
Arm Launches The DSU-110 For New Armv9 CPU Clusters

Today Arm is introducing a broad range of client IPs including a new little Armv9 CPU, a new big Armv9 CPU, a new flagship performance Armv9 CPU, and new Mali GPUs. But to fully take advantage of the new cores, a new cluster must be designed to better interface between the new IPs. Arm’s new DSU-110 was designed for this very purpose.
This article is part of a series of articles covering Arm’s Tech Day 2021.
- Arm Unveils Next-Gen Armv9 Big Core: Cortex-A710
- Arm Unveils Next-Gen Armv9 Little Core: Cortex-A510
- Arm Launches Its New Flagship Performance Armv9 Core: Cortex-X2
- Arm Launches The DSU-110 For New Armv9 CPU Clusters
- Arm Launches New Coherent And SoC Interconnects: CI-700 & NI-700
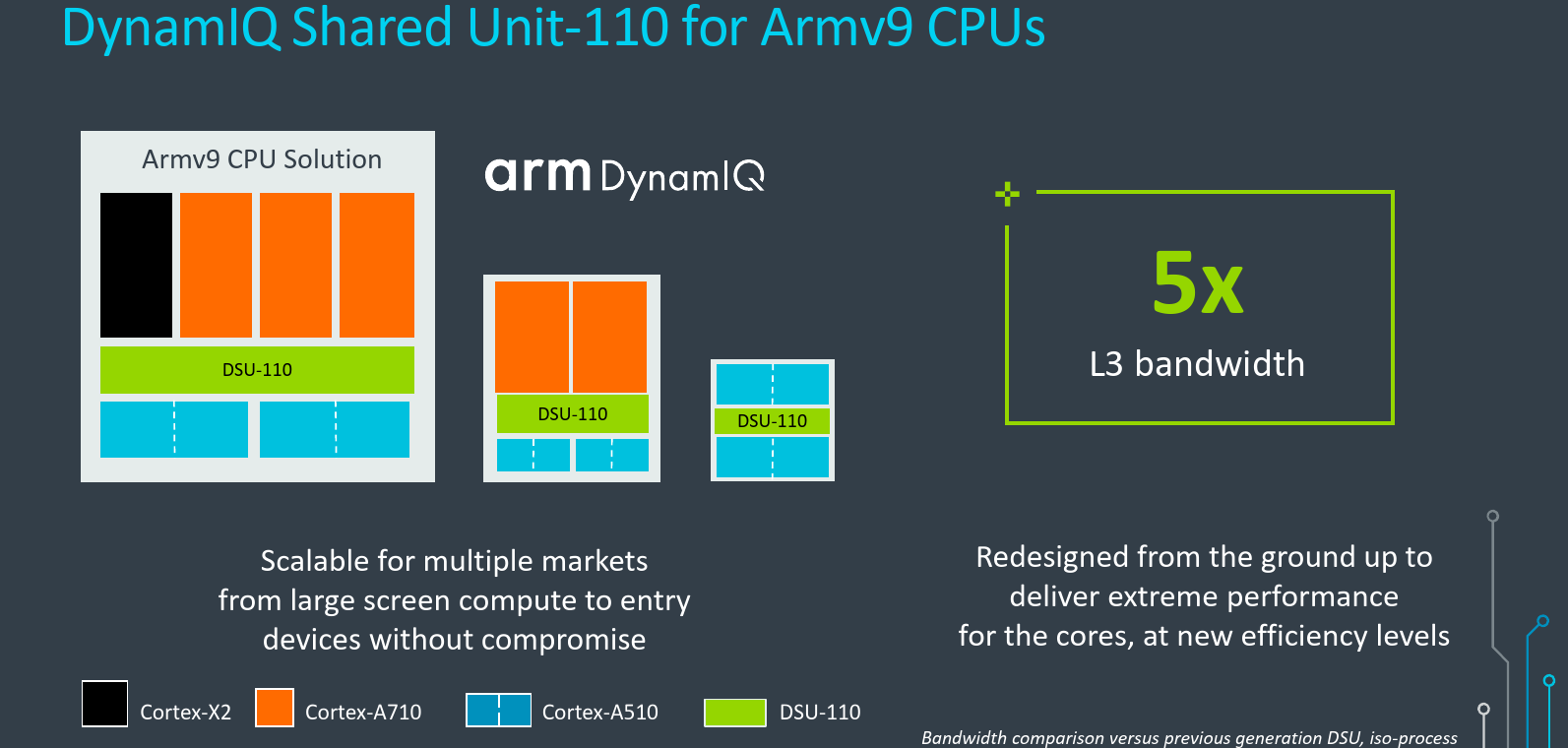
The new DynamIQ Shared Unit – 110 (DSU-110) has been redesigned from the ground up. Arm says that the new design ensures they can deliver a CPU cluster that scales to meet an increasingly diverse set of needs across multiple markets from the performance of laptops to the efficiency of wearables. There are a couple of major improvements in the new DSU including an up to 5x increase in the L3 bandwidth all while reducing the leakage power consumed to achieve better overall energy efficiency.
Performance Improvements
The performance of the new DSU came from a number of key improvements – the new cache architecture, the new interconnect, the new power management, and the new interfaces. On the cache side, the new DSU-110 supports large L3 cache sizes – up to 16 MiB as well as new intermediate sizes such as 6 MiB and 12 MiB. The larger L3 cache can really help the performance of many workloads, especially in environments where there are many highly active cores at once. A larger L3 cache can typically help reduce the amount of traffic to the DRAM which can further reduce the overall system power, an angle that, as you will see a little later, the DSU-110 exploits. Like the prior generation a single DSU cluster supports up to eight cores but with the new DSU-110, it’s now possible to instantiate eight Cortex-X2 cores in a single cluster, which although unlikely, still makes for an interesting configuration.
Compared to the prior DSU, the new microarchitecture has been designed to achieve higher frequencies. This enables lower latency and higher bandwidth. Alternatively, due to its higher frequency design point, it’s considerably easier to achieve similar lower frequencies as the prior generations at much lower power in a standard low-power implementation. This gives Arm partner the flexibility to optimize the DSU for their market requirements.
Depending on the exact configuration, the overall DSU bandwidth can be as much as 5x the L3 hit bandwidth as the previous DSU. Some of that bandwidth is a result of the higher frequency as we noted earlier, but Arm says that the majority of it came from the microarchitecture itself. The higher bandwidth is designed to allow the new cores to reach their target performance points.

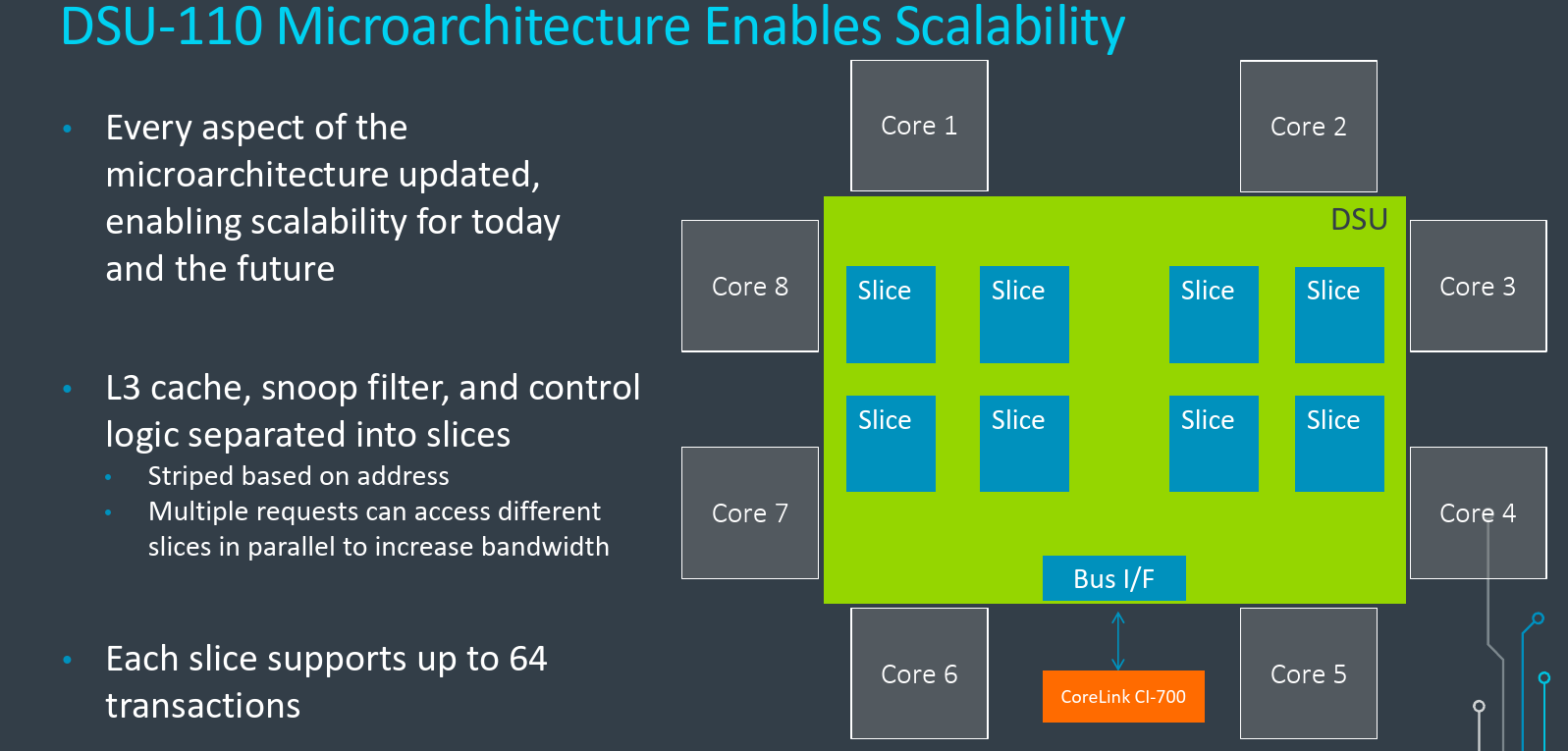
Cache Slices
To be able to accommodate the new cores and future cores, Arm went with a large amount of cache. But at the same time, they are looking to considerably increase the bandwidth which means a lot more simultaneous cache accesses taking place in parallel. Their solution was to split it up into slices. Each slice makes up a portion of the L3 cache, includes part of the snoop filter along with the associated control logic. The actual number of cache slices is configurable on the DSU-110 – with up to eight slices supported (as the number of cores). Depending on the bandwidth requirements and the market, Arm partners can choose to configure it to best suit their needs. During cache access from a core, the target cache slice is chosen based on the hash of the address. It’s, therefore, possible to make multiple requests that can resolve all the slices in parallel. In total, each slice supports up to 64 transactions in-flight at a time. That amounts up to 512 possible cache transactions happening in-flight at once for the entire cluster. A large number of transactions is particularly useful when a lot of memory accesses are missed in the L3 and there is a long wait from DRAM to respond.
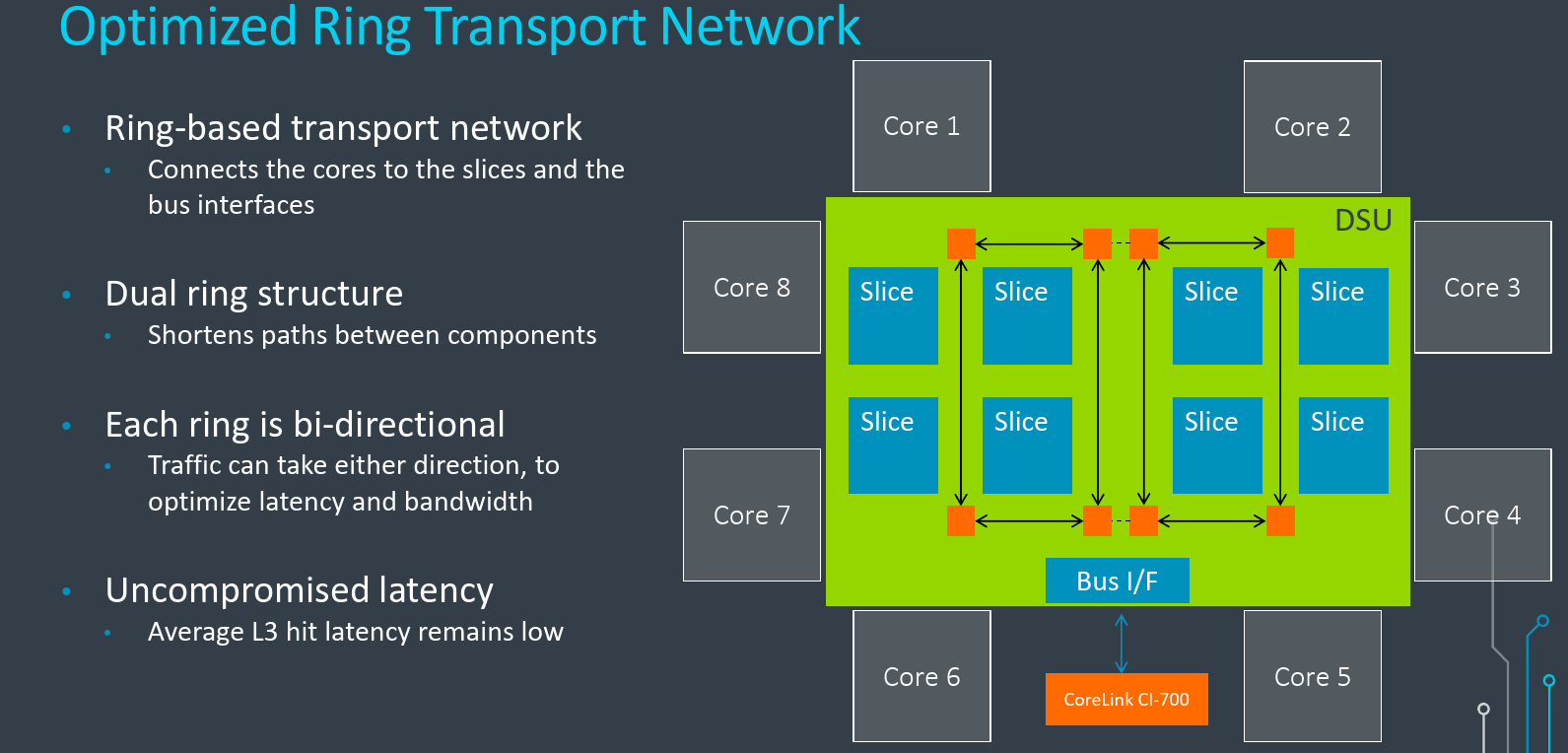
Internal Interconnects
With the larger cache support and a high number of transactions, the interconnect implementation in the DSU was designed to allow data to flow quickly within the cluster. On the previous DSU, Arm used a hybrid crossbar implementation. Addressing this, the new DSU-110 uses a ring-based transport network to connect the cores to the slices and to the bus interface. But interestingly, Arm discovered that a single traditional ring was insufficient to meet the performance targets they wanted. For that reason, the DSU-110 actually implements a dual-ring structure where two rings are connected in the middle. This has a couple of benefits. Firstly, it gives more possible paths that transactions can go through in parallel which increases the effective bandwidth. It also shortens some paths and helps reduce latency. The rings themselves are bidirectional. This allows traffic to choose the direction it takes in order to optimize latency as well as allow bandwidth in both directions. Despite all the cache and considerably higher bandwidth as well as the new interconnects, the latency on the DSU-110 is about the same as the previous DSU which had very low latencies, to begin with.
Zooming a little out of the DSU internals, the DSU does provide some additional connectivity required by the cores for the rest of the system. Depending on the memory demands of the cores and the specific application, the DSU supports a number of interface options. It can support up to a four-lane bus interface can be configured which allows for more bandwidth into the system. Each interface is 256b wide and supports the latest revision of the AMBA 5 Coherent Hub Interface (CHI) specification which supports the transport and coherency requirements of MTE. The DSU also supports the peripheral port which was further improved to give higher bandwidth and also adds coherency support. This enables new use cases such as being able to access the rest of the parts of the system, allowing the main interfaces to focus primarily on the DRAM traffic. This gives the system designer more opportunities for optimizing the path to DRAM for performance reasons.
Another interface that the DSU supports is the Accelerator Coherency Port (ACP) for accelerators. This allows tightly coupled accelerators for SoC designers that want the system components to be connected to the DSU and make use of the L3 cache. These interfaces have been enhanced to support more types of components including support for connecting the system MMU which Arm says enables better virtualization and improves security.
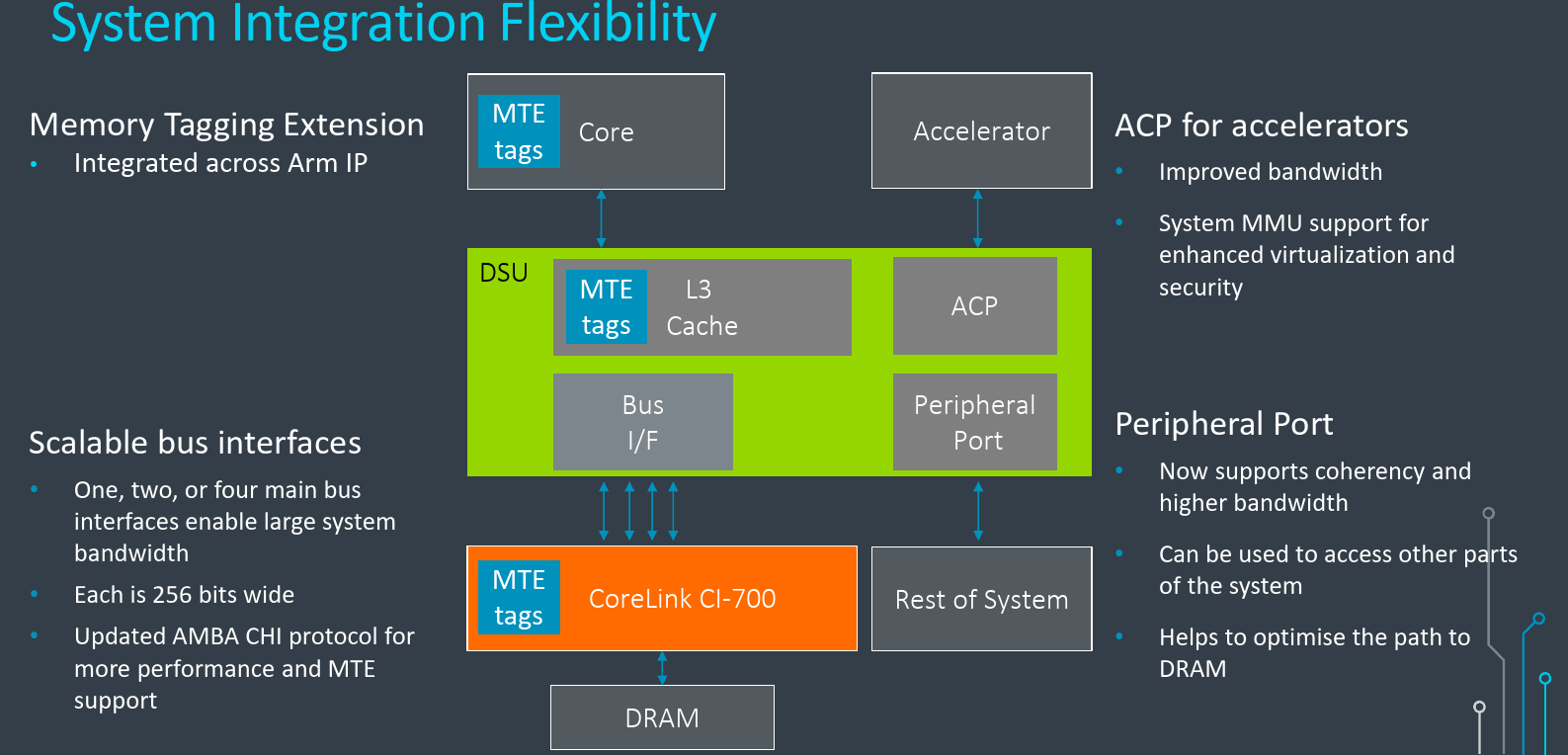
Memory Tagging
One of the big features that were introduced in Armv8.5 is the Memory Tagging Extension (MTE). With all the cores being introduced today supporting Armv9, they also support MTE. Like the cores, the DSU also supports the memory tagging extension because the feature actually spans across the entire system. Under MTE, tags must be stored and processed alongside the L3 cache as well as in the cores and even across the new CI-700 interconnect. All the components and protocols have been optimized to ensure they implement MTE as efficiently as possible. They do this by having a tags cache in the DSU as well which allows for the reduction of bandwidth through things such as memory coalescing.
Power Effiency and Performance
A lot of effort has gone into improving the energy efficiency of the new DSU-110 cluster. Arm also integrated advanced power control capabilities to allow Arm partners to more easily build advanced power management controls into their designs. The microarchitectural improvements that made it possible to reach higher operating frequencies also enable the DSU to operate at significantly lower leakage when fully active. For example, when the DSU is configured for the same number of cores and the same cache size and as well as the same process node as the previous generation, it consumes 25% less leakage power. But at the same time, in this configuration, it’s capable of delivering twice the bandwidth.
There are also plenty of occasions when only low-intensity tasks are running – such as background tasks when the device is idle or for example when the screen is off. In these cases, new power modes were added which can further reduce the power. Under one of those modes, the DSU is now capable of powering off the majority of the L3 RAMs, the snoop filter, and the associated logic. Just enough logic remains active for the background task to continue to run uninterrupted. In that mode, the leakage power is said to be reduced by 75% over the previous generation which directly translates to a longer battery life of devices.

`
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–