
Samsung M5 Core Details Show Up
Earlier this year Samsung announced the Exynos 990. The chip features a much faster NPU, the latest G77 MP11 GPU, and LPDDR5. On the compute side, the chip features 8 cores – quad-core A55, dual-core A76, and the company’s latest custom CPU core design – the M5. In a late afternoon patch yesterday, Samsung committed the patch with some details of the new core in a new compiler scheduler model.
M5
The M5 is Samsung’s fifth-generation custom core developed by the Samsung Austin R&D Center (SARC). It’s also looking the last custom core developed there given the recent wave of layoffs and internal reorganization.
| Samsung Mongoose Microarchitectures | ||
|---|---|---|
| uArch | Process | Improvements |
| Exynos M1 | 14 nm (14LPP) | Large, Initial Design |
| Exynos M2 | 10 nm (10LPE) | Minor, Few larger buffers |
| Exynos M3 | 10 nm (10LPP) | Large, Wider Pipeline |
| Exynos M4 | 8 nm (8LPP) | Medium, Reorganized BE, Mem Subsys |
| Exynos M5 | 7 nm (7LPP) | Medium, Improved BE |
Samsung says that the M5 core delivers “up to 20% enhanced performance” so we might expect the average to be lower. Although the LLVM scheduler model is too high level to tell what all the smaller modifications that took place, we can see some of the bigger changes. From the LLVM patch, it’s hard to see much of the M5 performance coming from IPC improvements unless it’s coming from significantly improved prefetchers, branch predictors, or other similarly hidden components.
On the instruction set side, the M5 features the same ISA level as the M4 – Armv8.2-A. At a high level, the M5 is also quite similar to the M4 – the pipeline remains a 6-wide decode and back-end retains the same 228-entry deep reorder buffer. Samsung did increase the instruction queue slightly from 48 entries to 60. The bigger change is in the misprediction penalty which has been improved by one cycle, down to 15 cycles.
| Samsung M4 vs. M5 comparison | ||
|---|---|---|
| M4 | M5 | |
| Load-to-Use | 4 cycles | 4 cycles |
| ROB | 228 | 228 |
| Instruction Queue | 48 | 60 |
| Mispredict | 16 cycles | 15 cycles |
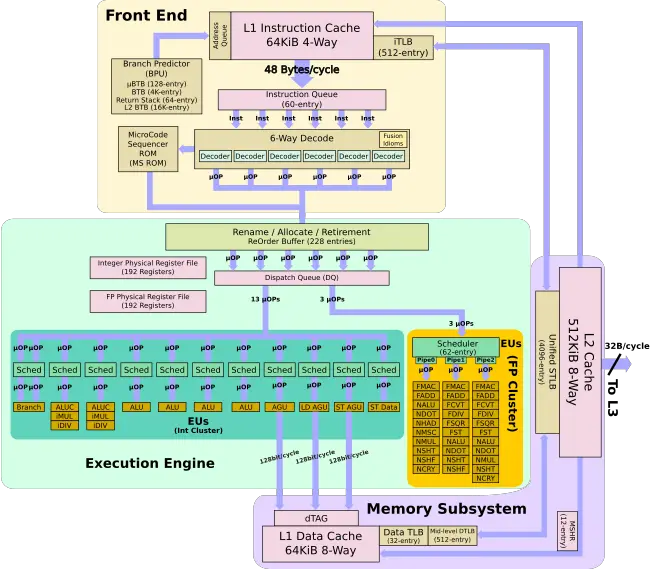
Back end
On the back end, Samsung added two new simple 32-bit integer ALU pipes. This brings the total number of integer pipes (branch included) to seven. The addition of two 32-bit ALU pipes is interesting since it won’t improve the throughput of typical simple ALU workloads.
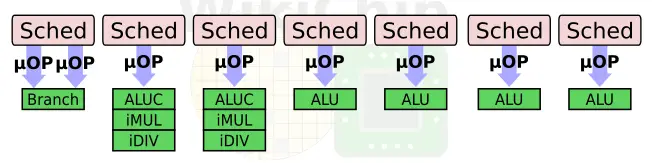
On the floating-point cluster side, Samsung rebalanced the execution pipes once again. The most notable change is the addition of the neon dot product execution unit on each of the three FP pipes. The addition of dedicated neon dot product units on each of the three floating-point pipes could help explain the 32b integer ALUs as well.
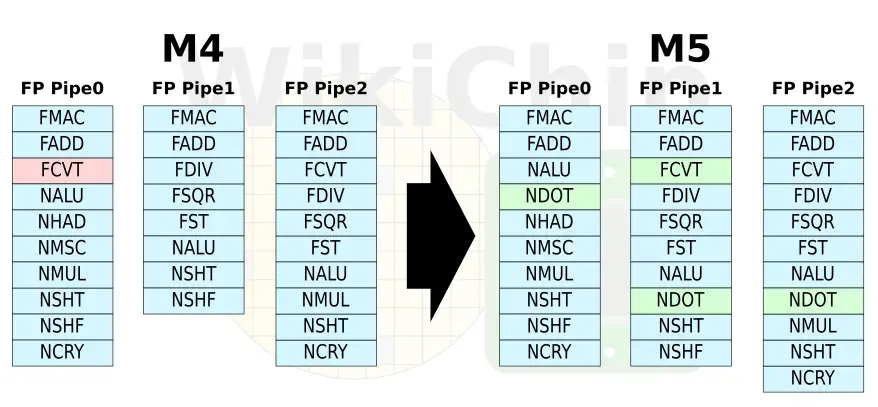
Shown above, Nxxx refers to NEON (advanced SIMD) units, where HAD = horizontal vector arithmetic, MSC = miscellanea, SHT = shift, SHF = shuffle, and CRY = cryptography.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–