
Arm Unveils Cortex-A77, Emphasizes Single-Thread Performance
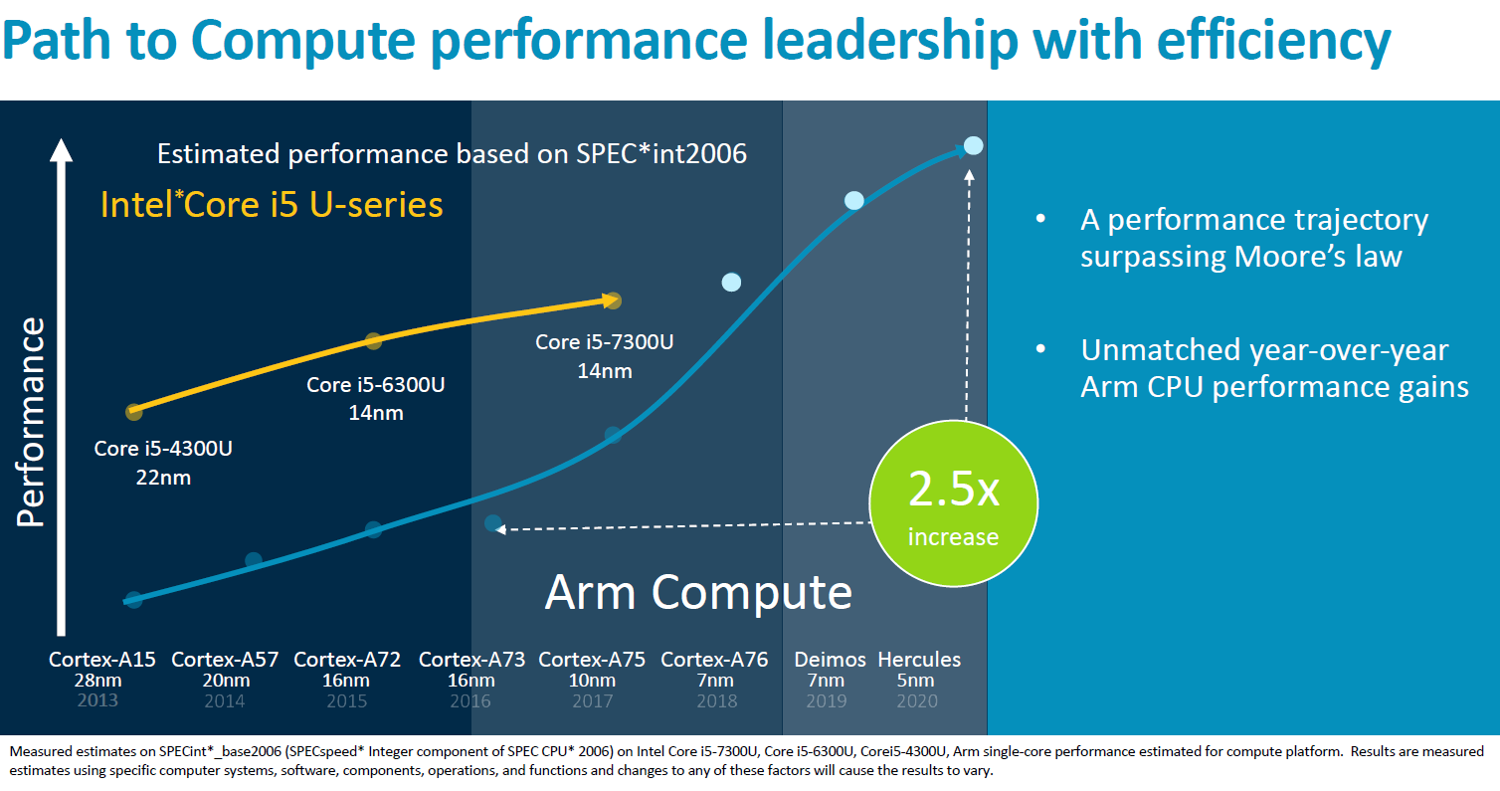
Last year Arm unveiled their aggressive client CPU roadmap through 2020. At the time, Arm promised to deliver a greater than 15% performance improvement year over year through 2020. We saw Arm delivering on their first core on their roadmap in early 2018 with Enyo which leveraged 7-nanometers to extract up to forty percent higher performance at similar power levels as the A75.

Cortex-A77
Today, Arm is back with a new announcement – the Cortex-A77. Deimos builds on Enyo by extensively enhancing the microarchitecture in many areas in order to extract a sizable amount of additional IPC while maintaining the same clock frequencies as the A76.
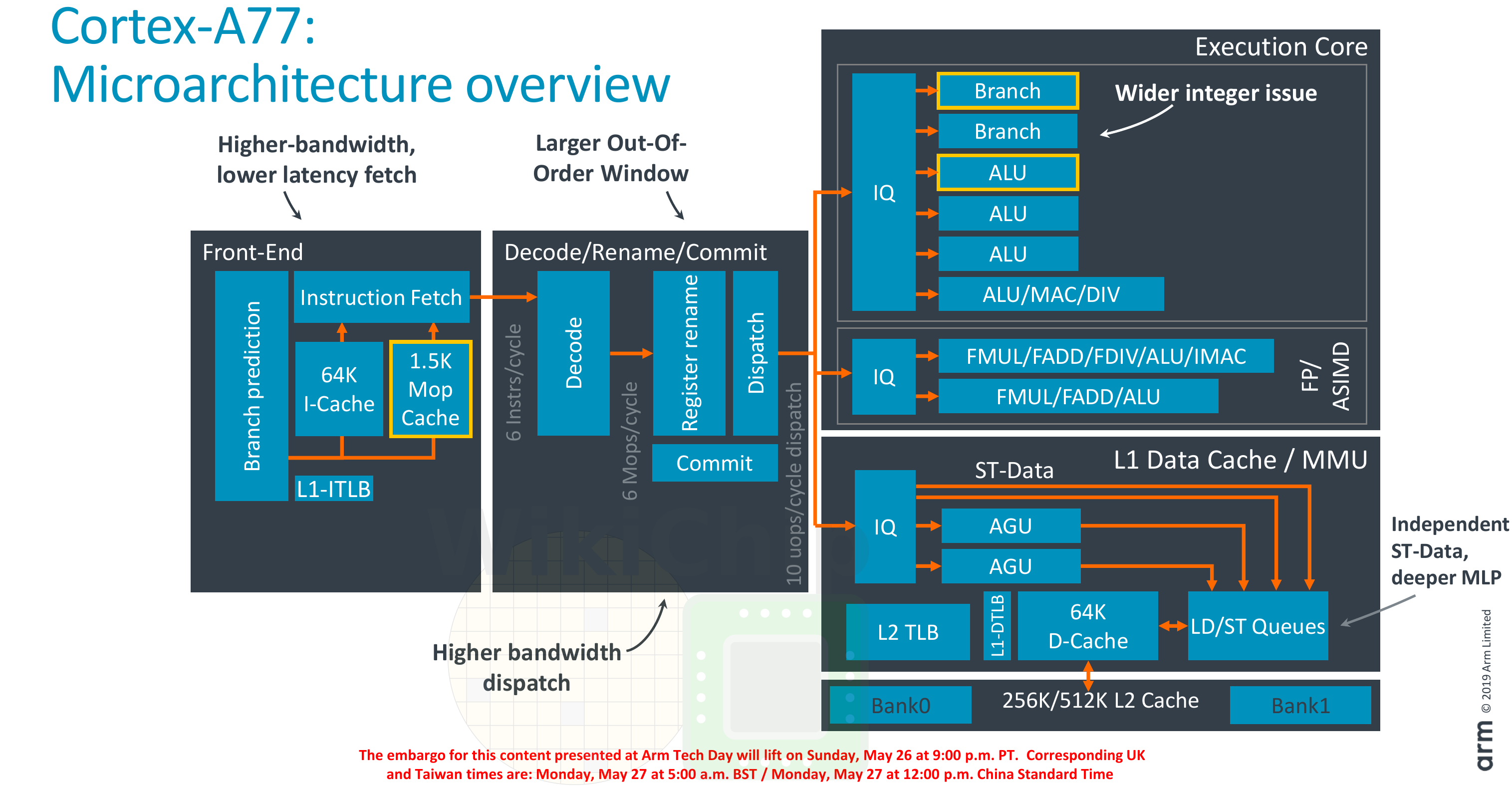
Architecturally, the A77 is quite similar to the A76. It’s now much wider with a few additional key enhancements. At a high level, this is still a thirteen-stage pipeline with a 64k instruction cache and 64k data cache along with a 256k or 512k (1/2 banks) of private L2.
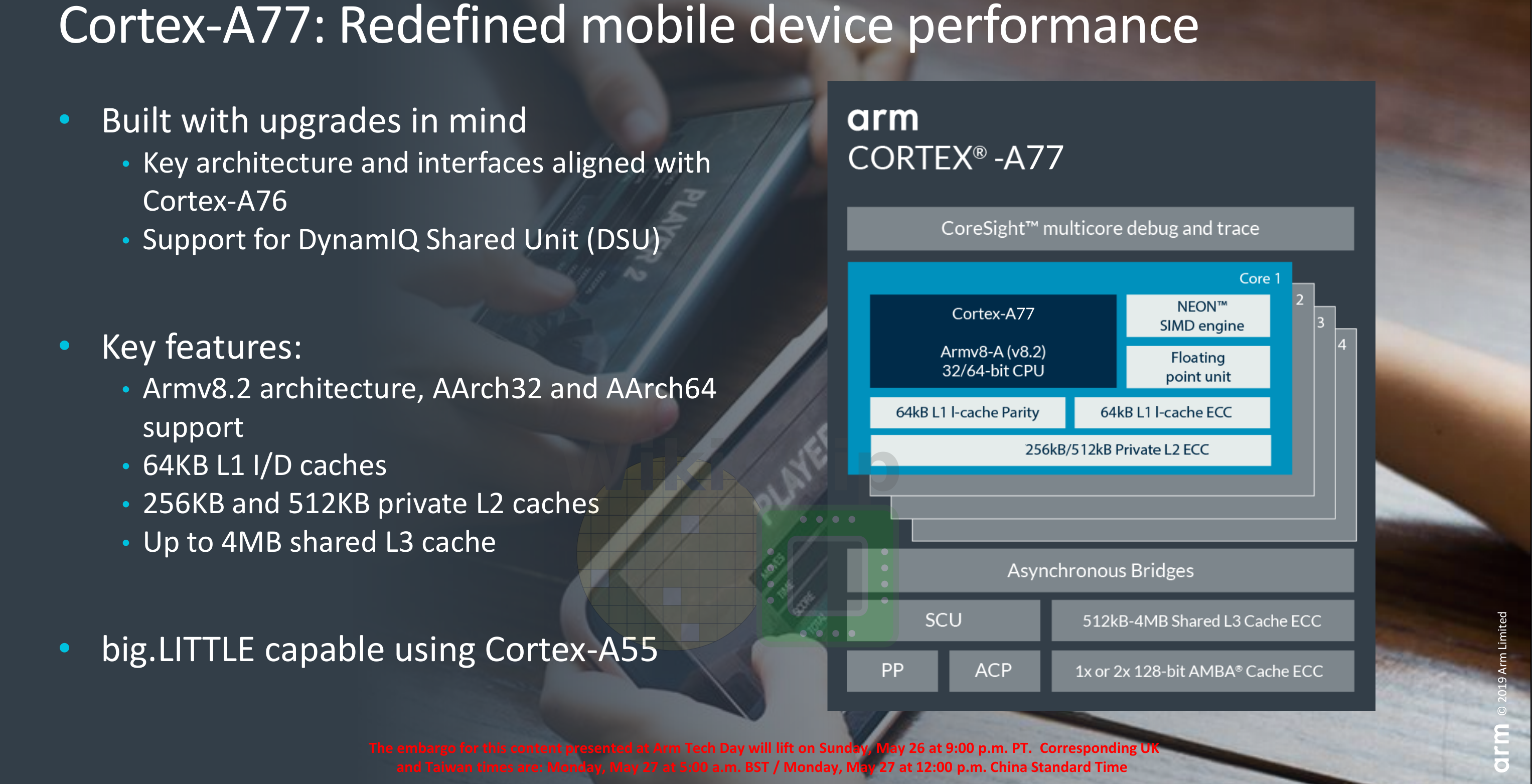
Deimos has support for DynamIQ Shared Unit (DSU) and is designed to be paired with other A77 cores or high-efficiency Cortex-A55 cores in a DynamiQ Cluster.
Performance Claims
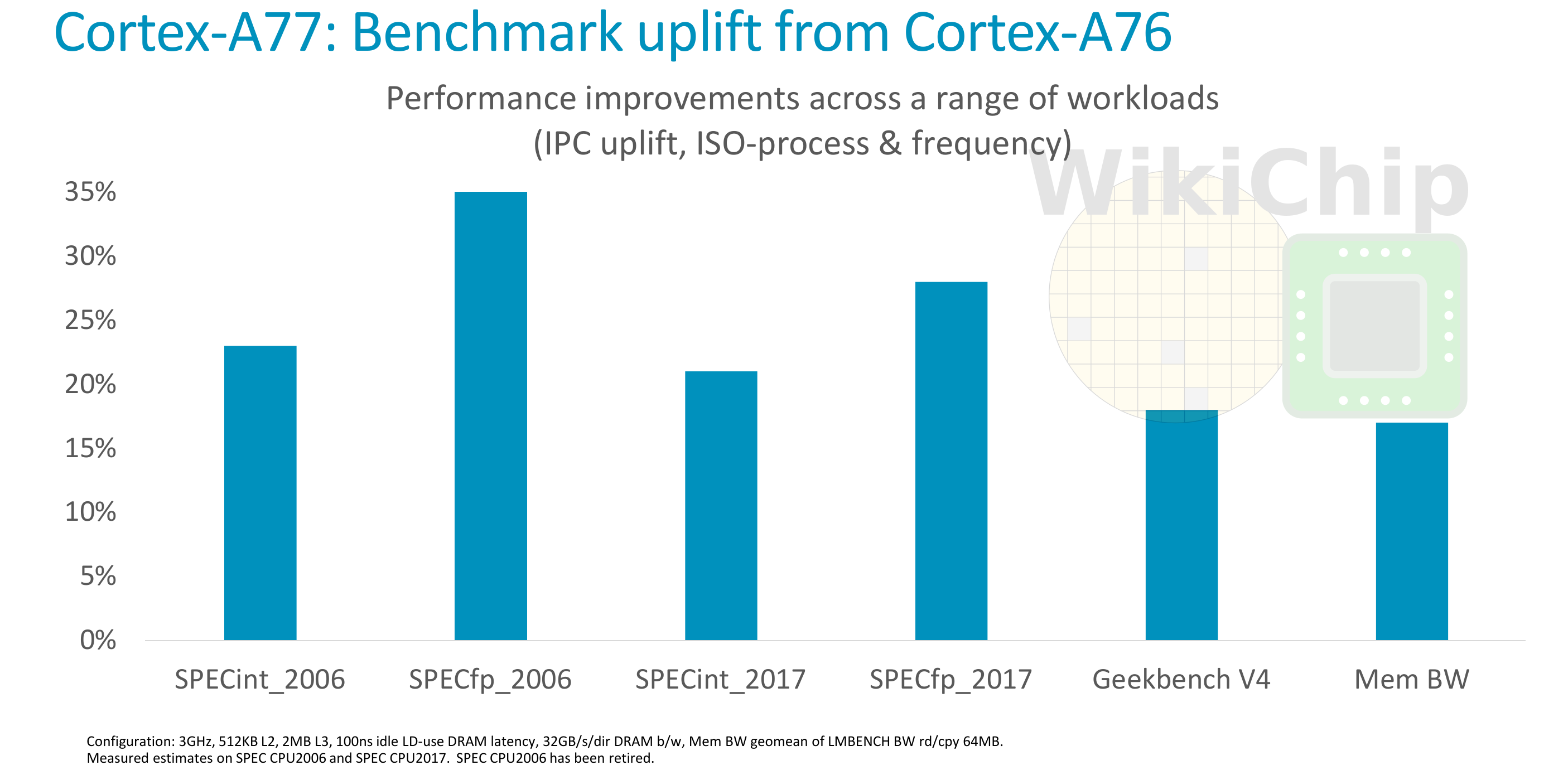
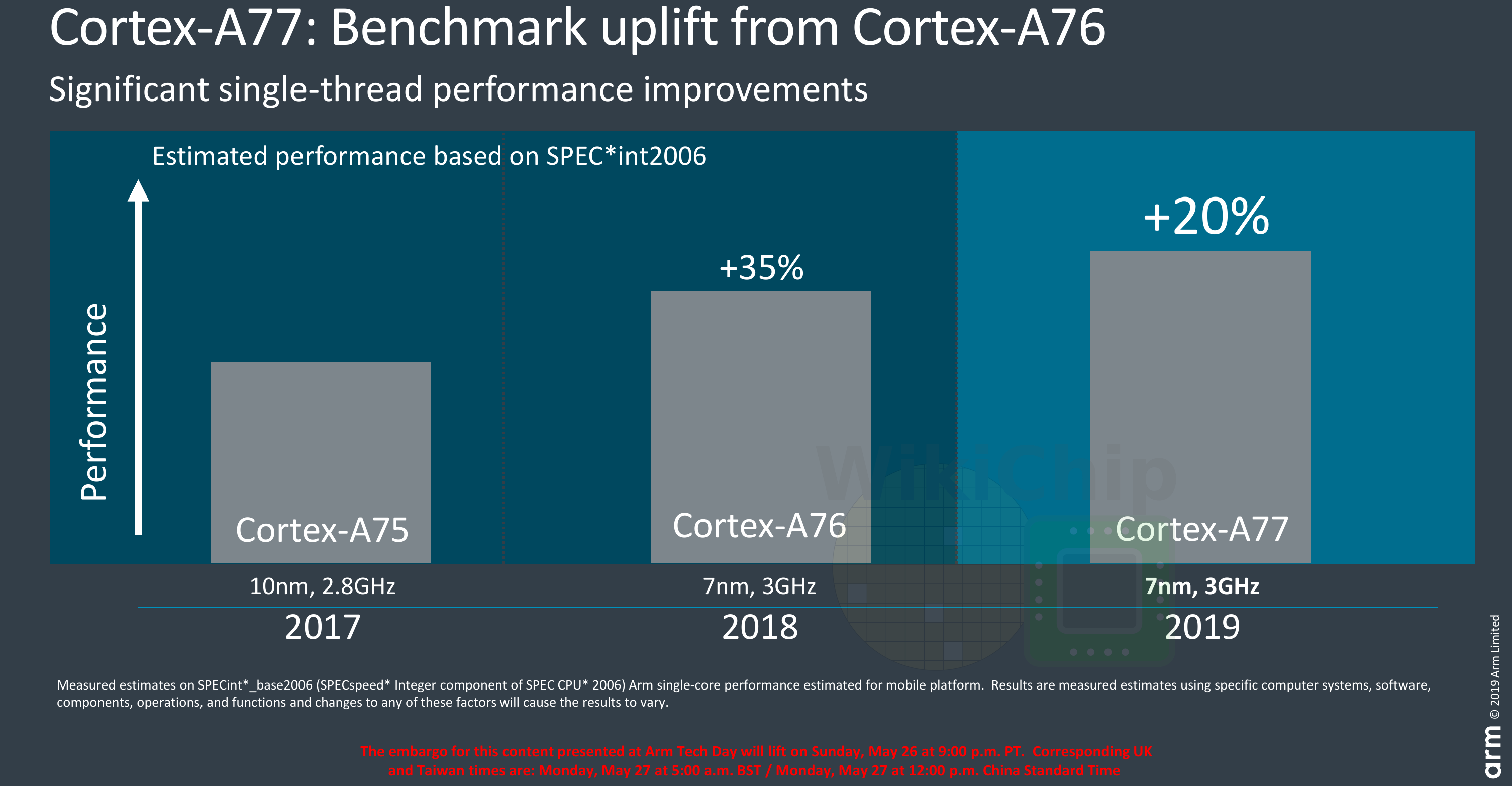
So what’s Arm claiming here? Compared to the Cortex-A76, Arm expects significant single-thread performance improvements. Across the popular representative performance proxy tests such as SPEC CPU2006 and CPU2017 as well as GB4, Arm is claiming around a 20% or better performance per clock. This is at ISO-process and frequency which in this case is compared at 3 GHz with a 512 KiB L2 and 2 MiB L3. Only actual independent benchmarking can verify their claims but in the last few generations, they had consistently exceeded their claims so we expect this to be no different.
Microarchitectural enhancements
So where is the performance coming from? It’s a combination of software optimizations as well as from a large number of microarchitectural enhancements that significantly widened the pipeline.
For the premium high-performance Cortex-A series, Arm has two competing designs. One design uses a split pipeline configuration whereby the pipeline is physically bifurcated into two pipelines. One pipeline is used for integer and data operations and a second pipeline is for the floating-point and the advanced SIMD operations. This approach can be found in the Cortex-A73 and the A75. The second design is a unified pipeline for all operations. This is the approach that can be found in the Cortex-A57, A72, and most recently in the A76. The Cortex-A77 builds on the A76 and therefore uses the unified pipeline approach.
For the full microarchitectural overview see the main WikiChip article on the Cortex-A77.
Front-end improvements
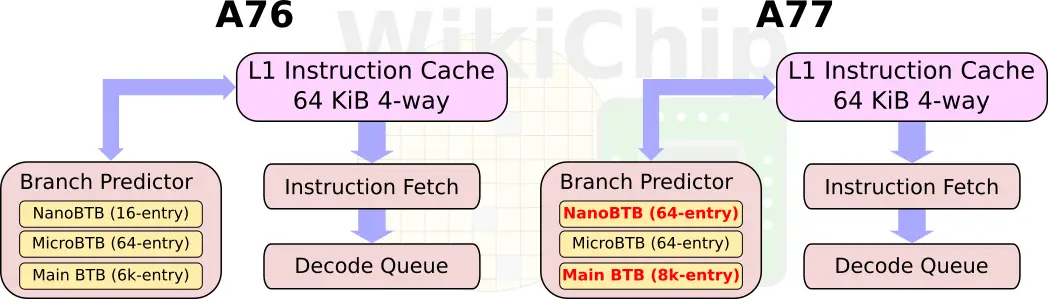
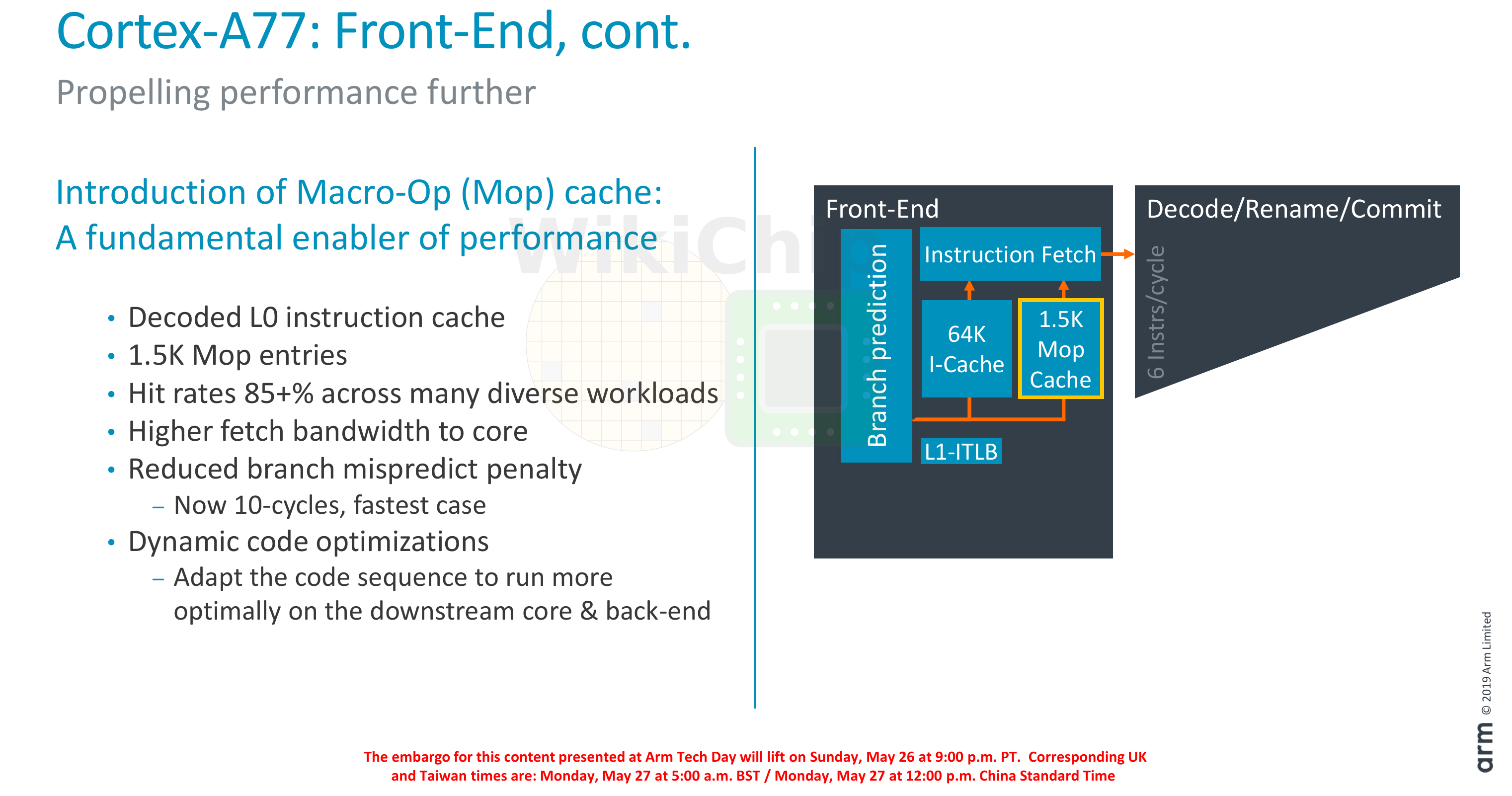
In the A77, Arm enhanced the front-end in order to improve the instruction delivery bandwidth. The improvements come from three sources – an improved branch predictor, a deeper runahead window, and a new MOP cache. Like the A76, there is a branch prediction unit decoupled from the instruction fetch. On the A77, Arm doubled the runahead instruction window to 64 bytes per cycle in order to improve taken branch recovery. The BPU itself has been improved in accuracy as well as capacity. The main branch target buffer has been increased from 6K-entries to 8K-entries and the nano-BTB was quadrupled in capacity to 64 entries.
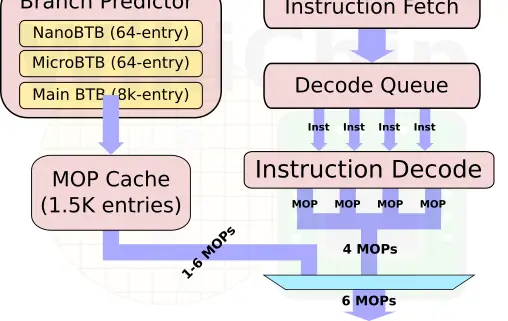
One of the other major additions to the front-end is the new macro-operation cache. This L0 decoded instruction cache is 1.5K-entries deep and has a hit rate often exceeding 85% in real workloads. This is very similar to the kind of benefits that Intel reported when they first added the µOP cache in Sandy Bridge. This cache allows for higher fetch bandwidth and since it bypasses the decode stages, it shaves 1 additional cycle on branch mispredictions, lowering the best-case scenarios for branch mispredictions to 10 cycles.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–