
Arm Unveils the Cortex-A78: When Less Is More

Last year Arm launched the Cortex-A77 and since then we’ve seen an initial wave of flagship processors based on that design including the Qualcomm Snapdragon 865, Samsung’s Exynos 980, and the Dimensity 1000. Continuing their their aggressive yearly cadence, today Arm is launching the Cortex-A78, formerly codenamed Hercules.
The Cortex-A78 succeeds the A77. Building on top of its two prior predecessors – the A76 and A77 – this Austin-based design further enhances the base microarchitecture in terms of both performance and power efficiency. However, unlike the prior two designs that saw significant beefing up of the pipeline and internal structures, Hercules sees an aggressive optimizations of the microarchitecture in order to maximize the power efficiency. At the end of the day, making everything bigger doesn’t necessarily strike the right balance in terms of performance, power, and area. Improving some structures yield better return on investment in terms of PPA than other. To that end, as you’ll see, the Arm team revisited the various components of the microprocessor, shrinking some buffers at times and enlarging others, in order to yield a better balance of performance and power.
‣ Arm Unveils the Cortex-A78: When Less Is More
‣ Arm Cortex-X1: The First From The Cortex-X Custom Program
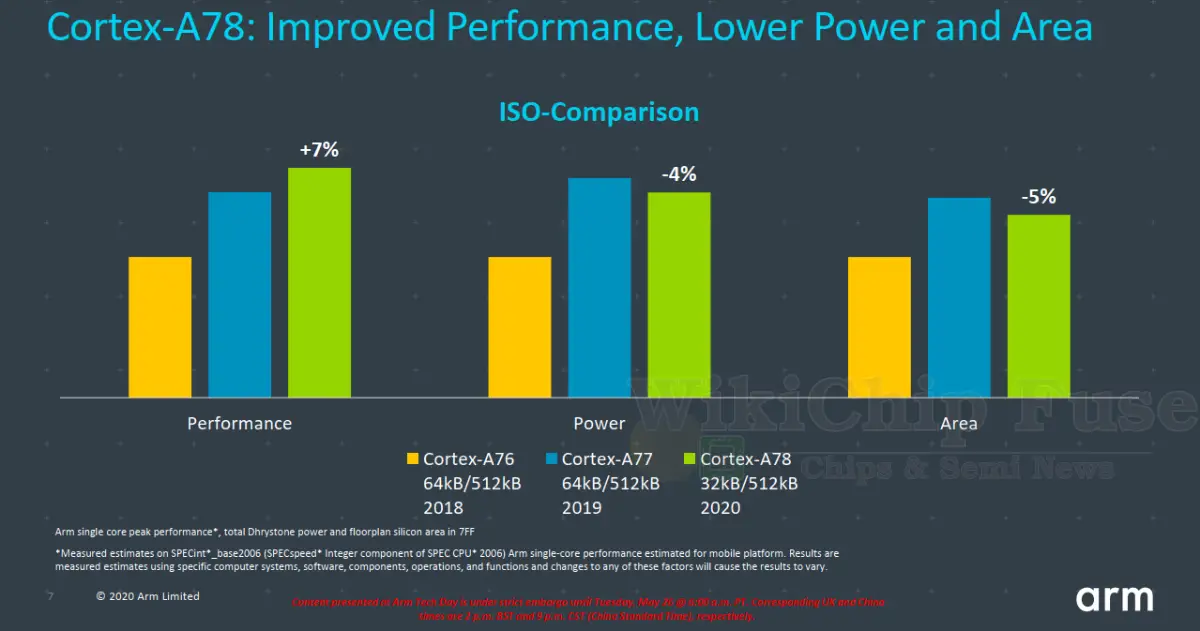
So what’s Arm offering with the Cortex-A78? Arm is promising a 20-percent uplift in sustained performance at the same power envelope. The comparison itself gets a bit more involved. Arm’s base comparison is at the same power envelope which is set at 1W/core. However, the comparison itself is a 20% uplift on 5-nanometer at 3 GHz while the A77 is on 7-nanometer at 2.6 GHz, so there’s a 15% difference in just frequency alone. The frequency points chosen by Arm may seem a bit off (especially given both cores can reach this frequency) but as you will see later on, they are actually result of picking points with comparable power levels.
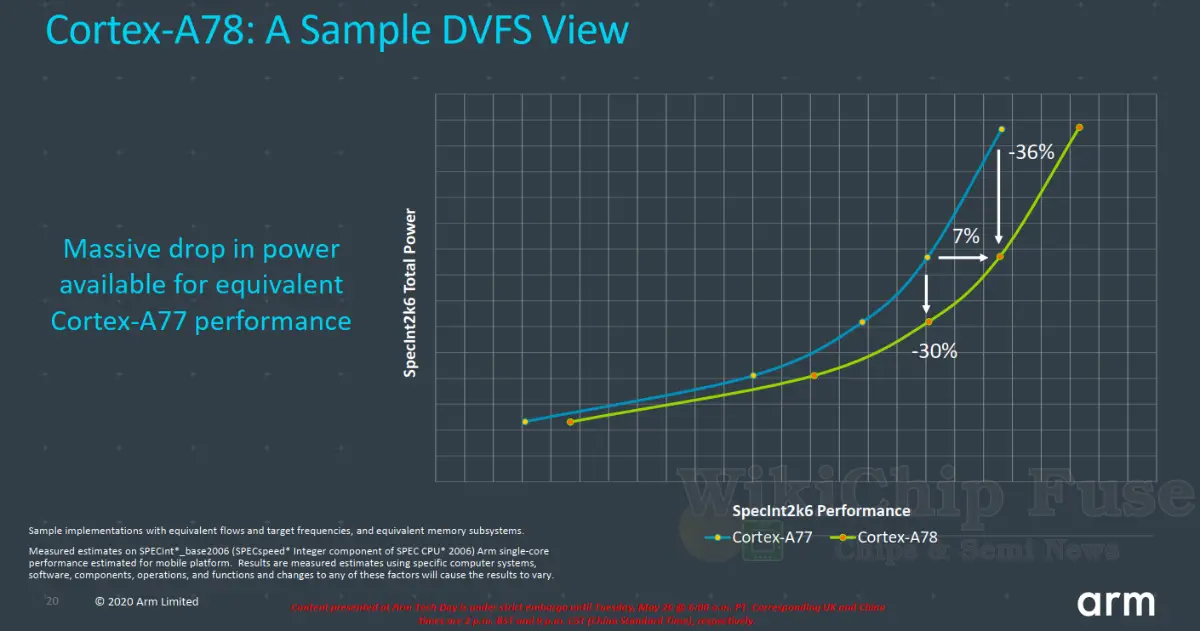
In terms of ISO-process and ISO-frequency, Arm is reporting a modest 7% improvement on SPECint 2006. If we turn the comparison the other way around, taking advantage of the 5-nanometer node along with the various architectural changes, the Cortex-A78 will enjoy as much as 50% reduction in power for the same performance level which was defined by Arm as a score of 30 on SPECint 2006. With the N5 node improving the voltage-frequency curve and with the A78 matching the A77 at 200 MHz lower for their chosen performance number, the reduction in power is quite significant. Here the N7 Cortex-A77 was clocked at 2.3 GHz vs the N5 2.1 GHz A78. Of course, Arm’s numbers are chosen to reflect their best positions. Actual smartphone SoCs will have numbers somewhere in the middle but this should give you an idea of what to expect.

Earlier we mentioned that both power and area efficiency improvements were a big part of this design. In an ISO-process comparison, we can see that the Cortex-A78 is roughly 5% smaller than the Cortex-A77. Although a large part of the power improvement found in the A78 came from targeting the 5-nanometer node, even in an ISO-process comparison Arm is reporting a 4% power improvement. Despite flagship processors moving the to the 5-nanometer node this year, even SoCs that lag behind will enjoy both power and area improvements on even older nodes by moving from Deimos to Hercules.
Pipeline Improvements
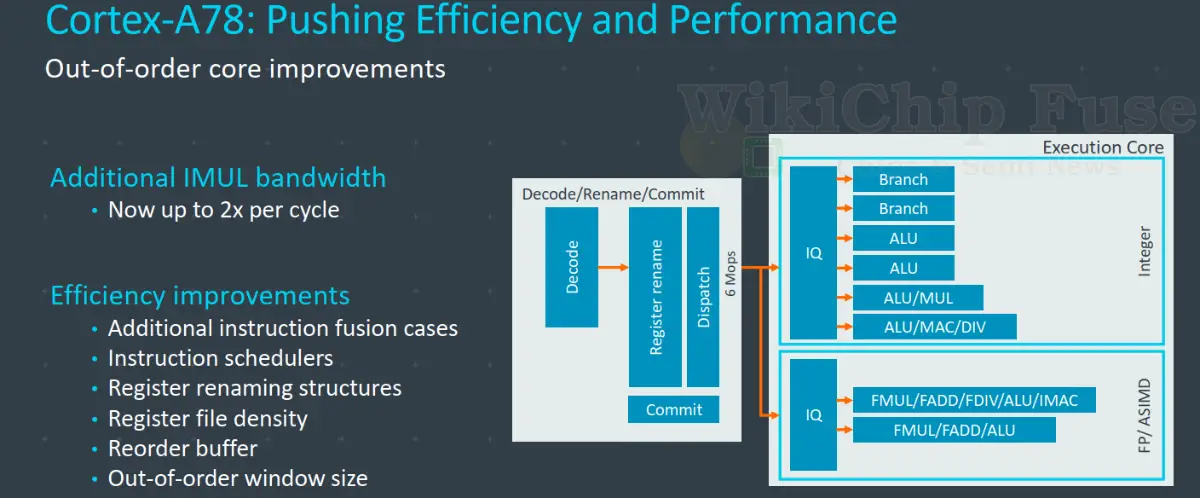
In the last two generation – the A76 and A77 – we’ve seen the Cortex cores grow in width, OoO capabilities, and frequency. Some components don’t quite grow with PPA as much as designers would like. With the A78, the Austin team revisited and scrutinized many of the buffers that grew in terms of power and area ROI. The result was that various structures could be comfortably shrunk without harming performance all while improving area and slightly improving power along the way.
The front-end of Hercules was kept largely the same. Up to 6 MOPs may be fetched from the pre-decoded MOP cache or up to 4 instructions may be fetched from the L1 cache and be decoded each cycle. In addition to the 64 KiB of cache that was offered in the A76 and A77, the A78 re-introduced the 32 KiB cache capacity, providing a modest improvement in both area and power for customers that want that trade-off. In fact, all of the performance numbers that we quoted earlier from Arm are based on the 32 KiB configuration. As we have come to expect, the branch predictor was said to be improved along with earlier prefetching for L1 cache misses.
One of the larger changes that were made to the branch predictor is in its bandwidth improvements. On the Cortex-A78, the BPU is now capable of predicting up to two taken branches per cycle, doubling the bandwidth from the prior generations. This change allows the fetch to start working on multiple instruction streams. The effect is that prefetchers can start working further ahead of time and for when a branch is taken, potentially absorbing some pipeline bubbles.

The focus of the changes in the back-end of the Cortex-A78 was predominantly driven by power and area efficiency rather than performance. Arm did add a second integer multiply unit to one of the simple ALU pipes. This double the throughput of integer multiplication to two multiplications per cycle. In the area of power and area efficiency there is a whole array of internal changes that have been made. Arm listed just a handful of them.
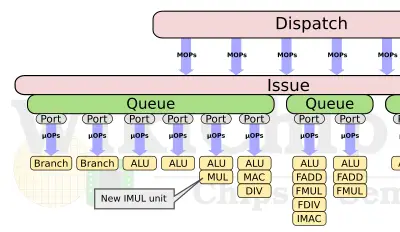
In terms of internal representation, Arm made the internal operations slightly more dense. Arm added more cases where instruction fusion can take place, replacing what would previously require two micro-ops now require just one. This has the effect of not only improving density and bandwidth but also power. Likewise with the register renaming structures on the A78, Arm says it has improved the some of the internal algorithms. For various register files in the core, Arm says it has implemented a new register packaging scheme, improving the data density. This applies to both the physical register files as well as the reorder buffer. Finally, the A78 shrunk the out-of-order window size slightly. On the A77 the ROB size was 160-entry deep which was the largest ROB size of any core made to date. The A78, in tandem with some of the other changes, was said to have shrunk slightly, striking a better power/area balance.
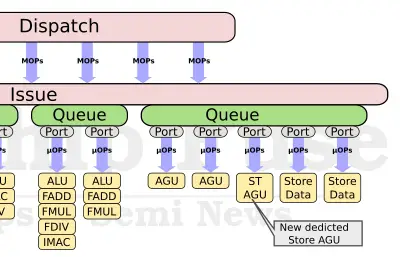
On the memory subsystem front, the A78 improved the bandwidth in various area. Previously, there were two generic AGUs – both supporting loads and stores. On the A78, Arm added a new dedicted load AGU, allowing for up to 3 loads per cycle (or any other combination such as 1 load and 2 stores). Along with the AGU addition, Arm also doubled the store-data bandwidth to 32 bytes per cycle.
On the cache side of things, the A78 continued to improve the data prefetchers. A number of new prefetcher engines were introduced to support new stride patterns as well as some new irregular access patterns. As with the instruction cache, the data cache now comes in both 32 KiB and 64 KiB configuration for implementations that want that extra area/power improvement compromise.

Putting it all together
Every once in a while following a number of generations, designers have to look back at some of the long-term modifications that have been made and scrutinize them in terms of the performance benefits that they delivered versus the area and power costs. The Cortex-A78 was that generation. Optimizing for efficiency was the primary goal and that came from pruning some structures that were simply too big. The end result is a design that’s slimmer and more power efficient while retraining similar performance.
In the slide below, the an internal implementation of the A78 is shown compared to the A77. This is an ISO-process graph implemented using equivalent flows and target frequencies. The graph plots the SpecInt 2006 total power for various performance levels across various voltage-frequency points. For the same levels of performance (on SpecInt 2006), moving from the A77 to the A78 yield fairly significant improvement in power.
Earlier in this article we presented some of the performance numbers that Arm reported for the new core. When Arm compared the A77 to the A78 they showed a 2.6 GHz A77 versus a 3 GHz A78. In reality, both cores are capable of reaching 3 GHz. Therefore, one could make the argument that really the A78 is only delivering about a 7% performance improvement. However, in actual shipping silicon (such as the 865 or the Exynos 980), we have not seen such high frequencies. In fact, 2.2-2.4 GHz seems to be the norm. The 865 has a single ‘prime core’ that can reach a hair over 2.8 GHz. The efficiency improvements that have been made in the A78 – along with process improvement – should allow for higher frequency in next-generation smartphone and mobile SoCs, thereby delivering higher sustained performance.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–