
Arm Unveils Next-Gen Armv9 Little Core: Cortex-A510

It has been a long time since Arm launched a new little CPU. The Cortex-A55 was introduced just over four years ago, and since Arm has been doubling down on the big core performance with the launch of no less than four core – each launching on a yearly cadence – A75, A76, A77, and the A78. Today this changes with the introduction of the Cortex-A510, Arm’s new little CPU to go with their new A700 series big CPU.
This article is part of a series of articles covering Arm’s Tech Day 2021.
- Arm Unveils Next-Gen Armv9 Big Core: Cortex-A710
- Arm Unveils Next-Gen Armv9 Little Core: Cortex-A510
- Arm Launches Its New Flagship Performance Armv9 Core: Cortex-X2
- Arm Launches The DSU-110 For New Armv9 CPU Clusters
- Arm Launches New Coherent And SoC Interconnects: CI-700 & NI-700
An In-Order Machine?
There has been a lot of debate about what could the successor to the Cortex-A55 look like. One school of thought was that in order to push the performance further a light out-of-order pipeline might be required. In reality, what Arm chose to go with was another in-order design and the reason for it is simple. In-order pipelines are very very power efficient and for the little core, power efficiency is key.
The Cortex-A510 is a new ground-up in-order CPU design. The secret to its performance is in its instruction stream prediction and prefetching capabilities. The Cortex-A510 was specifically designed to deal with contemporary background, lightweight workloads. To that end, Arm designed a brand new in-order machine but leveraged their high-quality branch predictors and hardware prefetchers implementations from the Cortex-X series. Through the use of those aggressive components, a very well-fed in-order machine can have some pretty amazing performance results at incredibly low power envelop and smaller silicon areas.
To give a better sense of just how much of an improvement is possible. Consider the Cortex-A55 which was launched in 2017. At the time, Arm’s latest big core, the Cortex-A73, was just making its way to new smartphones. Fast forward to today, Arm is reporting some pretty impressive numbers. Comparing the new Cortex-A510 little core to 2017’s mainstream big core, the A73, Arm is claiming the A510 is actually within 10% on IPC, within 15% on frequency, and all of that while consuming 35% lower power. This is pretty impressive for the little core. It’s even more impressive when you consider that the new Cortex-A510 is just an in-order machine while the A73 was an 11-stage 2-wide decode 7-wide issue machine. It’s also worth noting that the new Cortex-A510 is far more extensive in its ISA support, implementing the new ARMv9 ISA whereas the A73 supported ARMv8.0.

Performance
Compared to the Cortex-A55, the new Cortex-A510 is a pretty big leap forward. In an ISO-process comparison, Arm says we can expect to see a 35% uplift in IPC along with 3x the ML performance through the new ISA and vector unit, all while having a 20% improvement in energy efficiency. Because of the fairly significant improvement in performance, the new Cortex-A510 can now cover a larger selection of workloads than its predecessor could. This means that there are now additional workloads that will no longer have to transition to the big core. This produces a better overall system efficiency and for mobile devices this means longer battery life. This is especially true with the A510 since the little core is almost ubiquitous in every Arm system regardless of the big core configuration and the device price range.

Microarchitecture
As we noted earlier, the new Cortex-A510 is still an in-order design. The area and power overhead of an out-of-order core did not make sense for Arm’s little core. At least not at this point. They stayed in an in-order design for a better overall energy efficiency and area utilization. There are a number of major differences from the Cortex-A55. For example, the pipeline width itself is now 50% wider – 3-wide from 2-wide in-order machine.
But the biggest attribution for the performance uplift is the selective leveraging of the big-core technologies. From the Cortex-X program, the little core Arm team borrowed the aggressive branch prediction and data prefetching. These high-performance high-quality components from the big cores reduce cache misses, eliminate gaps in the instruction stream, and ultimately ensure that the pipeline flows smoothly. Not only does it improve the performance of the L1 and L2 at lower area and power but ultimately this directly translates to a sizable uplift in performance.
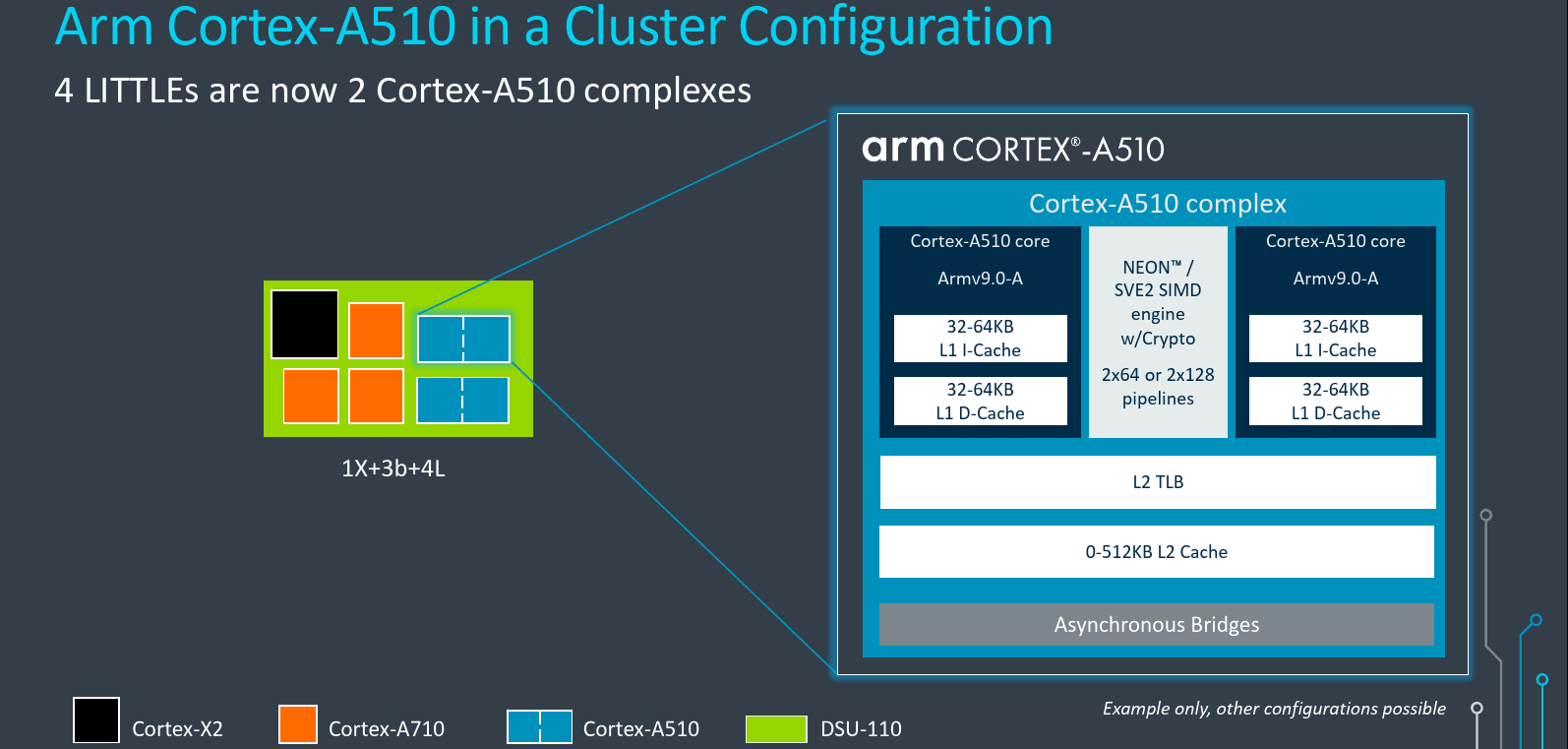
Merged Core Architecture: The Complex
The Cortex-A510 has some other interesting architectural changes. Arm is introducing a new merged core architecture for this generation. The benefit of this design is the introduction of ISA support along with new vector support including Scalable Vector Extension 2 (SVE2) all while doing so in a very area-efficient way. A key concept in the new Cortex-A510 is the “core complex”. A complex houses two interconnected cores. The complex can then be instantiated within a standard DSU cluster like any other core would. The only difference is that we are dealing with two cores at once in a single instance. For example, a high-end smartphone SoC might incorporate four little cores in two complexes along with 3 Cortex-A710 big cores along with a single Cortex-X2 core – all inside a single DSU cluster.
It’s worth noting that although most customers will likely use the Cortex-A510 in the new merged-core design, a single-core complex is still an option for Arm partners that want to expose the highest per-little-core performance at an ultra-low power at the cost of a bit more silicon area. The Cortex-A510 also comes with a wide range of configurations in this generation in order to cover a wider range of markets and offer greater scalability. Configurations include both complex type, cache sizes, and vector unit sizes.
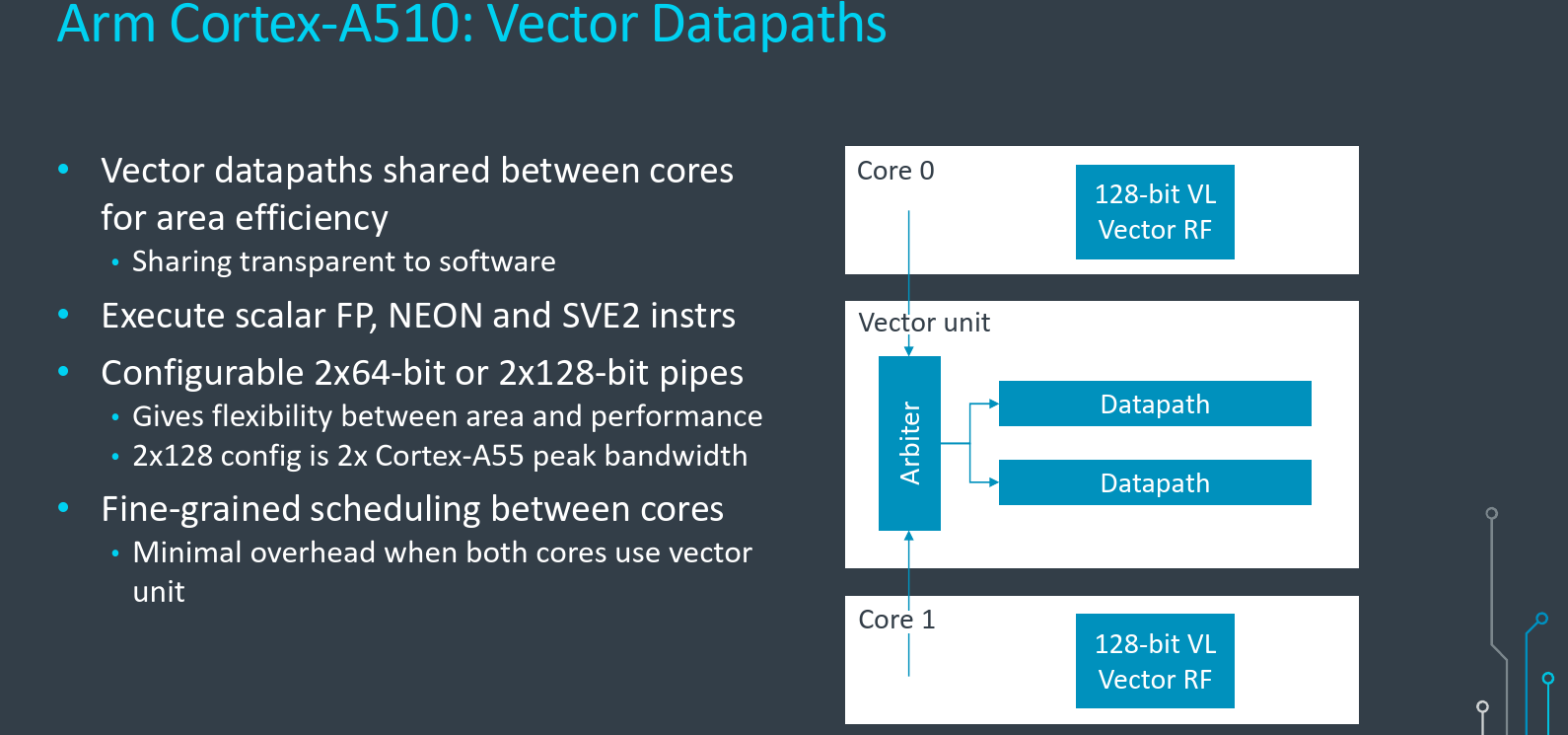
Within each complex is a level 2 cache, a level 2 TLB, a vector data path, and two Cortex-A510 CPUs. All three (the cache, TLB, and vector unit) are shared by the two cores but are otherwise private to the complex. For all practical purposes, the two cores are full individual cores – each with a dedicated level 1 memory subsystem, full fetch, decode, issue, and execute. The shared level 2 logic and the vector unit which we will discuss in more detail later on greatly increase the power efficiency and keeps the silicon area in check. The purpose of the share vector unit is similar. It allows Arm to maintain good peak performance without blowing up the area. While peak performance is very important, the reality is that utilization for the vector unit – especially on the little cores- is quite low. Therefore it’s possible to extract really good performance and area efficiency with the two cores sharing just a single vector data path.
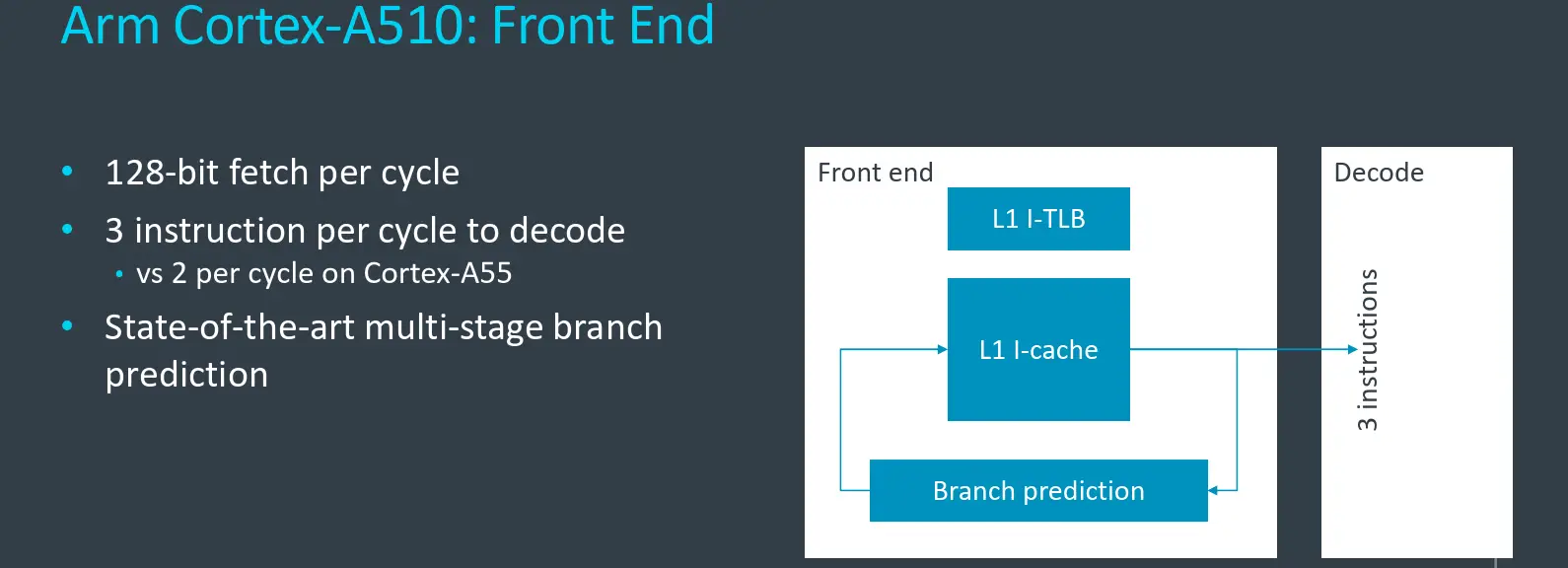
Front-End
Diving a bit deeper into the pipeline design itself. The new Cortex-A510 is a 3-wide in-order pipeline, making it 50% wider than the 2-wide Cortex-A55. To accommodate the wider pipeline, the fetch bandwidth was also increased accordingly. Previously, the Cortex-A55 could fetch 64b each cycle, extract two instructions from there, and send them to decode. On the A510, this was increased to 128b/cycle and the pipeline is now capable of extracting three instructions from there and send them for execution.
Although the pipeline is fairly simple, the performance improvements come from the aggressive high-quality branch prediction unit which was borrowed in large from the Cortex-X2 core. A better branch predictor accuracy means fewer gaps in the instructions stream due to lower mispredictions. This, in turn, means higher effective fetch bandwidth which ultimately means better performance.
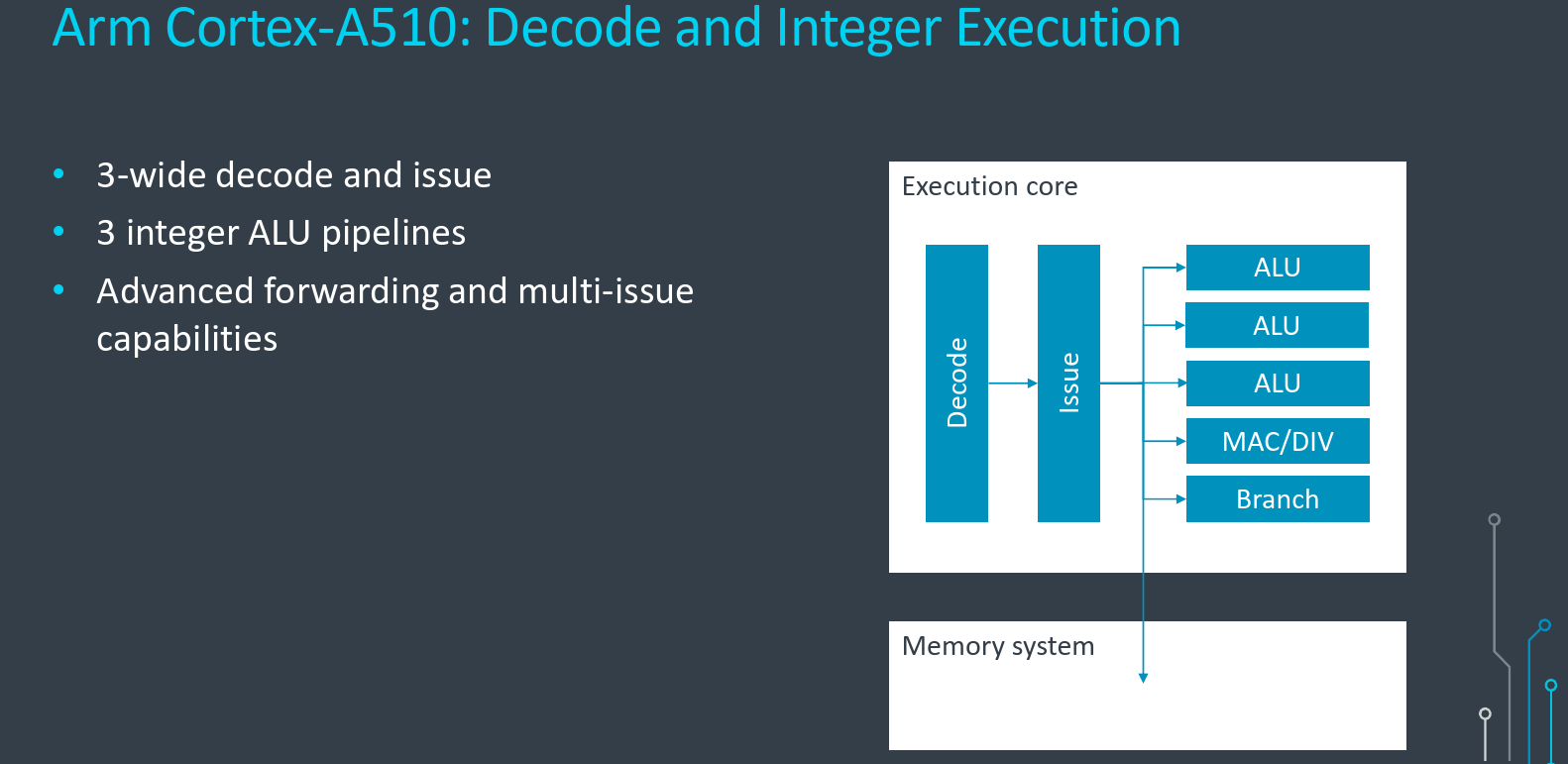
Decode and Execute
To match the widened fetch, the rest of the pipeline was also widened. To that end, The Cortex-A510 is now 3-wide decode, issue, and execute throughout. This is compared to the 2-wide/cycle on the Cortex-A55. On the execution side, Arm added a new third ALU pipeline to increase the bandwidth for workloads with densely packed ALU instructions. With a 3-wide issue, the A510 can issue up to three ALU instructions to the three pipelines each cycle.
A lot of work also went into the forwarding capabilities of the design and the multi-issue capabilities of the execution engines. This isn’t exactly something we can visually see in structure sizes or pipeline characteristics, but the A510 has special care to try to keep the execution bandwidth up in more cases while being less sensitive to specific instruction scheduling. Due to the inter-instruction dependencies nature in an in-order core, poorly scheduled code can create backups and significantly reduce the effective execution throughput. Arm also said that a lot of attention has gone into maximizing this concern while keeping everything in-order for maximum efficiency.
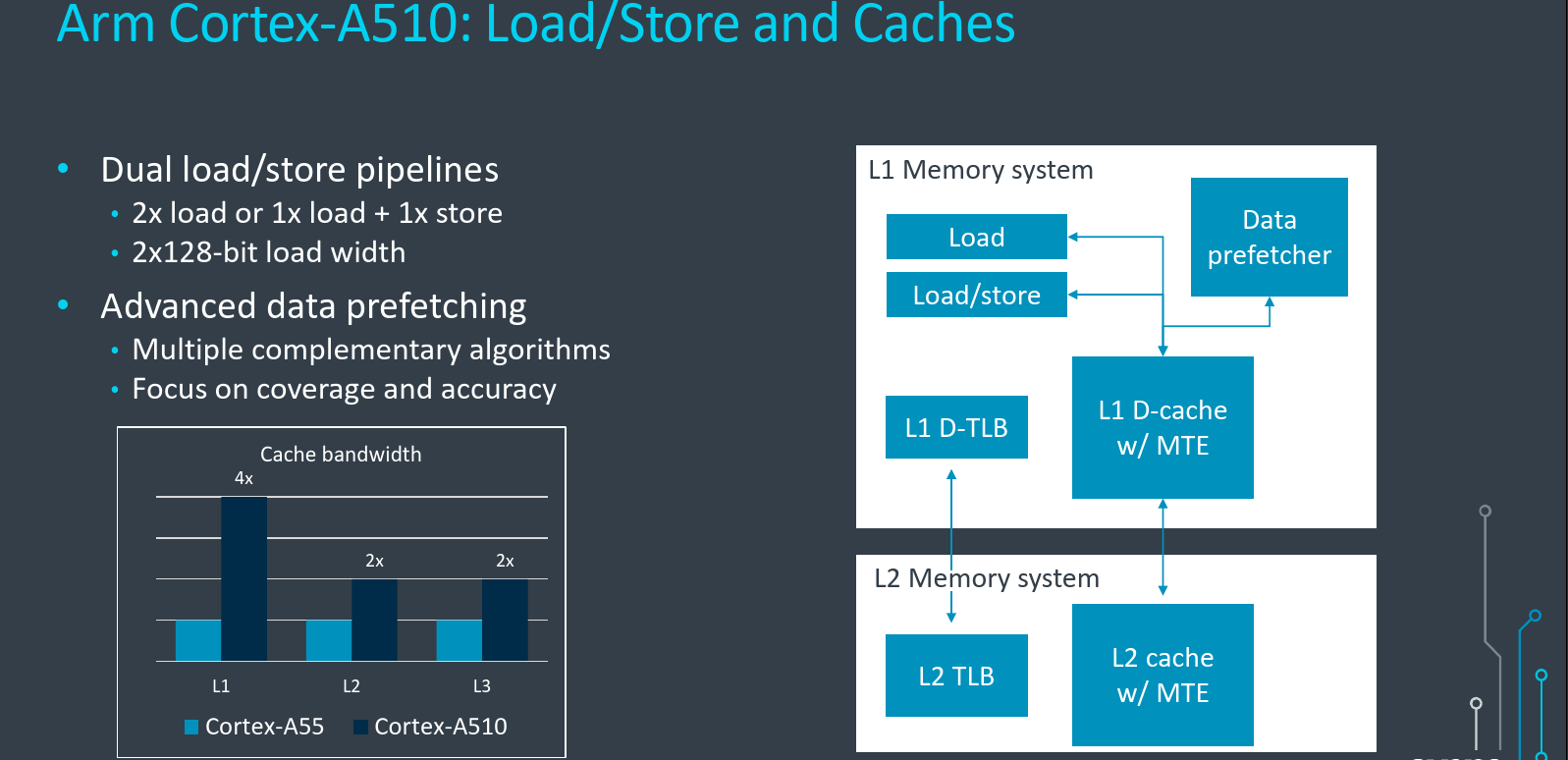
Memory Subsystem
Another big area of improvement on the Cortex-A510 is in the memory subsystem. On the Cortex-A55 there were two memory pipelines – one for load and one for store. There are still two pipelines on the Cortex-A510. But now, both pipelines are capable of executing load instructions. Therefore it’s now possible to support up to two loads per cycle or one load and one store. Not only that, but Arm also doubled the width of the data loads on the A510. Data loads are 128b-wide now, double the 64b-wide load sizes from the Cortex-A55. Moreover, since the new Cortex-A510 is capable of performing two loads each cycle, it’s now possible to perform 2x128b loads – or four times the peak L1 cache bandwidth compared to the A55. The bandwidth from the other caches was also doubled – the L2 and L3 bandwidths are doubled that of the Cortex-A55. The higher bandwidths throughout the machines allow the pipeline to have the instructions and data it needs to execute in order to reach their performance targets.
Data prefetching on the A510 also received special attention. Arm said that technologies that were originally developed for the cortex-X2 were carried over to the Cortex-A510 design. There are multiple complementary data prefetching algorithms implemented on the Cortex-A510. A lot of focus was put on making sure that the data needed is in the cache and that data that’s not really needed was not wastefully brought into the cache incorrectly. The data prefetchers’ quality significantly impacts the power efficiency of the core. They also typically managed to improve performance while reducing power with relatively high area efficiency.
Vector data path
The main motivation for the merged core design is the shared vector unit. Within a core complex, there is now a single vector pipeline which is shared by two cores. This helps boost the area efficiency while maintaining peak throughput on the datapaths. All scalar and floating-point NEON and SVE2 instructions are executed through the vector datapath. The vector unit is shared because the overall utilization of the unit is quite low in real-world workloads therefore it doesn’t make sense to expend twice the silicon area for discrete units for each core.
This datapath itself is configurable. Arm offers either having two 64b or two 128b data pipes – twice the peak bandwidth delta between them. It’s worth pointing out that the 2x128b configuration is effectively twice the Cortex-A55 peak bandwidth. This gives customers the flexibility in deciding between area and performance depending on their application. Regardless of the vector unit size or configuration, for SVE, there is a 128b vector register file.
Arbitration is completely hardware-based and execution sharing and utilization are entirely transparent to software. There is no user or OS-level software intervention for the arbitration of vector unit accesses between the cores. Furthermore, from a software perspective, each core appears to have dedicated access to the vector unit. Scheduling is very fine-grained between the cores to make sure there is minimal overhead caused by the sharing. Because of that there is no penalty for sharing or using the units. Arm says that they see very minimal performance overhead due to the share. Pointing out that in their own tests, on the SPECfp 2006 benchmark, they see around a 1% performance degradation if both cores are executing FP/vector instructions at the same time as they compete to use the vector datapath.
Performance
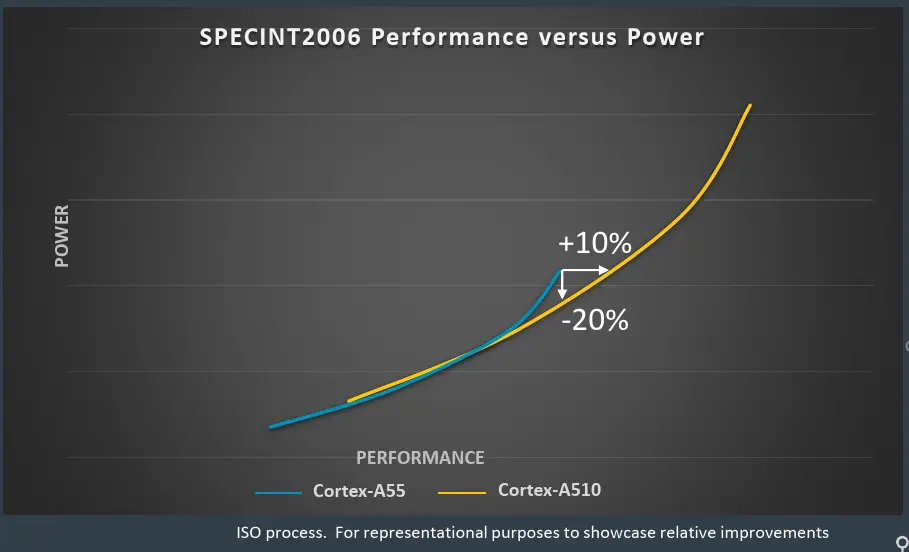
Below is a graph of the DVFS of power vs performance at ISO-process on SPECint 2006 for both the Cortex-A55 and the new Cortex-A510. At the peak operating point of the Cortex-A55, the Cortex-A510 is capable of reaching the same performance at 20% less energy. Alternatively, within the same power budget, the A510 achieves 10% higher performance.
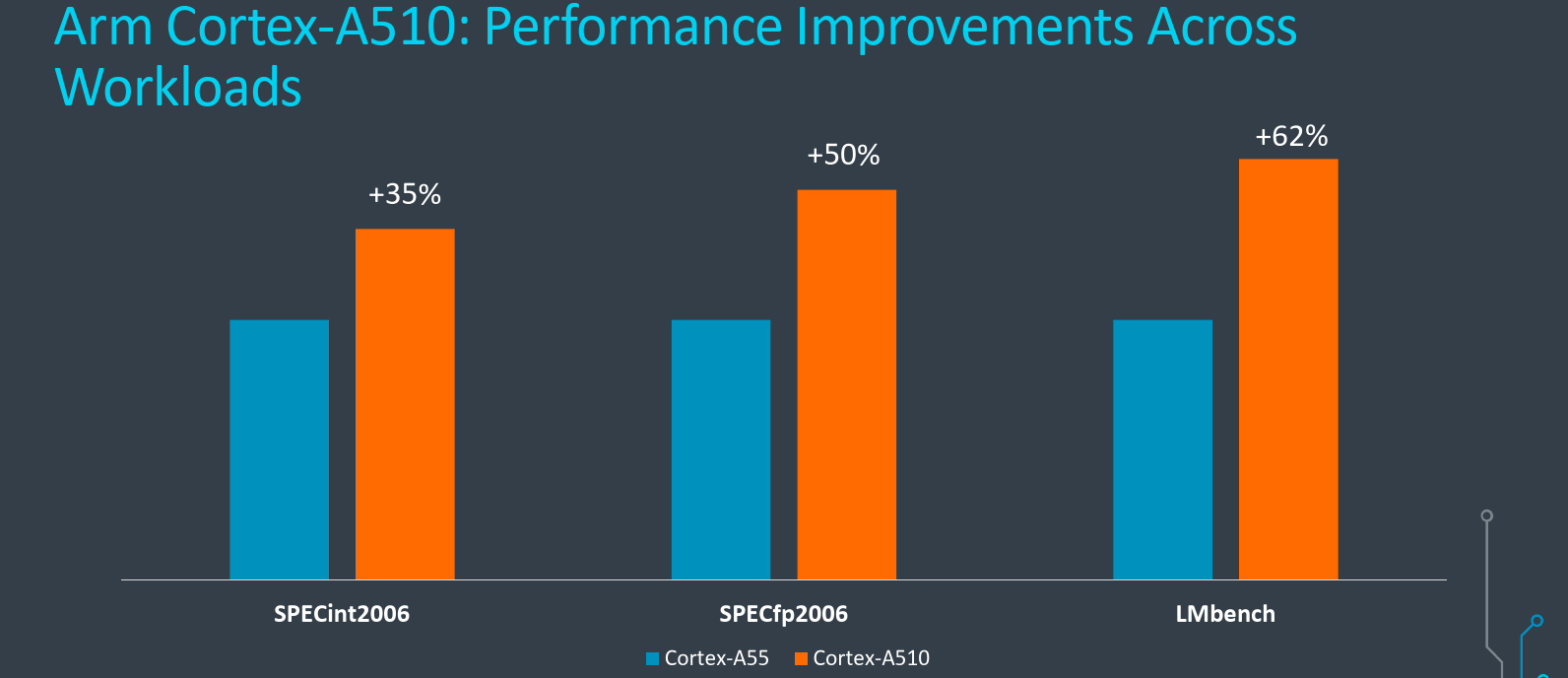
As far as IPC goes, Arm says that for the Cortex-A510, we can expect around a 35% improvement in IPC on the SPECint 2006 compared to the Cortex-A55. On the SPECfp 2006 benchmark, Arm claims to see an even higher performance improvement at around 50%.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–