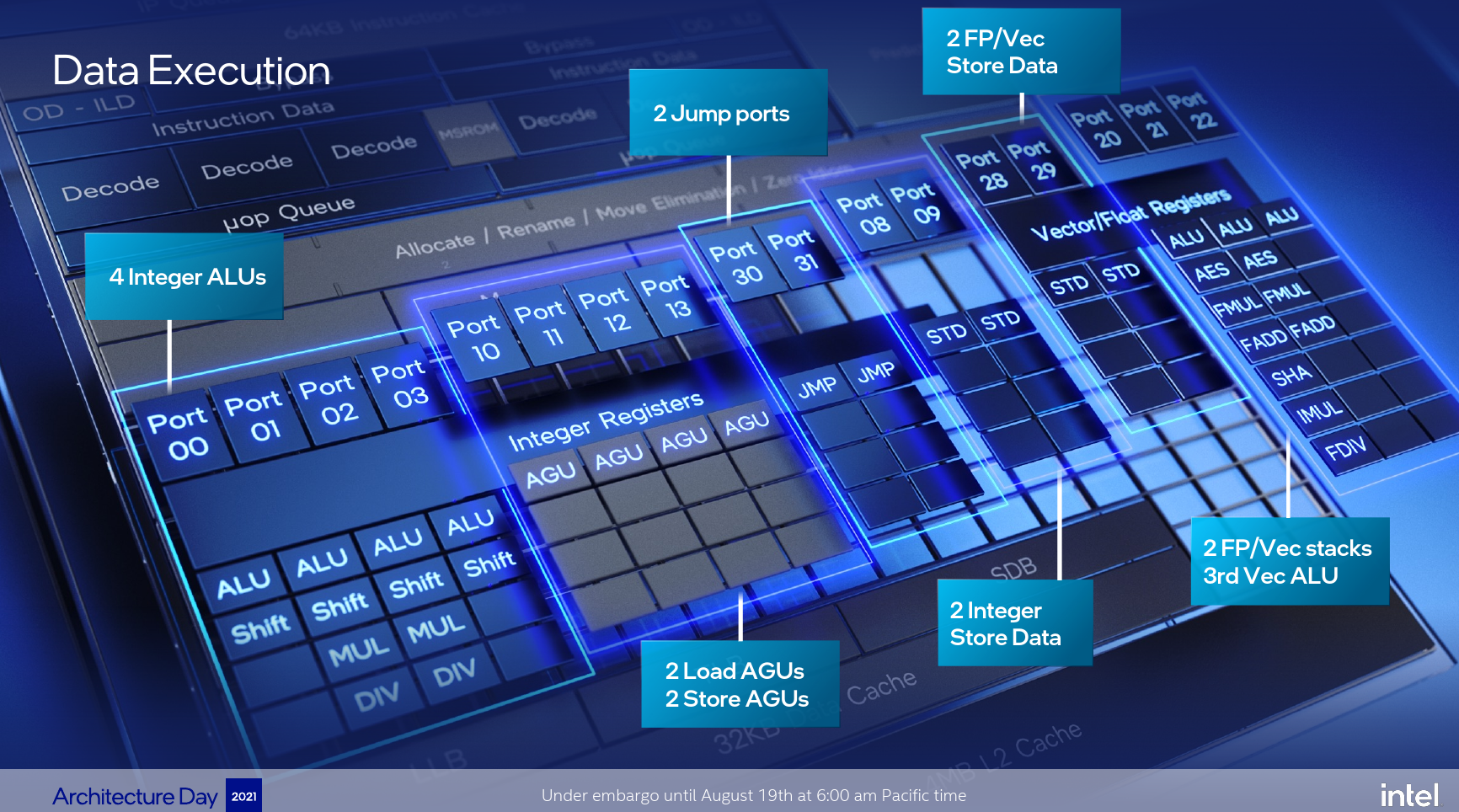
On the vector cluster, Gracemont features three SIMD ALUs which is one more than Tremont. Gracemont ISA supports up to AVX2 or roughly the ISA support level of Haswell. However, Gracemont does incorporate an array of new instructions beyond what Haswell technically supported such as AVX-VNNI for accelerating AI workloads. There is also support for some new security/side-channel analysis mitigation such as Control-Flow Enforcement Technology. Gracemont also doubled the complex pipeline – producing two symmetric FADD and FMUL pipes so it’s now possible to execute two independent add or multiply operations per cycle.

Memory Subsystem
The memory subsystem on Gracemont has been improved. Gracemont doubled the number of AGU pipelines for a total of four. Previously, Tremont had two load/store pipelines, meaning each cycle, an address can be generated for two loads, two stores, or one of each. With Gracemont, there is a dedicated dual load pipeline and a dedicated dual store pipeline. So each cycle, two loads address generation and two stores can be done each cycle.

Gracemont cores are grouped into a quad-core cluster. Multiple instances of that cluster are integrated into the final product. The exact number of clusters (and cores) varies by product. The L2 cache is private to each cluster and is shared by all four cores. An entire cache line (64 bytes) may be sent to the L1 each cycle. The size of the L2 can be either 2 MiB or 4 MiB depending on the actual product. The shared L2 cache features a 64-entry line fill buffer to support all the necessary outstanding misses to the LLC or main memory.

A Small Core With Big Performance – Faster Than Last Gen Big Core
Gracemont is new and beefier than all prior cores, yet it is said to be extremely powerful and area efficient. “This microarchitecture delivers more general integer IPC than Intel Skylake core while consuming a fraction of the power,” said Stephen Robinson, Gracemont Chief Architect. Now, it is important to point out that Skylake was a 14-nanometer product while Gracemont is an Intel 7 product, but regardless that is a pretty big achievement considering they are claiming their latest small core is both lower power and higher performance than the big cores in my laptop from just a few years ago.
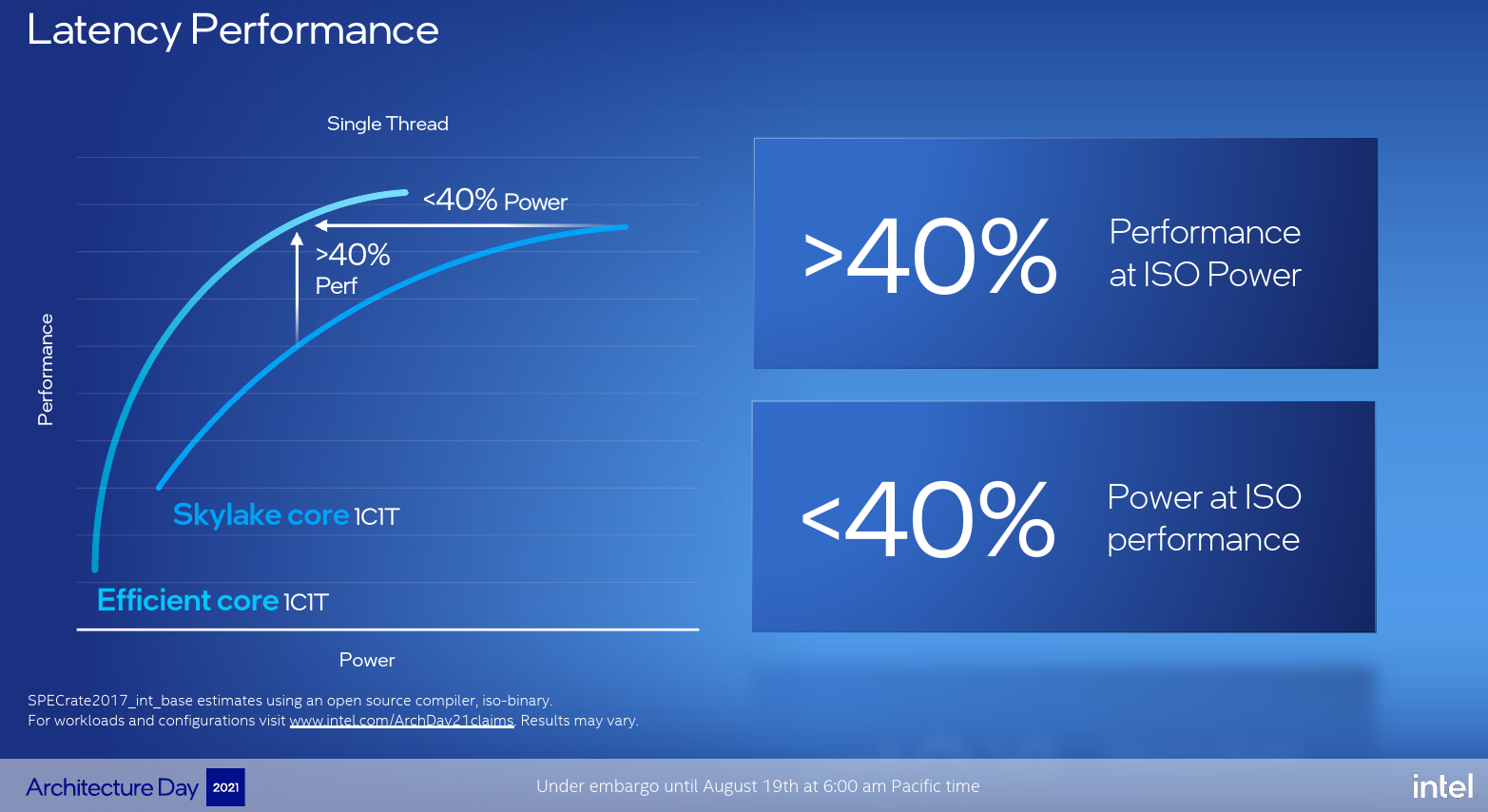
In terms of latency performance (SPECrate2017_int_base) using a 1C/1T configuration, Intel claims Gracemont achieves 40% higher performance at ISO-power. Alternatively, Intel says that Gracemont consumes less than 40% of the power at ISO-performance. In other words, a Skylake core will require 2.5x the power to achieve the same performance as the Gracemont core.
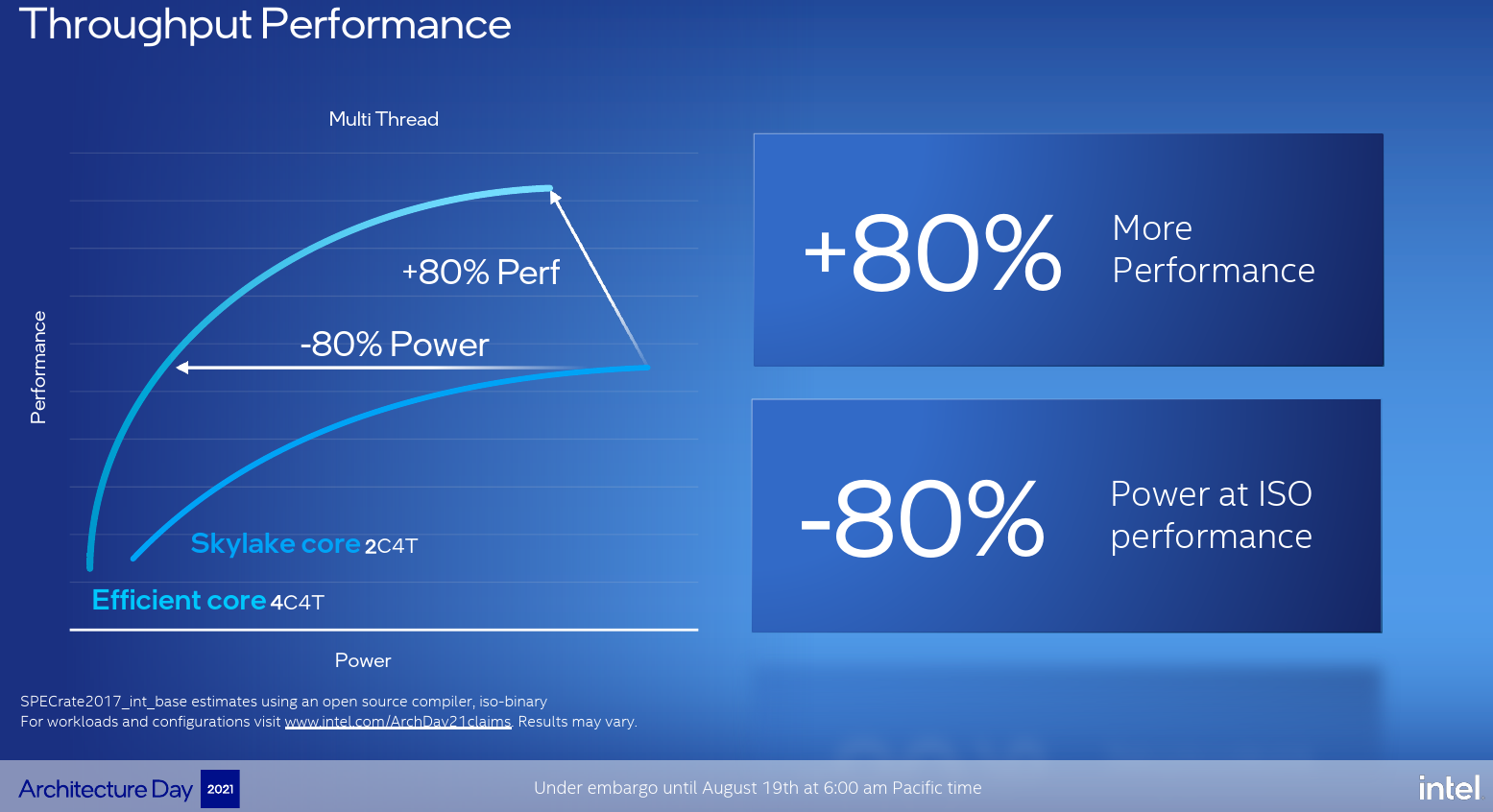
Because silicon density was also a big requirement for Gracemont, it’s something to take note of. A single Skylake core takes up about the same silicon area as an entire Gracemont quad-core cluster (with the L2 cache). When comparing 2 Skylake cores running 4 threads to a single Gracemont 4-quad cluster, Intel says that the Gracemont cluster achieves 80% more performance while consuming less power. Alternatively, the Gracemont cluster consumes 80% less power at ISO-performance. In other words, it would take Skylake 5x the power to achieve the same performance as the Gracemont cores.
This article is part of a series of articles covering Intel’s 2021 Architecture Day:
- Intel’s Gracemont Small Core Eclipses Last-Gen Big Core Performance
- Intel Details Golden Cove For Next-Generation Client and Server CPUs
- Intel Unveils Alder Lake: Next-Generation Mainstream Heterogeneous Multi-Core SoC
- Intel Unveils Sapphire Rapids: Next-Generation Server CPUs
- Intel Introduces Thread Director For Heterogeneous Multi-Core Workload Scheduling
- Intel’s Mount Evans: Intel’s First ASIC DPU
- Intel Unveils Xe HPG – Discrete Graphics For Gamers
- Intel Unveils Xe HPC And Ponte Vecchio
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–