
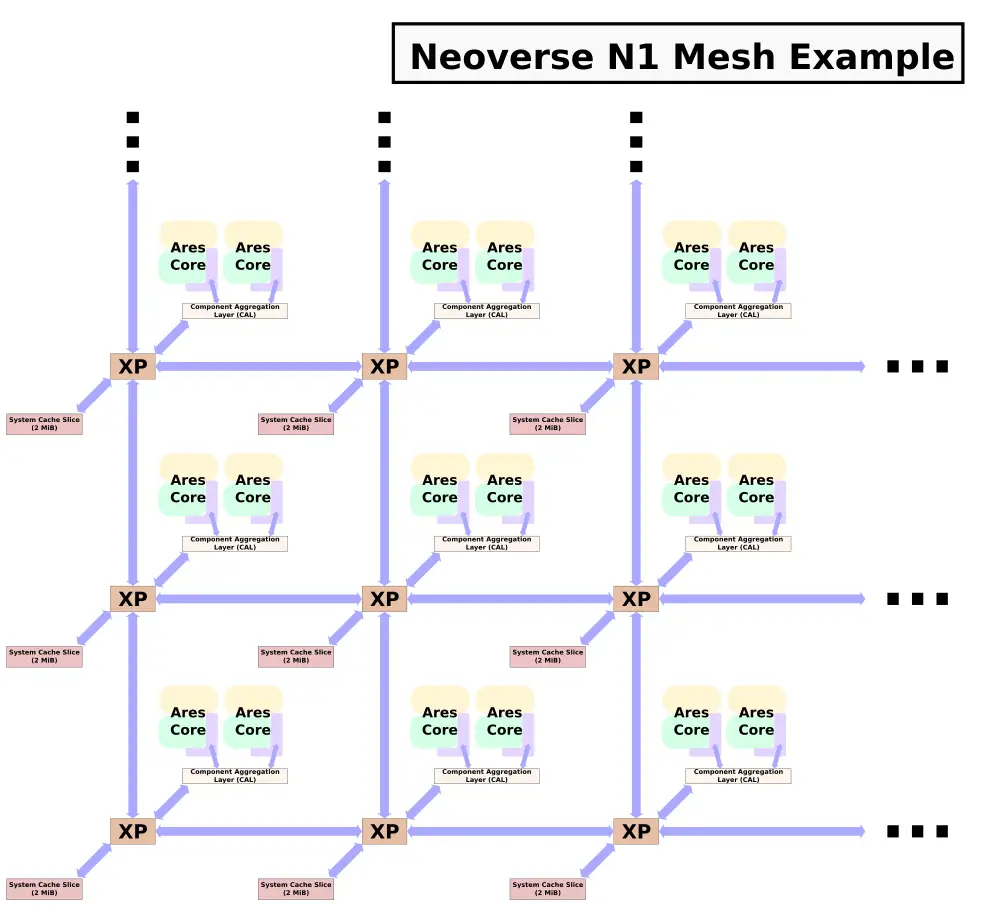
The Mesh Network For Next-Generation Neoverse Chips

Late last month we saw Arm launching its latest Neoverse N2 and V1 server CPU IPs. These CPUs should make their way into next-generation ARM-based infrastructure chips. But integrating a bunch of Neoverse CPUs onto an SoC does not good if they can’t properly talk to each other and the outside world. There are a number of high-performance interconnect IP companies out there. When Arm started branching out into the infrastructure segment a number of years ago, they too, started offering an interconnect IP solution for their products with the introduction of the CMN-600.
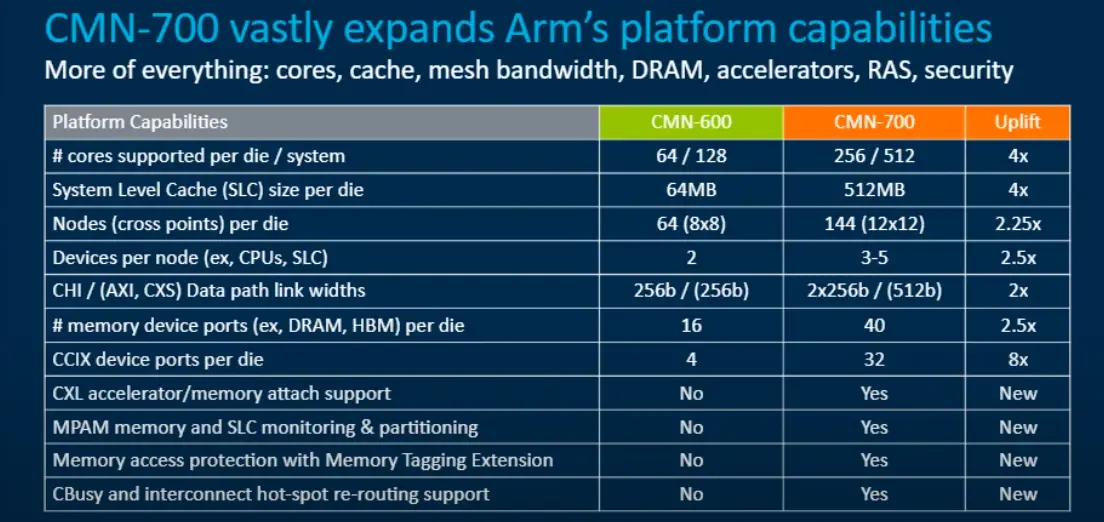
The Coherent Mesh Network (CMN) 600 which was introduced in late 2016 is finally reaching its limits with some of the recent server processors. Amazon’s AWS Graviton2 and Ampere Computing Altra server processors both use the CMN-600 as the underlying coherent interconnect network. Along with the launch of the new N2 and V1 server CPUs, Arm also launched the direct successor to the CMN-600, the CMN-700.
The New Mesh Network
The new CMN-700 mesh network targets specifically the infrastructure market and therefore incorporates features that are critical for things such as server SoCs. The CMN-700 is now Arm’s 3rd-generation coherent interconnect IP. Note that Arm also has a number of other IPs such as the NIC-400/450 which provides SoC connectivity but are non-coherent. The goal of the CMN-700 is to connect CPU cores to other CPU cores as well as other accelerators, I/O, cache, and memory. At a high level, the CMN-700 is a scalable coherent mesh network with distributed system cache and snoop filters. The CMN-700 was designed to support the new Neoverse N2 and V1. It’s also possible to support older processor cores and other devices through the Coherent Hub Interface E (CHI-E) compliant gateway. The CMN-700 was designed with higher bandwidth and lower latency in mind taking advantage of upcoming I/O and memory interfaces and features such as PCIe Gen5 (along with CXL), DDR5 memory, and HBM3 memory.
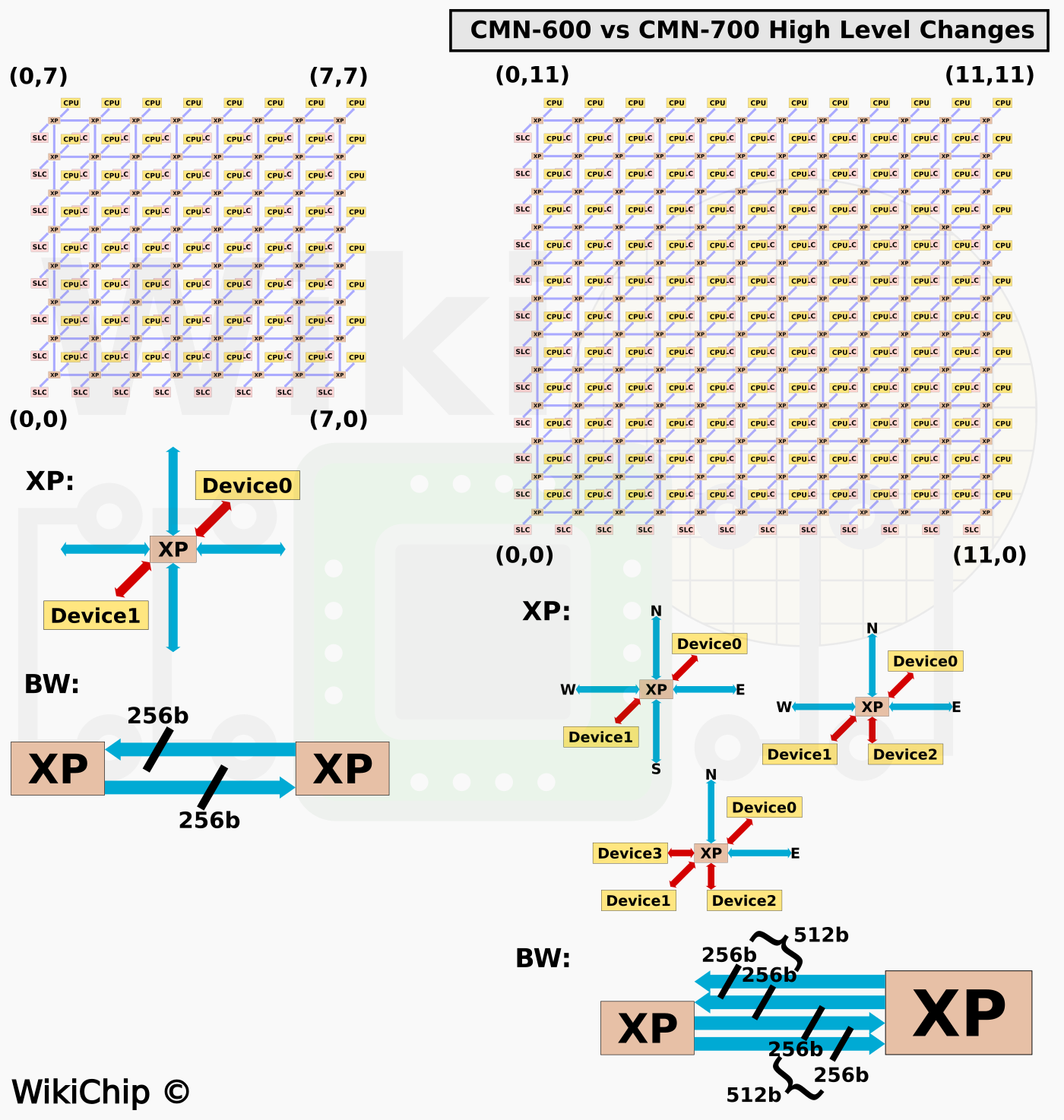
Compared to the CMN-600, the CMN-700 is significantly beefier across every parameter. The CMN-700, like its predecessor, comprises a set of crosspoints (XPs) that behave like a router that are arranged in a two-dimensional rectangular mesh topology. Each XP is capable of connecting with up to four neighboring XPs along the four cardinal directions using the four mesh ports. On the CMN-600, the maximum mesh that can be built up is using 64 XPs arranged in an 8×8 grid. The new mesh network on the CMN-700 is designed to support considerably larger grids with up to 144 crosspoints on a 12×12 grid. As a corollary, the number of cores supported is increased from 64 cores per network/die and 128 cores/system to 256 cores and 512 cores per system. Likewise, the amount of system-level cache supported on the CMN-700 was increased by 8x vs the CMN-600 – from 64 MiB to as much as 512 MiB. Note that smaller networks are always possible. It’s also worth pointing out that larger configurations are also actually possible but not in the most straightforward way. For example, the CMN-600 has been used on chips that go beyond 64 cores by grouping multiple cores in a DSU attached to a single fully coherent home node.
There are a number of major enhancements to the mesh interconnect within the physical mesh itself. Previously, on the CMN-600, each XP had four mesh ports and two device ports. The mesh ports allow each XP to connect to its neighboring XP while the device ports enable connections to devices. Devices here mean things such as a CHI interface (to things such as cores), a system-level cache (SLC) slice, a memory interface, or an AMBA AXI. With the new CMN-700, it’s now possible to support three devices and on the edge of the mesh network, it’s possible to support even four devices (technically it’s also possible to support even 5 devices on a single-XP topology).
Interconnecting the mesh network are a series of communication networks including request, response, snoop, and data. The data channel comprises a pair of 256-bit wide interconnects, one running in each direction for receive and transmit. On the CMN-700, Arm offers an option for double mesh channels. In other words, under this option, there are now 2 256-bit wide links going in each direction creating a data channel that’s 512b wide. In addition to the widening of the CHI interfaces, the AMBA AXI and CXS are now 512b wide as well. Arm says that the mesh can operate at frequencies of around 2 GHz. That means that for the largest possible configuration of 12×12, the peak theoretical cross-sectional bandwidth is around 3.072 TB/s.
The CMN-700 enhanced the maximum I/O support as well. The CMN-600 was capable of supporting up to 16 memory controllers through the CHI SN-F ports (CHI slave nodes). On the new CMN-700 mesh network, it’s now possible to support to 40 (or 80 dual channels). It’s also possible to mix and match memories together. For example, it’s possible to have both HBM3 and DDR5 memory controllers on the same chip. The CMN-700 also increased the number of CCIX device ports per die from 4 to 32.
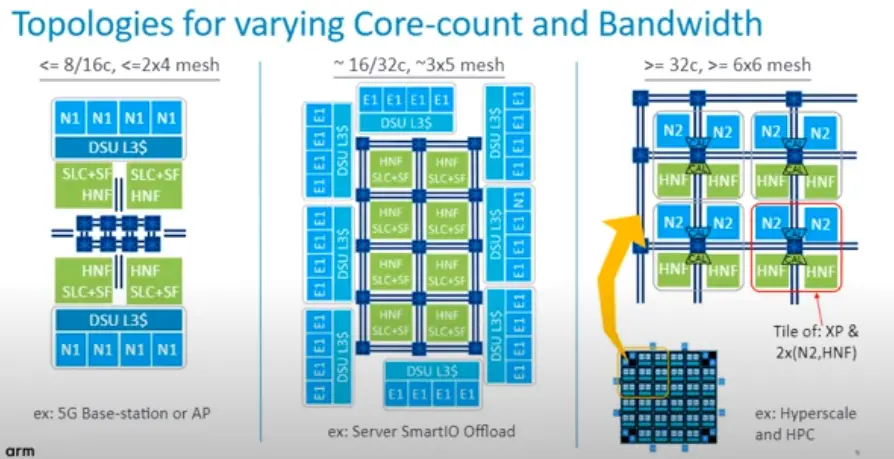
A few hypothetical CMN-700-based SoC configurations are shown below. In the first example for a 5G base-station or access point, 8-16 cores can be interconnected on a small 2×4 or smaller mesh. Here the SLC+SF home nodes are outside of the mesh fabric with the two DSU CPU clusters at the top and bottom of the chip with the I/O peripherals on the edge. For large core configuration and mid-size mesh networks, the SLC+SF home node are now inside the mesh fabric with the CPU clusters connected on the outside. Memory and I/O then come out of the gaps between the clusters. For much higher core count and mesh configuration such as what you can find on the high-performance Arm servers, the CPUs and home nodes are typically placed directly within the mesh in a tile configuration. This allows for the replication of the same core tile (XP along with 2x CPU and HNF) across the die.
New Features
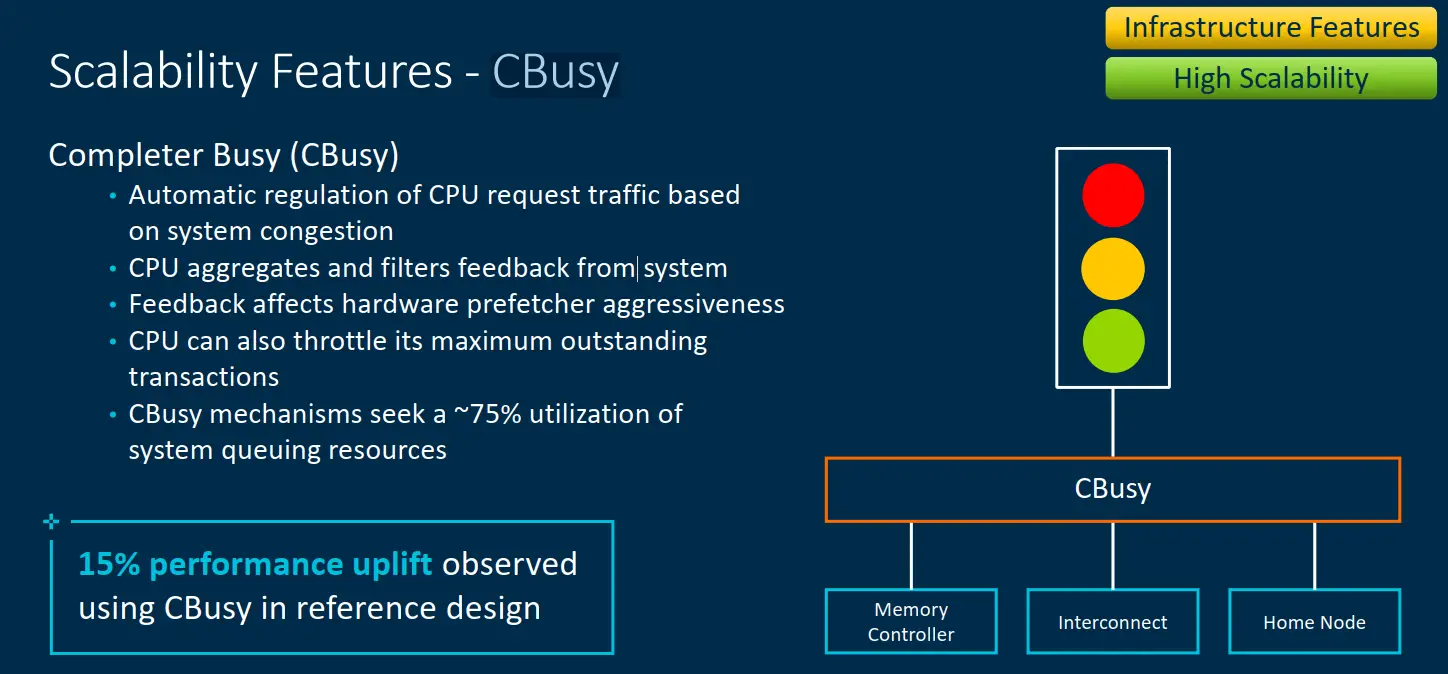
There are a couple of new quality-of-service and scalability features that were also added to the CMN-700. Completer Busy (Cbusy) (pre-official launch Arm called it MemBusy for a short period of time) is a new optional feature that allows for the automatic dynamic regulation of CPU request traffic based on the state of the congestion in the system. When the memory queues of the system become very busy, memory congestion notifications are sent to the core. The core, in turn, the CPU can reduce the hardware prefetcher aggressiveness, throttling them down a bit, and temporarily lower outstanding transactions. Arm says that up to 15% performance uplift was observed on the Neoverse V1 core reference design when the CBusy feature was used.
While not directly related to CBusy, Arm also added new hot-spot re-routing support that allows traffic to be temporarily re-routed along with other XPs when high congestion is detected along the usual traffic route.
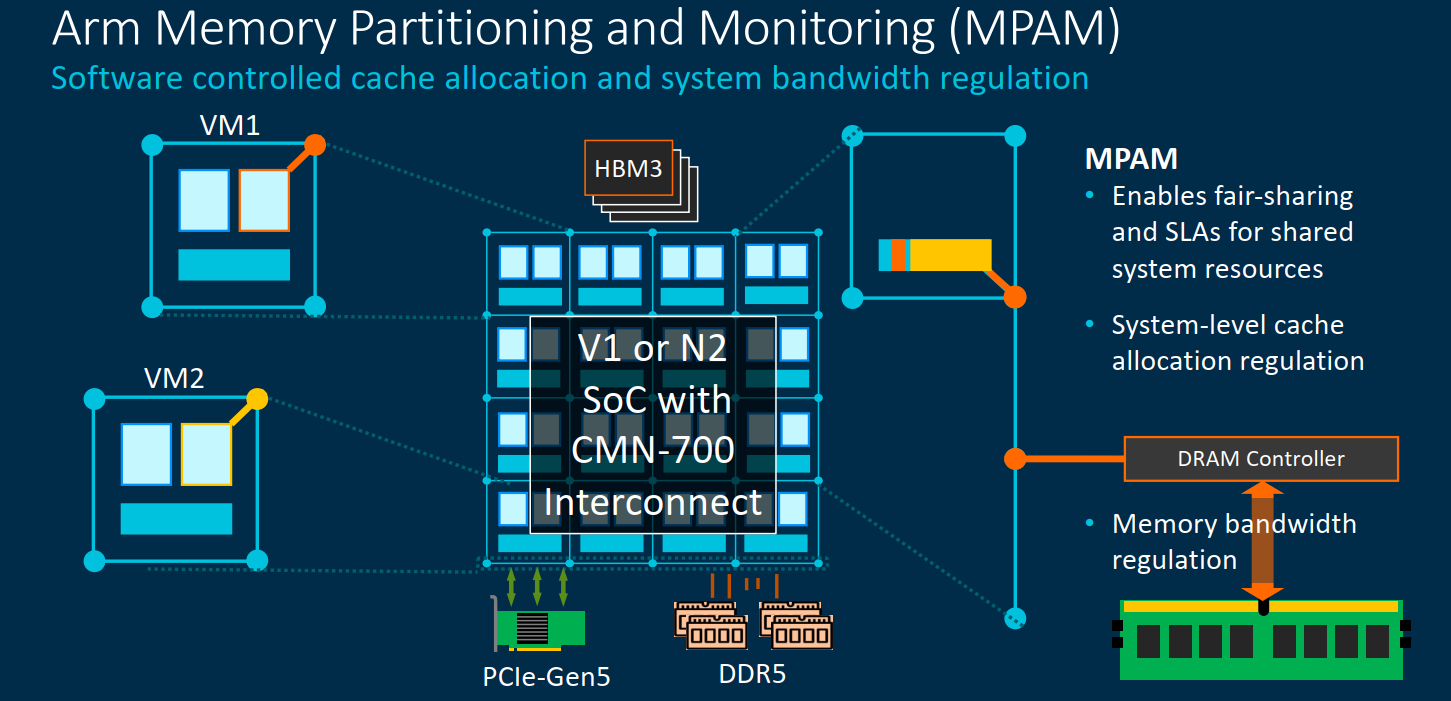
On the memory side of things, the CMN-700 makes extensive use of MPAM. Memory Partitioning and Monitoring (MPAM) was actually added to the ARMv8.4 architecture in 2017. MPAM provides cache line allocation of the system cache and on a per-process thread basis through a software-managed interface. This allows a hypervisor, for example, to monitor and manage memory just as it does with cores/threads. This feature is also extended to the memory controllers. The feature enables VMs to make more fair use of system resources.
Chiplets/Multi-Chip Capabilities
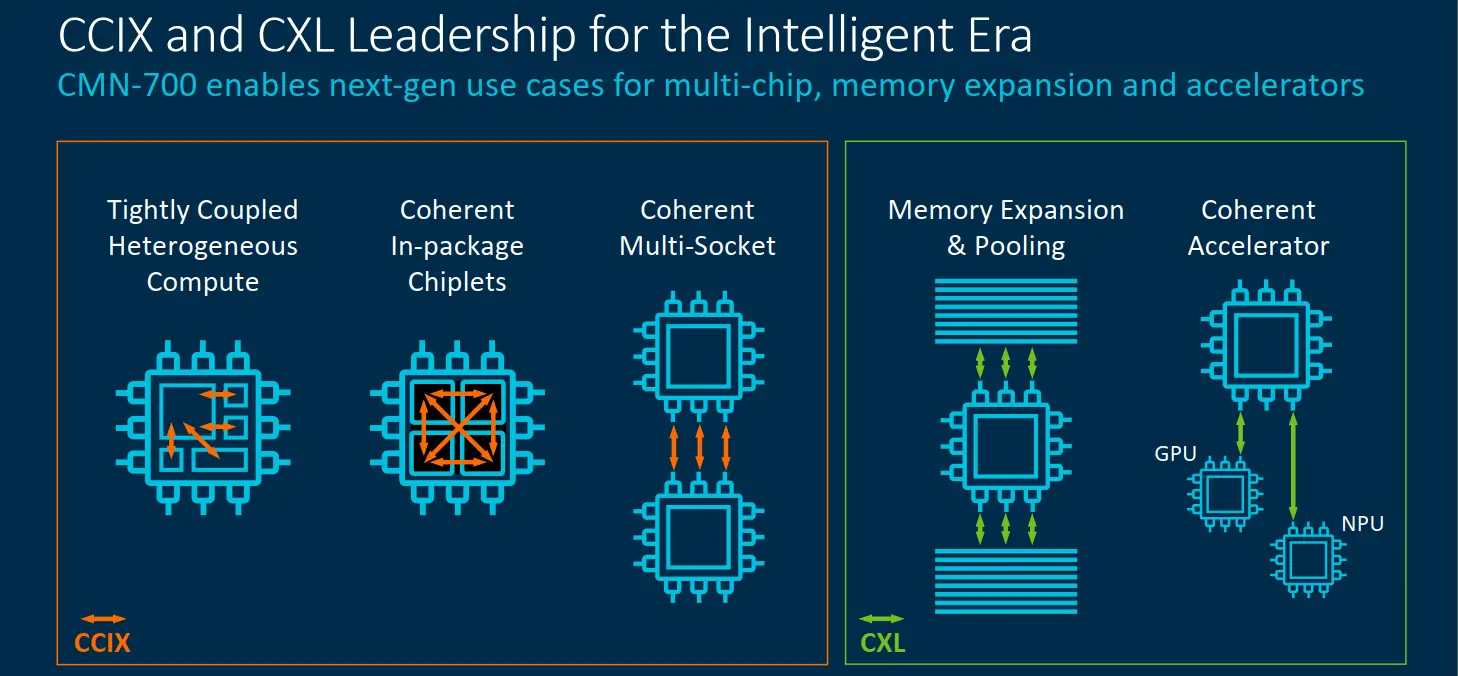
In addition to the CCIX support which was also found in the CMN-600, the CMN-700 adds new support for CXL accelerators and memory-attached devices. The CMN-700 supports both CCIX and CXL due to their strengths being in different areas. Both support multi-chip and cache-coherency capabilities. On CXL, coherency traffic is resolved on the host which has the shared memory and maintains coherency and snoop filter states. On the other hand, in CCIX the memory home node, cache, and snoop filtering live nearest the shared memory it covers. CCIX coherency, therefore, lends itself to better support snooping across multiple devices and distributed cache. CXL host-based coherency, on the other hand, enables much simple construction of coherent accelerators. As we noted earlier, the CMN-700 increased the number of CCIX device ports from 4 to 32. An eight-fold increase in CCIX ports is a clear indication that Arm expects customers to roll out products with a large uptick in accelerator-based products.
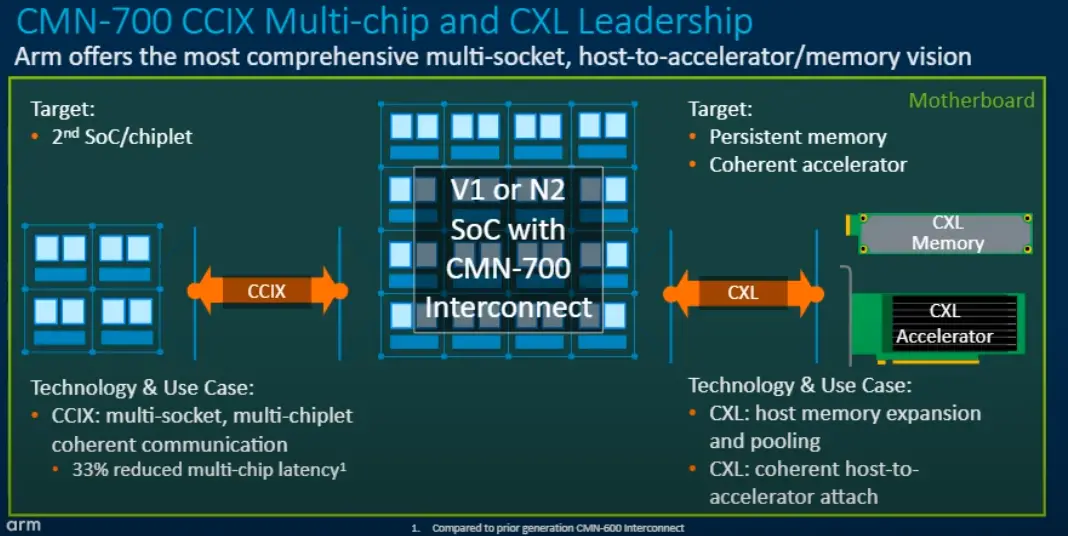
There are a couple of challenges when you are dealing with NUMA nodes and distributed caches. On the CMN-700, Arm developed a new interface protocol called AMBA CXS Issue B (CXS-B) which was designed to reduce the latency of CCIX CXL packets when they are being requested from/to a remote node over PCIe. This is achieved through a new ‘fast path’ that bypasses the transaction layer, going directly to the link layer. The unified interface can be used for either die-to-die or chip-to-chip and supports both CCIX 2.0 and CXL.
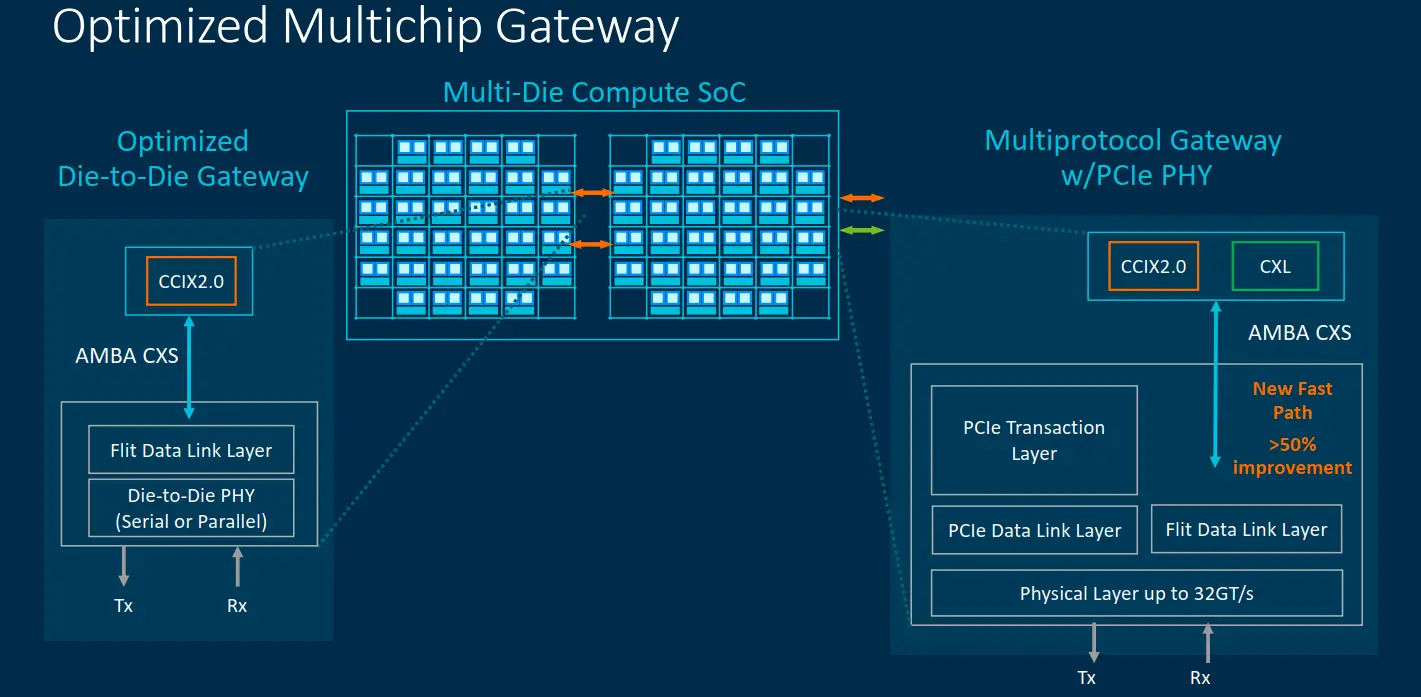
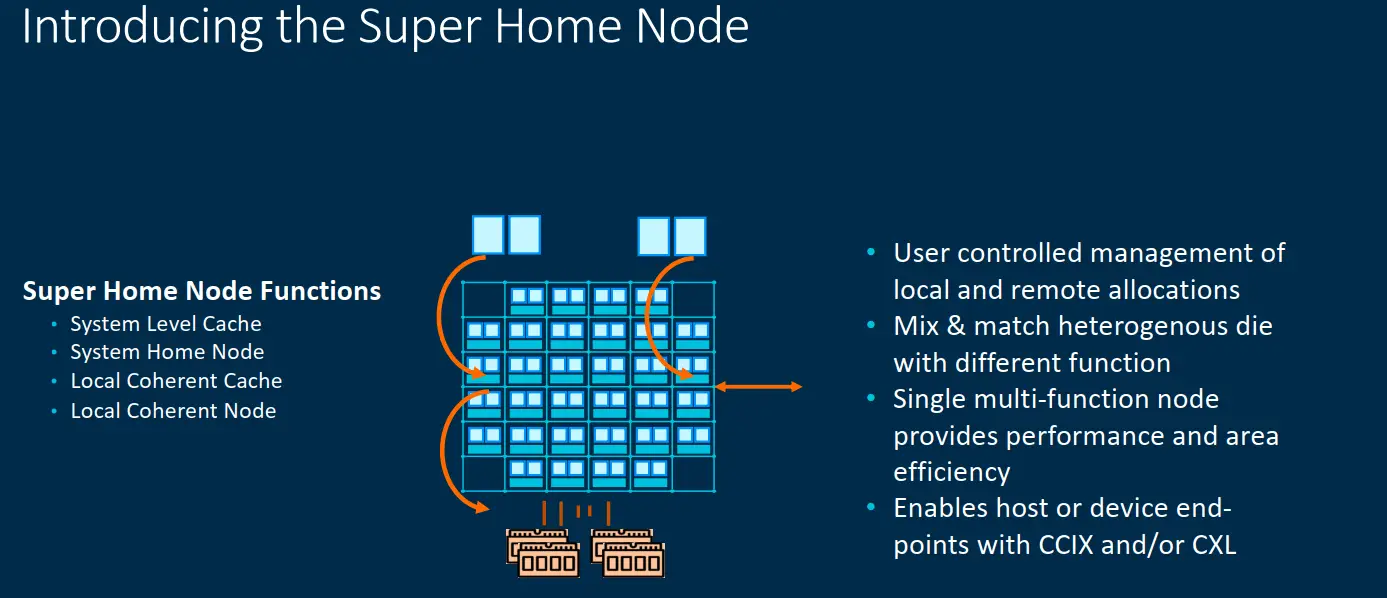
To better aid with dealing with coherency, the CMN-700 introduces a new concept called a Super Home Node. The Super Home node can have and function differently based on the system configuration. For example, it can comprise of standard system-level cache slide or a local home node. But it can also comprise a local coherent cache and local coherent node for some remote memory that is connected to the device. It’s designed to be user-controlled and allows for different kinds of optimizations depending on how it’s used.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–