
Amazon Debuts 4th Gen Graviton

At the recent Amazon AWS re:Invent 2023, the company unveiled its 4th-generation custom in-house server processor – the Graviton4. Developed by Annapurna Labs in Israel, the chip utilizes the latest Arm Neoverse IPs along with custom IP primarily aimed at scale-up and accelerator connectivity improvements.

At his keynote, Adam Selipsky, CEO of Amazon Web Services, announced the company’s latest custom server processor, the Graviton4. “Graviton4 is the most powerful and most energy-effienct chip we’ve ever built; with 50% more cores and 75% more memory bandwidth than Graviton3. Graviton4 is 30% faster on average than Graviton3 and perform even better for certain workloads like 40% faster for database applications and 45% faster for Java applications.” Along with the Graviton4 announcement, Selipsky also announced the new R8g Instances for EC2 based on the Graviton4 processors. R8g instances are available for preview today with additional Graviton4-based instances expected early next year.
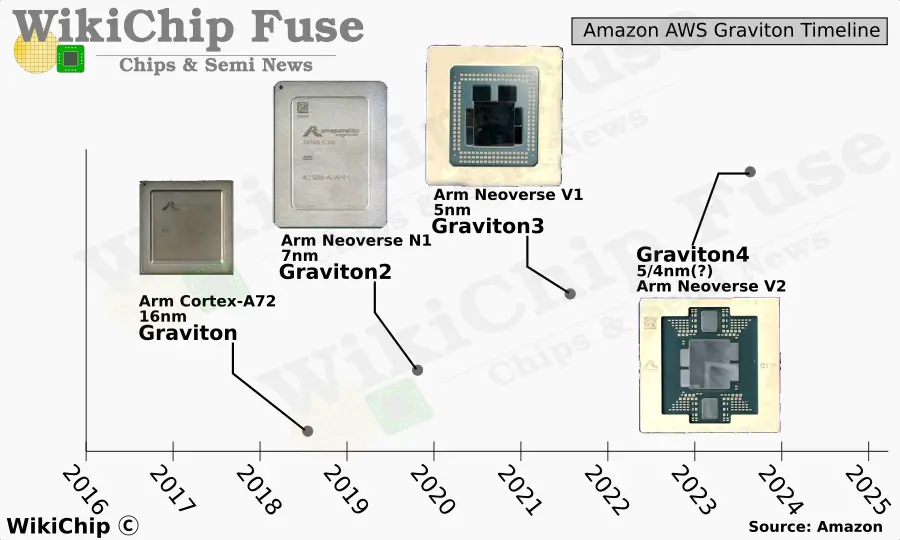
One non-financial-related way of gauging the health of a product is using the product development cadence as a proxy. The first in-house Graviton chip was launched at re:Invent 2018. Amazon quickly followed through with a second-generation, Graviton2, the following year with the introduction of the Arm Neoverse line of cores. On a slightly longer cycle, Amazon introduced the Graviton3 in November of 2021. Graviton3 made significant amount of changes to both the chip architect and the packaging – shifting to Arm’s new Neoverse V Platform and utilizing a chiplet architecture.
Introducing Graviton4
At re:Invent 2023, Ali Saidi, AWS Senior Principal Engineer gave some additional details about the latest chip. On the architecture side, this chip is an evolution of the large changes from last year. The new Graviton4 processor integrates Arm’s latest Neoverse V2. Graviton3 was the first chip to bring (2×256 bit) SVE support while implementing the ARMv8.4-A ISA. Graviton4 updated the core to the Neoverse V2 along with Armv9.0 ISA support for the first time.

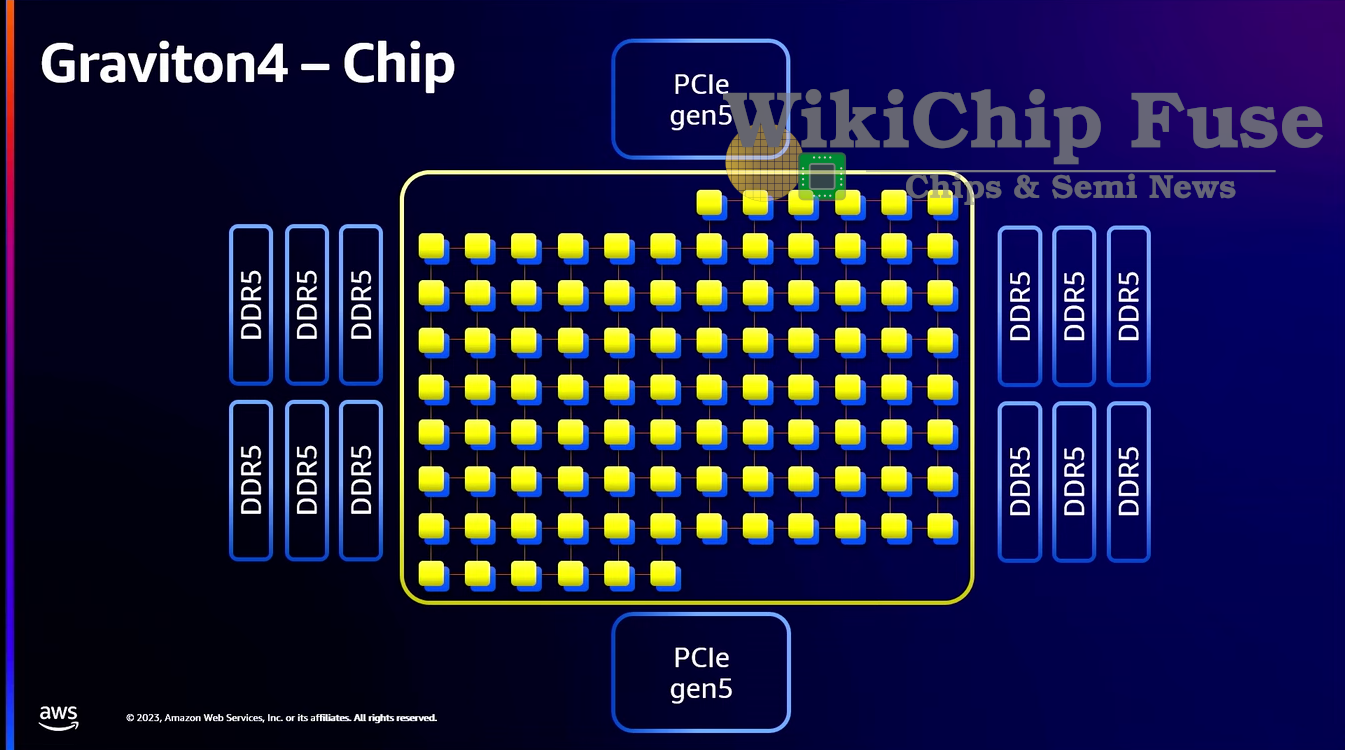
At a higher level, compared to last generation, the new Graviton4 integrates 96 cores – 1.5x more cores than the Graviton3. All the cores are interconnected using the CMN-700 mesh interconnect. Feeding the added core count was also important. To that end, Annapurna Labs increased the number of memory channels by 50% as well as their data rates – going from 8x DDR5-4800 to 12x DDR5-5600. This increases the theoretical peak bandwidth to 537.6 GB/s, up from 307.2 GB/s. This change improves the per-core saturation to 5.6 GB/s, up from 4.8 GB/s in the Graviton3 or 17% per-core. On the connectivity side, the Graviton4 trippled the number of PCIe lanes. Graviton3 was the first to introduce PCIe 5.0 with 32 channels; the new chip increases this to 96 channels of PCIe 5.0.
The V2 L2$ is weakly inclusive of the L1 and is structured as 8-way set associative using four banks. Arm officially offers the V2 with two cache configurations – in a 1 MiB and 2 MiB configurations. For the Graviton4, Amazon chose to utilize the large 2 MiB option – doubling the effective L2 cache from the prior Graviton3. “As we looked at real workloads, we noticed that their working sets was just not fitting in the caches that we had, and as so every core now has 2 MiB of L2 cache,” Saidi noted. With 96 cores on the chip, you’re looking at 192 MiB of L2 cache. Like the Graviton3, Saidi confirmed that the L3 cache is spread and is shared across all the cores. The cache capacity was not officially mentioned but the number 96 MiB was thrown around.
Similar to the Graviton3, the Graviton4 utilizes a 7-chiplet architecture, albeit the PCIe chiplets have slightly different arrangement on the package. On the east and west side of the main compute die are the DDR5 controller chiplets with three channels per chiplet. At the north and south side of the compute die are PCIe chiplets. Perhaps the most notable difference from the Graviton3 is the placement of the PCIe controller chiplets. Those are no longer abutting the SoC die, implying there is no longer an expensive buried bridge between the two. Given the nature of PCIe interfaces, not much of a performance hit likely incurred all while reducing packaging cost which is probably the motivation for this change.

With the new Chip, Amazon closed most of the shortcomings that were criticized by its competitor, Ampere.
| Arm Server Chips Comparison | ||||
|---|---|---|---|---|
| Device | Altra | Altra Max | Graviton3 | Graviton4 |
| Process | 7 nm | 7 nm | 5 nm | 5/4(?) nm |
| Cores | 80 | 128 | 64 | 96 |
| Core IP | Neoverse N1 | Neoverse N1 | Neoverse V1 2x 256b SVE |
Neoverse V2 2x 256b SVE |
| L1 | I$: 64 KiB D$: 64 KiB |
I$: 64 KiB D$: 64 KiB |
I$: 64 KiB D$: 64 KiB |
I$: 64 KiB D$: 64 KiB |
| L2 | 1 MiB | 1 MiB | 1 MiB | 2 MiB |
| L3 | 32 MiB Shared | 16 MiB Shared | 32 MiB Shared | 96(?) MiB Shared |
| Memory | 8x DDR4-3200 | 8x DDR4-3200 | 8x DDR5-4800 | 12x DDR5-5600 |
| PCIe | 128x PCIe 4.0 | 128x PCIe 4.0 | 32x PCIe 5.0 | 96x PCIe 5.0 |
Different Focus for Each Generation
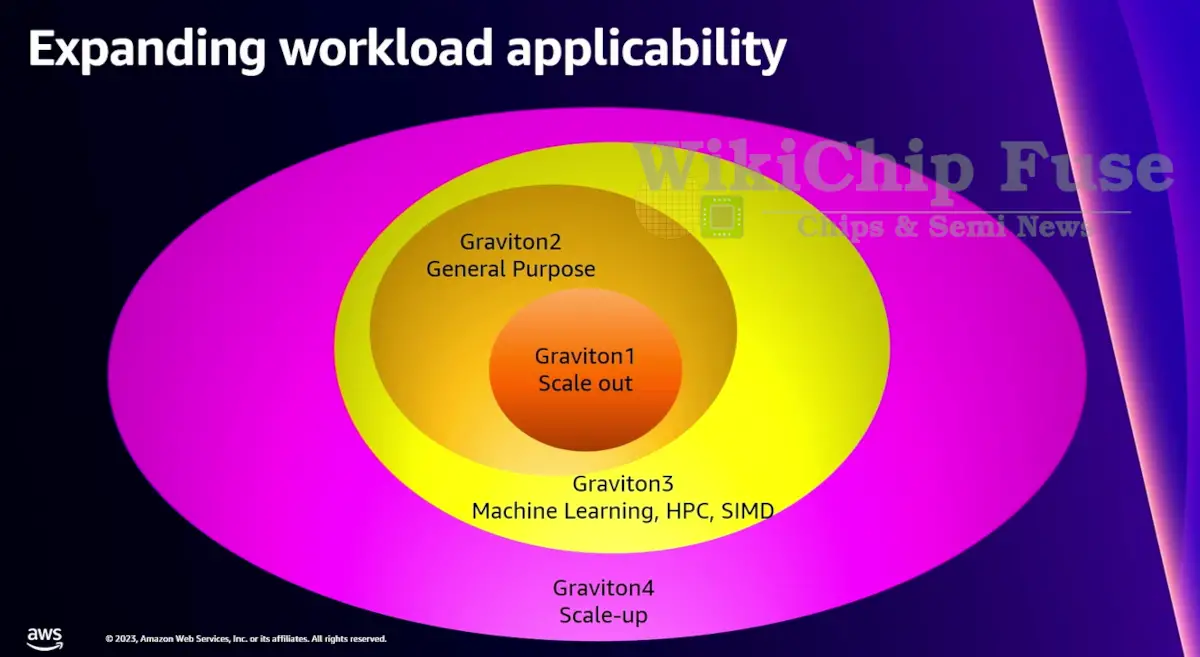
One of the things Saidi explained in his presentation at re:Invent 2023 is that every generation of Graviton had a unique main focus that they wanted to address. When they started Graviton1, their main focus was to make a proof of concept. “When we started with Graviton1, much of the focus was on proving that you could have another architecture in EC2; you could configure instances the same way and run a variety of workloads with security groups that just work as you expected.” With the Graviton2, the focus was turned into better general purpose compute, increasing the number of applicable workloads. “With Graviton2, we increased those workloads substintially. We saw people running Java applications, key-value stores, databases, and tons of other workloads.” With the Graviton3, the focus shifted to higher performance, especially on the HPC side and machine learning applications. This was done by shifting to the Neoverse V series and introducing SVE support and larger SIMD widths. “With the new Graviton4, our focus now is scale-up; increasing the applicability again. We’ve had customers come to us and tell us “I’ve moved all our databases to Graviton. It’s great I currently use 32 vCPUs and I think i the next 1-2 years I might end up using 64 vCPUs as my business grows. But you don’t have an option that goes bigger.” So with Graviton4, we now have an option for this.”
With the Graviton4, the base support is now increased by 50% to 96 cores in a single socket with 96vCPUs in the AWS 24xlarge instances. For applications that must be further scaled-up, the new chip introduces new multi-socket coherency. Two Graviton4 chips can be connected together for a single system that’s effecitvely 3x the number of cores as Graviton3 and 3x the number of DRAM. It’s worth pointing out that since the data rates have also increased on Graviton4, the total system peak theoretical bandwidth is actually higher, at 3.5x that of Graviton3.
With the introduction of the Neoverse N2 and V1, Arm also introduced the Coherent Mesh Network (CMN) 700 mesh network which is the foundation for the Graviton4’s mesh interconnect. One of the capabilities of the new mesh is mutli-die coherency which also supports CCIX 2.0 and CXL. The slide presented below appears to show three CCIX links between the two sockets, it’s unclear if that’s purely for illustration purposes or if the chip does integrates 3x BiDi links.

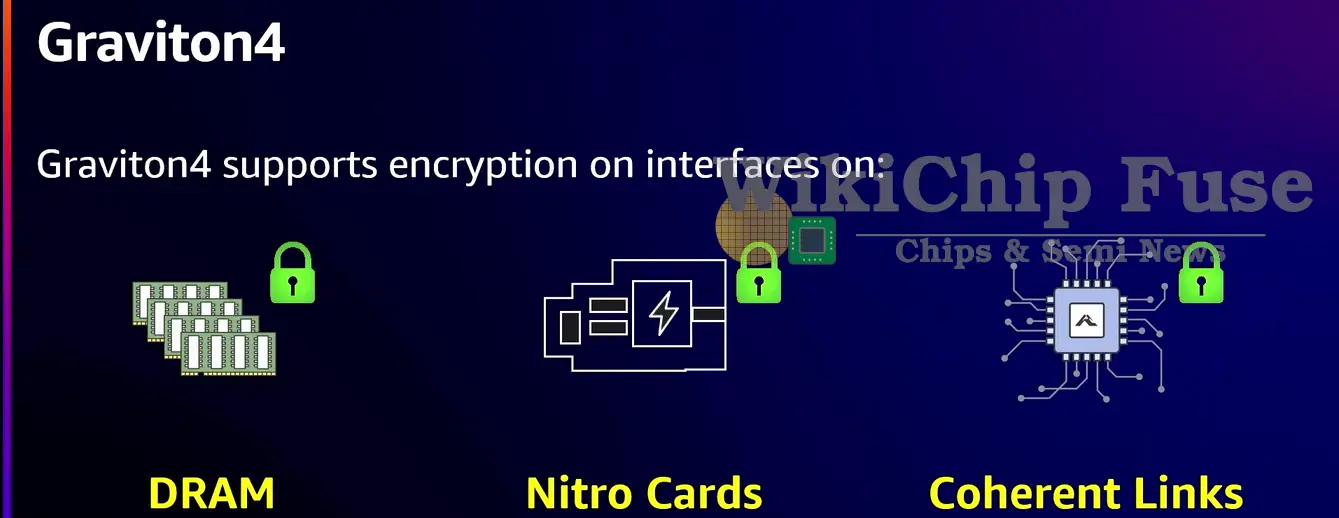
When the Graviton2 was first introduced, it introduced memory interface encryption support. This support was carried over to the Graviton3 and now the Graviton4. The new chip expands encryption support to the new multi-socket coherency links as well as to the Nitro cards interfaces.
When Graviton team was developing the Graviton4, another team was also working on the Nitro chips. Saidi explained this allowed them to co-develop the two with some additional optimizations. The final dual-socket platform developed can operate in a number of different modes. It can operate as two non-coherent virtual systems, one coherent virtual system, two metal systems, or one metal system. One reason for these configurations is the ability to turn off the coherency when not used and get additional power savings.

Performance
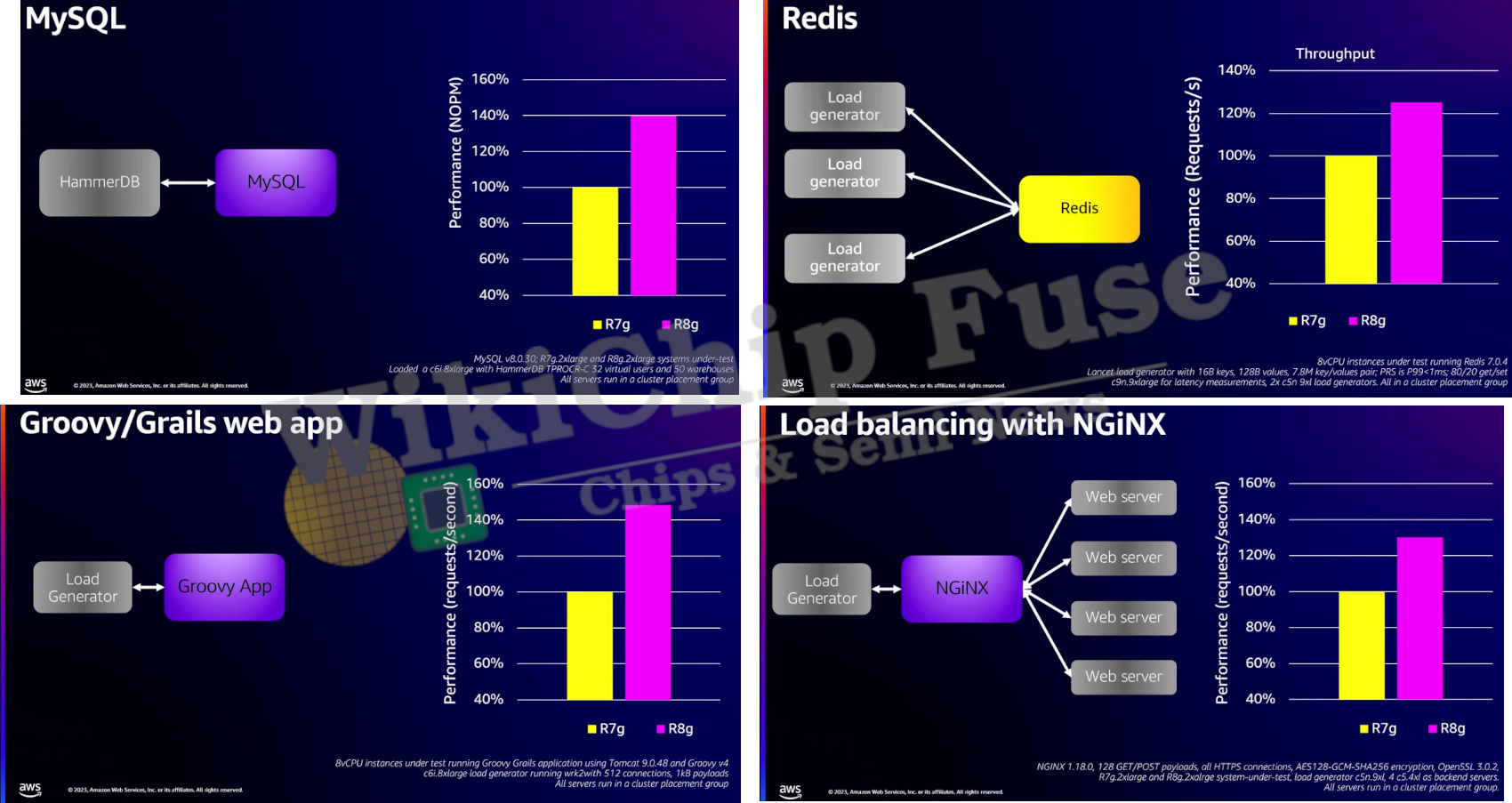
A number of performance benchmarks were also presented. The benchmarks compare Graviton3 to Graviton4 on the R7g to R8g instances in a like-to-like systems.
When compared to the Graviton3 in a MySQL HammerDB load generator test, the Graviton4 demonstrated a 40% increase in performance. Similarly, using Nginx in a load balancing testing, the Graviton4 demonstrated 30% improvement in performance over the Graviton3. Similarly, in Groovy/Grails web application, the Graviton4 demonstrated over 40% improvement in performance. In the popular Redis key-value store test using two load generators and a latency tester, Saidi reported a 25% improvement in performance.
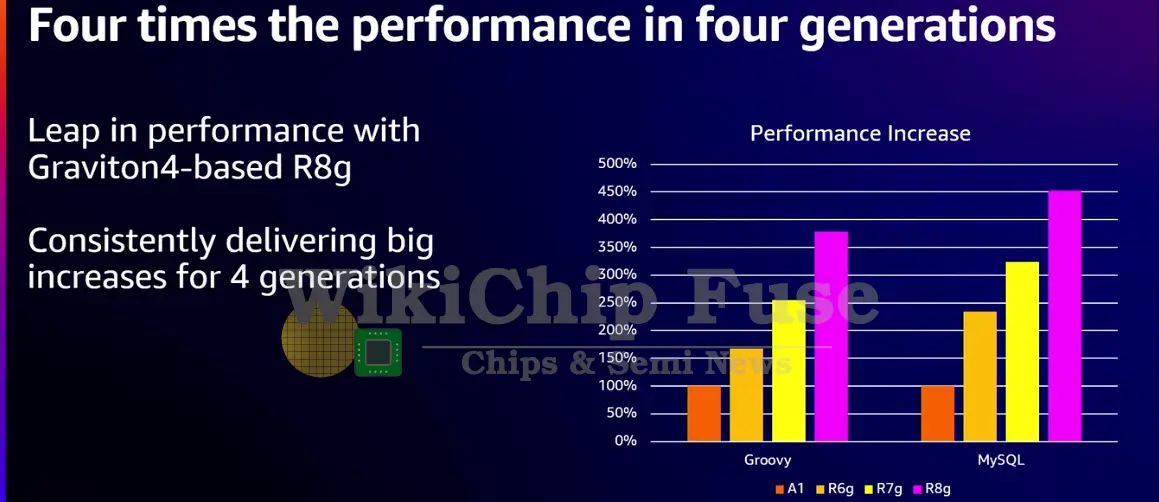
When compared the same Groovy and MySQL workload test as above across all generations of Graviton, Saidi noted that they see nearly a 4x or higher performance improvement when compared to the original Graviton chip which was introduced back in 2018.
The Graviton4-powered, R8g instances, are available today in preview, with general availability planned for early 2024.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–