
Arm’s New Cortex-M55 Breathes Helium
There is an incredibly broad range of machine learning workloads out there. Adding to this revolution is the growing set of hardware that’s used to execute those workloads. In addition to traditional DSPs, and more recently, specialized accelerators, there is an ever-growing number of customers that are using CPUs for processing of ML. In the embedded and microcontroller world, these CPUs are often the Arm Cortex-M series.
Even though Cortex-M cores are being adopted for machine learning, existing cores are not particularly good at that. To add to this, they are still based on the older ARMv7-M architecture. Much of that changed when Arm introduced the Cortex-M55 earlier this year. The M55 is a bit unusual in that although intended to succeed the Cortex-M4 and M7, it does not directly replace either. It does offer enough new features and enhancements to entice chip designs that are interested in leveraging their Cortex M for machine learning applications. To see why this is we have to delve deeper into the new Cortex-M55 architecture.
As usual, you can find the full WikiChip Cortex-M55 microarchitecture page below.
![]() – Cortex-M55 – Microarchitectures – WikiChip
– Cortex-M55 – Microarchitectures – WikiChip
Arm already has a vector extension called Neon which is used extensively in all recent Cortex-A cores. The major issue with that extension is the power and area requirements. Neon would also necessitate a larger register file which in turn adversely affects other mechanisms of the microarchitecture such as the short interrupt latencies. These were the major motivations for a new vector extension called Helium (MVE).
Helium – a noble gas lighter than Neon – is a brand new SIMD instruction set extension designed for the Cortex-M series of processors. The extension offers over 150 new instructions, slightly over 130 of them being vector instructions. Helium features 8 vector registers, each being 128-bit wide. In order to maximize the area re-use, each of the eight vector registers is mapped directly over four FPU registers. The extension offers both integer and floating-point support, offering 8, 16, and 32-bit integer operations as well as half, single, and double-precision floating-point operations. Both 8-bit integer and half-precision floating-point data types are new to the Cortex-M world. It’s also worth pointing out that the Helium instructions set comes in two flavors MVE-I and MVE-F for integer and floating-point instructions respectively. It’s possible to implement just the MVE-I portion of the extension without the MVE-F instructions.

At a high level, the Cortex-M55 is an ARMv8.1-M compliant core with a 4-stage in-order scalar pipeline. In addition to the new Helium ISA support, this core also introduces the new coprocessor interface and is the first core to bring the custom Arm instructions support, albeit this won’t land until 2021. From an evolutionary point of view, the M55 borrows elements from both the Cortes-M4 and M7, but doesn’t fully replace either. The longer pipeline allows the M55 to reach roughly 15% higher frequency over the M4, but comes short of what’s the M7 is capable of (having two additional stages). Technically speaking, the M55 is capable of decoding two adjacent 16-bit T16 instructions, but the rest of the pipeline is single-issue which is why Arm isn’t classifying the design as a superscalar. By comparison, the Cortex-M7 is a dual-issue design. Arm reported the core to deliver 4.2 CoreMark/MHz which would put it at about 25% higher than the M4 but about 20% lower than the M7.
The M55 is a fully configurable core. Configurations go beyond cache size and include both the FPU and the Helium extension support. Since Helium allows for only integer vector instructions or integer and floating-point, the M55 offers both options as a configuration. In total, there are six main major configurations – the base integer pipeline, integer and FPU support, and three additional configurations of Helium for integer, floating-point, or both. Without Helium support, the M55 only ends up offering the advantage of being an ARMv8 core.
| Cortex-M55 Configurations | ||||
|---|---|---|---|---|
| Config | Base | FPU | MVE-I | MVE-F |
| 1 | ✓ | |||
| 2 | ✓ | ✓ | ||
| 3 | ✓ | ✓ | ||
| 4 | ✓ | ✓ | ✓ | |
| 5 | ✓ | ✓ | ✓ | ✓ |
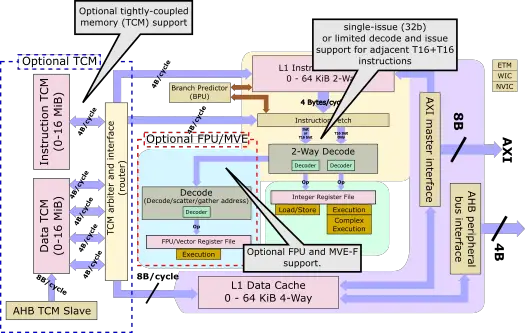
Helium defines 128-bit wide operations, but it also defines how they may be executed on a 32-bit, 64-bit, and 128-bit datapath systems should designers need to balance the tradeoffs of vector support with area and power. Internally, the M55 features a 64-bit datapath with 64-bit ALUs and matching 64-bit load/store operations. This means, with respect to Helium, the M55 is a dual-beat system. Helium has two concepts: a lane and a beat. A lane refers to the width of the operation while a beat is a quarter-vector-operation. Since a vector length is 128-bit wide, when working with 32-bit integers, a beat can be said to perform a single lane operation whereas when working with an 8-bit lane size, a beat can be said to perform a four-lane operation.
In a dual-beat system such as the M55, two beats are executed each cycle. A special architectural rule in Helium allows a dual-beat system to overlap beats. The M55 takes advantage of that feature with its dual-issue execution. What this allows programmers to do is overlap a 128-bit vector load operation with another 128-bit vector operation (such as a MAC in the slide below). This is common in various DSP-related algorithms such as filtering. When interleaving instructions like that, the M55 is capable of loading a 64-bit value while performing the MAC operation on the previously loaded 64-bit value at the same clock cycle, thereby sustaining both a 64-bit load and 64-bit MAC each cycle.
The Cortex-M55 has a 64-bit ALU. In terms of raw MAC performance, the Cortex-M55 can perform 2×32-bit, 4×16-bit, or 8×8-bit MACs/cycle. At 100 MHz you’re looking at 0.8 MOPS (Int8) or 3.2 MOPS (Int8) at 400 MHz.
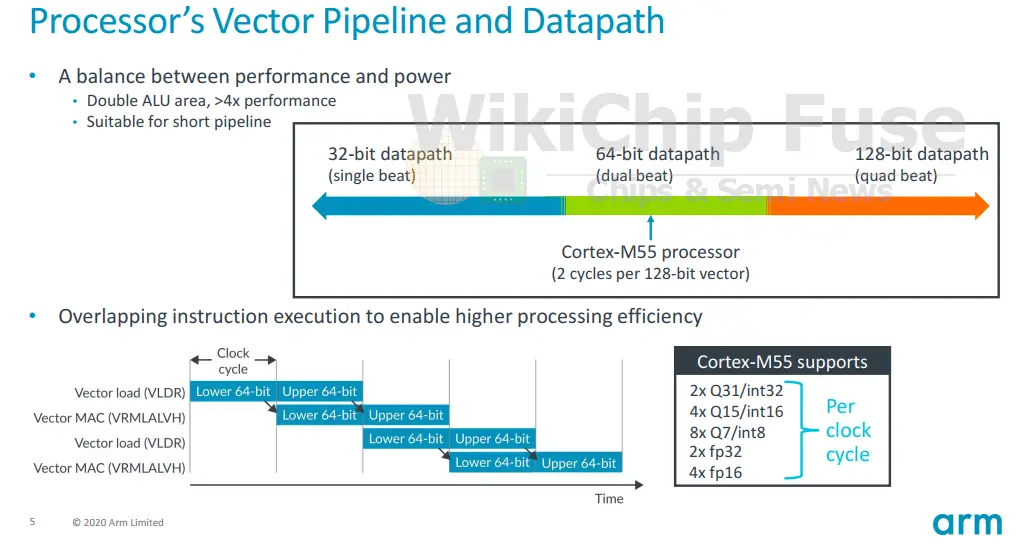
One area of the Cortex-M55 that borrows a lot from the Cortex-M7 is the memory subsystem. Like the M7, the new M55 features a two-level memory system. It has the level 1 general-purple caches along with the tightly-coupled memory blocks for real-time low latency applications. There is an optional private L1 data cache and instruction cache. Both caches can be configured from 0 to 64 KiB. Additionally, the Cortex-M55 can be configured with an instruction TCM and data TCM and both can be configured up to just about any realistic size needed, as much as 16 MiB (32 MiB for both combined).
Compared to the Cortex-M7, the interface to the I-TCM has been halved to 32-bit since the Cortex-M55 can only sustain an instruction fetch of 4B/cycle. Likewise, whereas the Cortex-M7 featured 2 32-bit interfaces to the D-TCM, the Cortex-M55 doubles this to 64-bit to accommodate the new 64-bit operations. It’s worth pointing out that in practice, the M55 core can only generate 64-bit of data traffic each cycle, therefore the other 64-bit links are really there to support the functionality of DMA operations that are independently transferring data from/to the TCM. In other words, with four 32-bit interfaces, the Cortex-M55 can simultaneously handle both 64-bit data transfers as a result of instruction execution and DMA-based 64-bit data transfers.
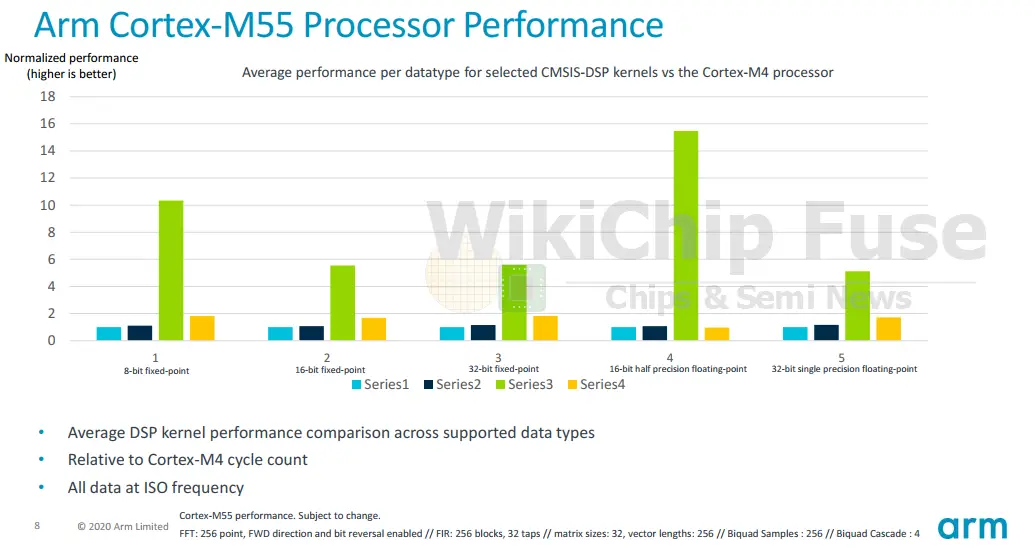
So what does all of this get you? For DSP and machine learning type of workloads, you’re looking at about 5x reduction in clock cycles for the popular algorithms. The graphs below compare the Cortex-M55 to the M4, M33, and M7 with performance normalized to the M4 which is still very popular today. The performance is for the DSP library collection of CMSIS with various kernels such as FIR, FFT, biquad filters, and matrix multiplications across various data types. The performance improvement is quite significant. One thing to note about the comparison is the incredibly high performance improvement for float16 and int-8 (about 16x and 11x respectively). This is a result of the two new data types being introduced on the Cortex-M series. Previously those two data types were not natively present.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–