
Arm Launches New Neoverse N2 and V1 Server CPUs: 1.4x-1.5x IPC, SVE, and ARMv9

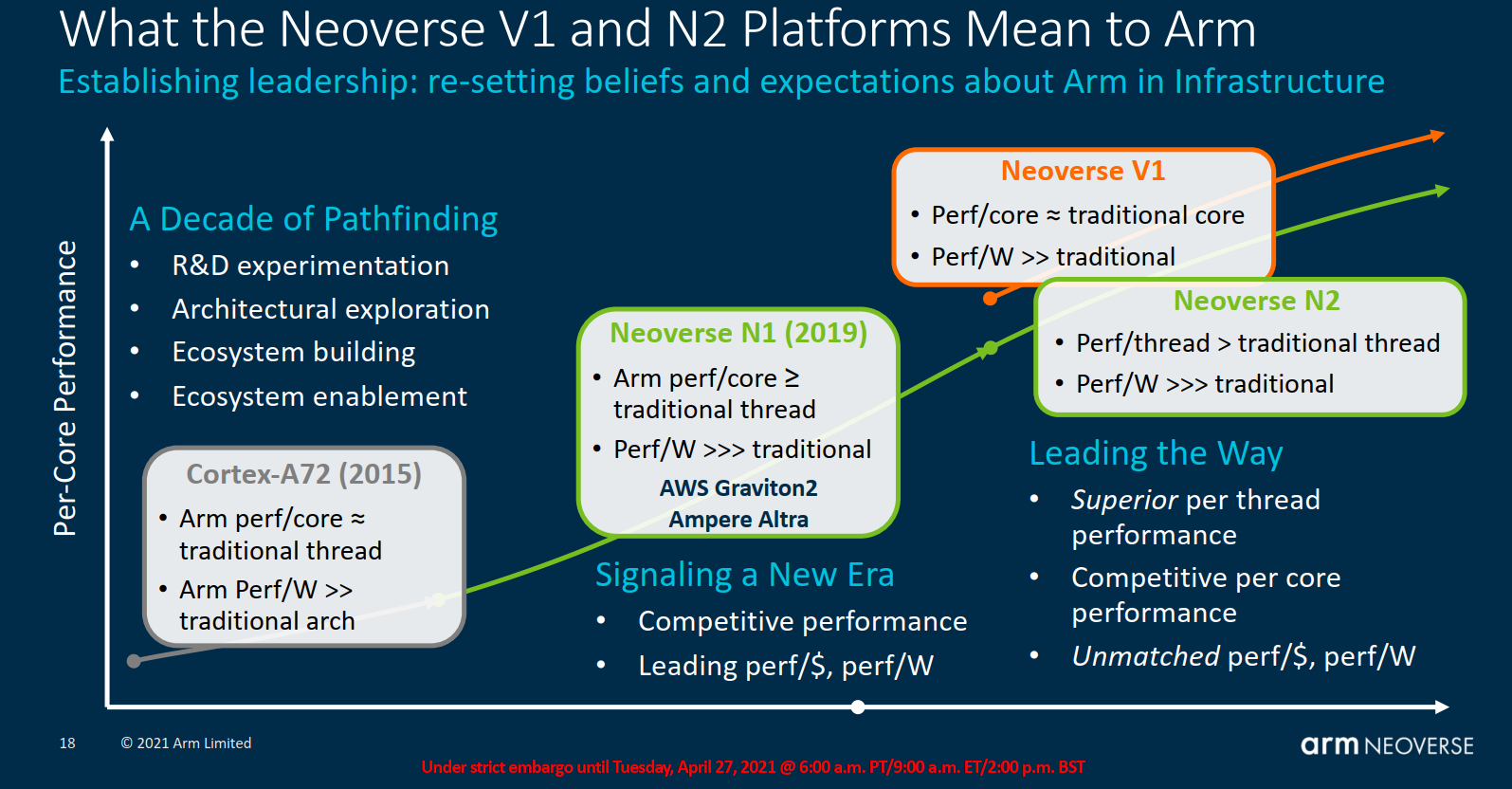
Today Arm is expanding its infrastructure line of IPs with the launch of two new server CPU cores. The Neoverse, which was announced just a few years ago, has grown into three distinct families of IPs – The Neoverse E-Series, N-Series, and V-Series. The E-Series offers a slim-down design with multi-threading support that is optimized for high-throughput efficiency. The N-Series is the mainline Scale-Out performance IP CPU core which offers a balanced high-performance design. The N-Series is the core behind most of the Arm server CPUs including the AWS Graviton 2. Finally, the V-Series is a new series that is designed for maximum performance at a modest power and area cost.
Two new server CPUs are being launched today – a new Neoverse N2 core design to succeed the Neoverse N1, and a new Neoverse V1 CPU specifically optimized for the high-performance computing market. At a high level, Arm is positioning the Neoverse V1 as a beefy core with significantly higher single-thread and vector performance. Likewise, The Neoverse N2 is a direct successor to the Neoverse N1 for general-purpose server applications where Arm is positioning it as having higher per-thread performance than traditional x86 cores at considerably lower power. In fact, Arm says the ratio is around 3:1 in terms of replacing traditional SMT threads with cores, power-wise, which allows a large core-count-based Neoverse N2 SoC to compete well against traditional x86 SoCs with comparable thread count.
We can expect to find the Neoverse V1 core in very high performance applications. One such example is the SiPearl Rhea SoC, a European microprocessor designed for exascale supercomputers planned for the 2022 timeframe. The Neoverse N2 will likely make its way into a very broad range of chips from infrastructure edge (e.g., 5G basestations) to server CPUs (e.g., next-generation Amazon AWS CPU).
Neoverse V1
The first CPU core IP Arm is launching today is the Neoverse V1. Formerly codenamed Zeus, this core is part of a new tier of Arm infrastructure Neoverse CPU cores that explicitly targets the HPC market. It does so by relaxing the traditional requirements of power and area that Arm typically imposes on their architectures in favor of higher performance. In a sense, the Neoverse V1 is an offshoot of the Neoverse N2 which is further optimized for performance just like the Cortex-X1. That said, Arm expects the Neoverse V1 to be their highest-performance core to date. We will get into the performance claims a little later in the article but for now, we’ll just leave you with a single performance claim: 48% IPC improvement over the Neoverse N1 in an average across a whole array of industry-standard workloads as well as SPEC CPU 2006 and 2017 – an incredible performance improvement claim for a single generation of CPU cores.
Zeus goes straight after raw performance improvement and it does so by trading off a bit of power efficiency and area. In fact, in an ISO-process comparison, the Neoverse V1 is about 1.7x the area and 0.7x-1x the power efficiency of the Noeverse N1. The V1 maintains the same frequency as the N1 therefore all of its performance improvements comes entirely from its ~1.5x IPC uplift and the new ISA extensions. Since we expect the new V1 implementations to show up on 6nm, 5nm, and below, most of the power efficiency delta should be eliminated and the silicon area will be reduced substantially.
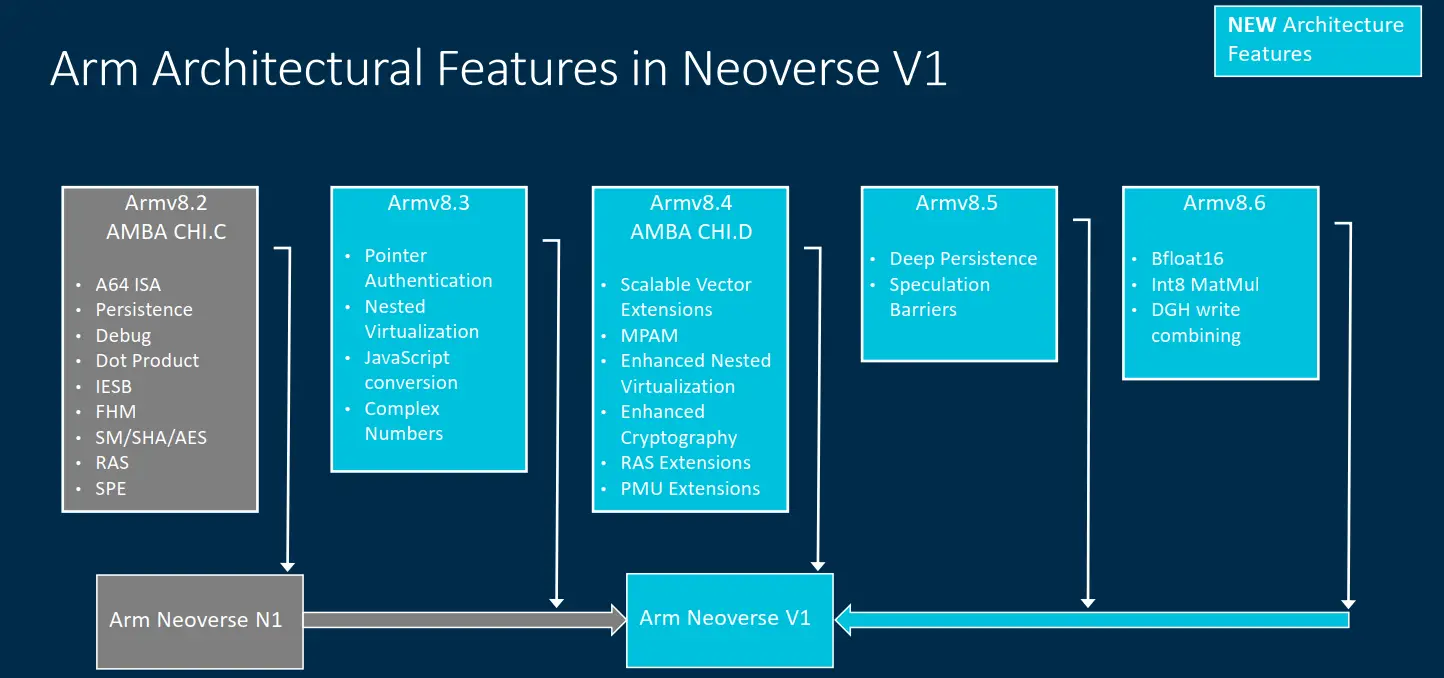
Despite ARM rolling out new ISA extensions almost yearly, many of Arm’s own recent client CPU cores have been needlessly stuck on the ARMv8.2 ISA. Like the client CPUs, the Noeverse N1 also only implemented up to ARMv8.2. The trend finally stops with the new Neoverse V1. The Zeus core finally implements the ARMv8.4 ISA which means Scalable Vector Extensions (SVE) support, nested virtualization (& enhanced), JavaScript conversion, Complex Numbers extension, and various security extensions such as Pointer Authentication. It’s also worth noting that although the Neoverse V1 does not fully support the v8.5 and 8.6 ISAs, it still implements a large portion of those revisions. From ARMv8.5, Zeus implements Deep Persistence support cache cleaning support and Speculation Barriers. From ARMv8.6, Zeus implements BFloat16, Int8 MatMul, and DGH write combining.

Under the hood
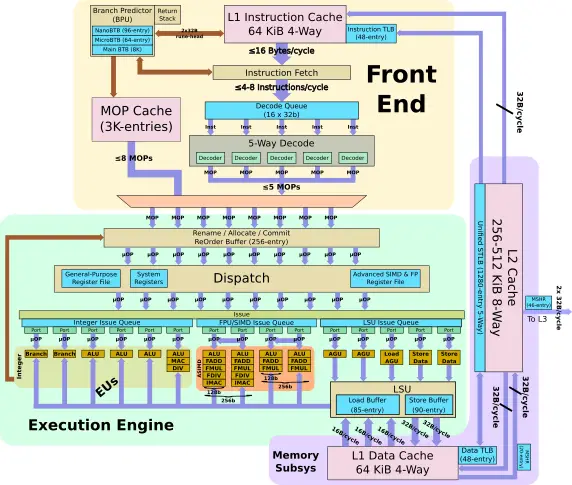
Zeus is another design by the Austin, TX team and therefore builds on the prior Noeverse N1 core. The front end of the machine builds up many of the N1 buffers. Since the introduction of the Cortex-A76, the branch prediction unit has been decoupled from the instruction fetch, allowing it to run ahead into the instruction cache. The improvements that were first introduced with the Cortex-A77 have made their way to the V1 now. The Neoverse V1 doubles the bandwidth of that window to up to 2x32B per cycle. For a larger code footprint, the two main BTBs have been enlarged and there have been various improvements to the conditional branch accuracy.
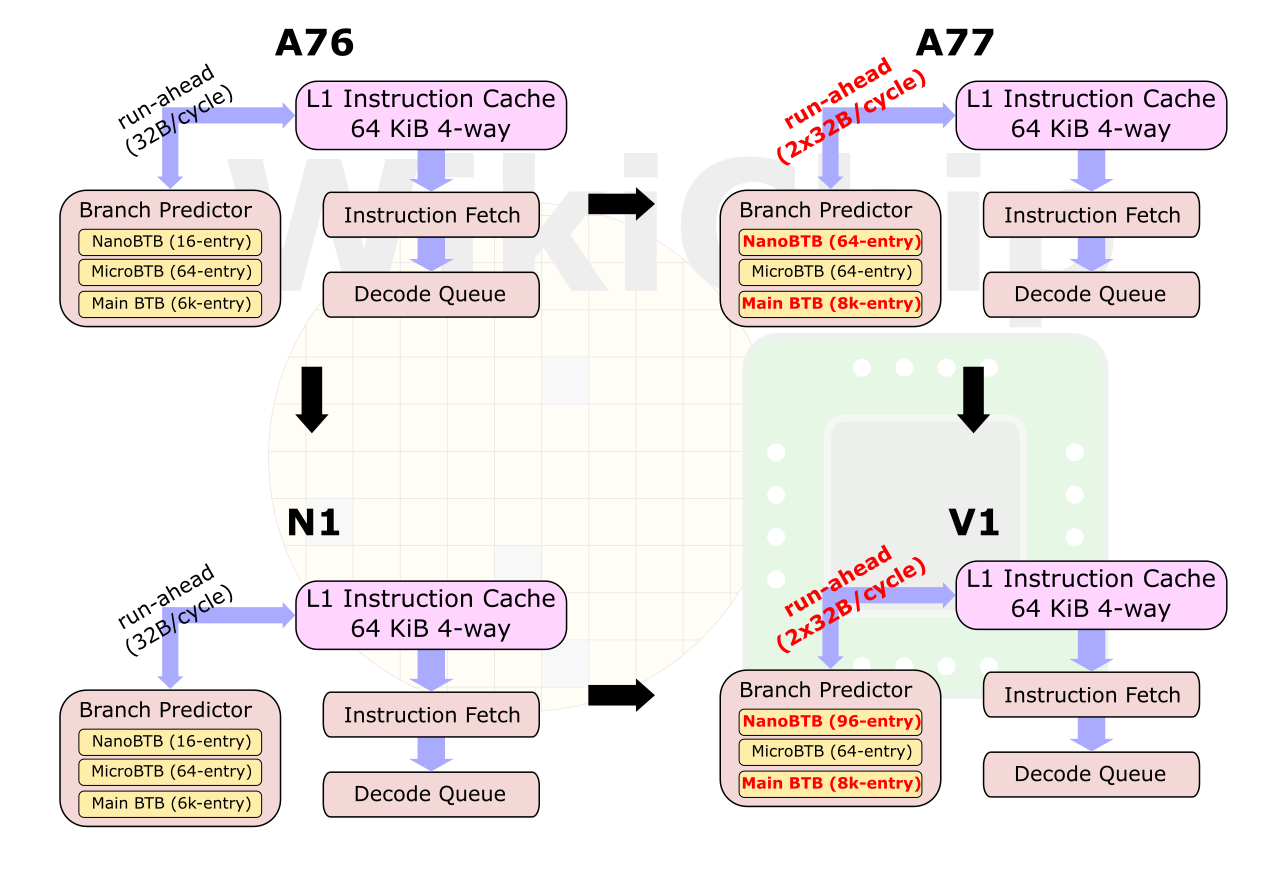
Everything related to the branch predictor has improved on the Zeus. The main BTB buffer size now matches that of the Cortex-A78 while the nano BTB is now larger than any other Arm core at 96 entries. Internally, Arm doubled the number of code regions that are able to be tracked in the front-end. Arm says this provides significant performance improvement to applications such as large Java applications with very large and sparsed regions of code. Arm says that for some workloads, up to 90% reduction in branch mispredicts have been observed and the improvements to bandwidth and buffers have resulted in up to 50% reduction in front-end stalls.

The decode area of the new Neoverse V1 is where significant changes took place. Introducing and expanding much of the logic from the Cortex-A77, the new V1 pulls in the MOP cache. The MOP cache is an L0 pre-decoded instruction cache that can send the decoded MOPs directly to the back-end of the machine for execution. In addition to its role of bypassing the decode unit altogether thereby saving power, it also cuts a single pipeline stage out of the path. The V1 has a huge MOP cache in terms of both capacity and bandwidth. On the V1, the MOP cache size is 3K-entry deep and is capable of streaming up to eight instructions per cycle directly to rename. Both the capacity and bandwidth are similar to that of AMD’s Zen 3 microarchitecture which features a 4K MOP cache with a bandwidth of up to 8 fused MOPs (although it’s worth noting that the MOP cache on AMD machines are physically tagged, therefore non-shared code will compete for capacity for two SMT threads, something that does not happen on the Neoverse V1).
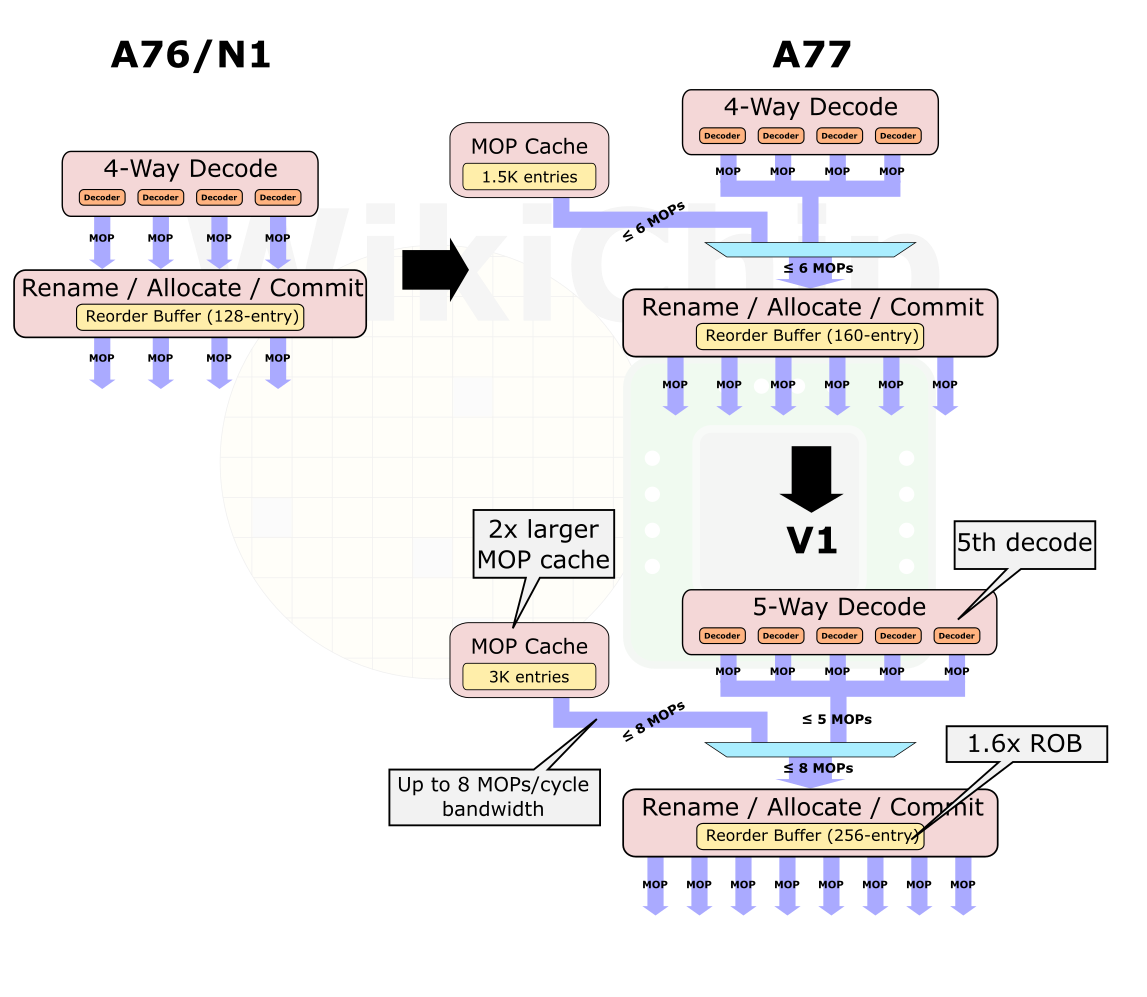
The V1 also offers a wider, 5-wide decode from the traditional pipeline path while allowing up to 8 MOPs/cycle from the new MOP cache. Both bandwidths are by far the widest Arm core and with a decode that is wider than any of the x86 cores. Only Apple is presumed to have implemented a wider pipeline. To match the higher bandwidth, Arm doubled the ROB size on the V1 to 256 entries. The effective capacity of the ROB can actually exceed that number with various instruction pairs that can be fused and be treated as a single entry in the ROB. To that end, Arm says they have added new instruction fusion cases as well.
| Designer | Intel | AMD | Arm |
|---|---|---|---|
| uArch | Sunny Cove | Zen 3 | Zeus |
| ROB | 352 | 256 | 256 |
| OP$/MOP$ | 2K | 4K | 3K |
| OP$/MOP$ BW | 6 uOPS/clk | 8 MOPS/clk | 8 MOPS/clk |
Execution Units
The back end of the Neoverse V1 has been widened as well. In order to support the new Scalable Vector Extension, Arm doubled the vector/FP execution units. There are now two 256b SVE vector units that can support up to two 256b operations/cycle. When executing legacy NEON or FP operations, the vector units can support up to 4x128b operations/cycle. There is also support for bfloat16 as well as the new Matrix Multiply extension which supports INT8 2×2 operations for the acceleration of machine learning workloads. Whereas for single-precision and double-precision operations, the peak compute has doubled, for the new 16-bit and 8-bit matrix multiply operations, the peak computer is effectively 4 times that of the Neoverse N1. As with the Cortex-A77, the Neoverse V1 also brings a second branch unit. All in all, the execution end of the Neoverse V1 is 15-wide.

With the new large vector units and SVE support, the Neoverse V1 can be said to offer double the 64-bit and 32-bit floating-point operations per cycle.
| Vector Performance (FLOPs) | |||
|---|---|---|---|
| Designer | Intel | AMD | Arm |
| uArch | Sunny Cove | Zen 3 | Zeus |
| ISA | AVX-512 | AVX2 | SVE |
| EUs | 2 × 512-bit FMA | 2 × 256-bit FMA | 2 × 256-bit FMA |
| DP FLOPs | 32 FLOPs/clk | 16 FLOPs/clk | 16 FLOPs/clk |
| SP FLOPs | 64 FLOPs/cycle | 32 FLOPs/clk | 32 FLOPs/clk |
On the memory side, the Neoverse V1 actually reached parity with the Cortex-A78 which added a new dedicated AGU. Previously, there were two generic AGUs – both supporting loads and stores. On the A78 (and now on the Neoverse V1), Arm added a new dedicated load AGU, allowing for up to 3 loads per cycle (or any other combination such as 1 load and 2 stores). As with the A78, along with the AGU addition, Arm also doubled the store-data bandwidth to 32 bytes per cycle.
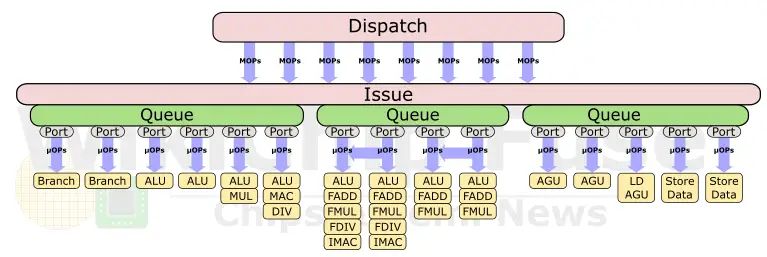
As far as load data bandwidth goes. The Neoverse V1 now enables a load bandwidth of up to 48B/cycle (3x16B) for integer operations and for floating-point and vector, the V1 now supports up to 64B/cycle (2x32B). Both the load and store buffers window sizes have been increased accordingly.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–