
A Look at NEC’s Latest Vector Processor, the SX-Aurora
NEC has a rich history of designing high-performance vector processors going back over 35 years. Historically, their SX series of vector processors and supercomputer systems targeted large HPC systems exclusively which made mainstream adaptation difficult.
Growing fields such as AI sparked new interest in vector processors which has caused NEC to shift their focus. The company’s most recent vector processor, the SX-Aurora, has taken a slightly different approach using PCIe accelerator cards to build up a system thereby making it easier for developers to gain access to vector processors. Furthermore, the SX-Aurora TSUBASA now uses what NEC calls a “standard environment” meaning the system comprise of their vector processor and a standard Intel x86 node running Linux.
Vector Engine Card
At the center of all the systems is the Vector Engine (VE) Card, a PCIe Gen 3 x16 card containing a single vector engine module. NEC calls the current generation the VE v1.0 so presumably this branding is here to stay with the next generation as well. There are two versions: air cooled and water cooled. The air-cooled version also comes in two types: pass and active cooling.
[foogallery id=”1836″]
Scaling Out
The idea of VE Cards is a complete paradigm shift for NEC from all prior vector supercomputer they have built. The new cards are aimed to satisfy the needs of different users and requirements. NEC has designed a series of systems with different configurations. The A100 series is a tower model. It consists of a single Skylake Xeon Gold/Silver and one VE card of Type 10C. The A300 series are the standard rack-mountable models with air cooling. There are a number of models ranging from two to eight VE cards.
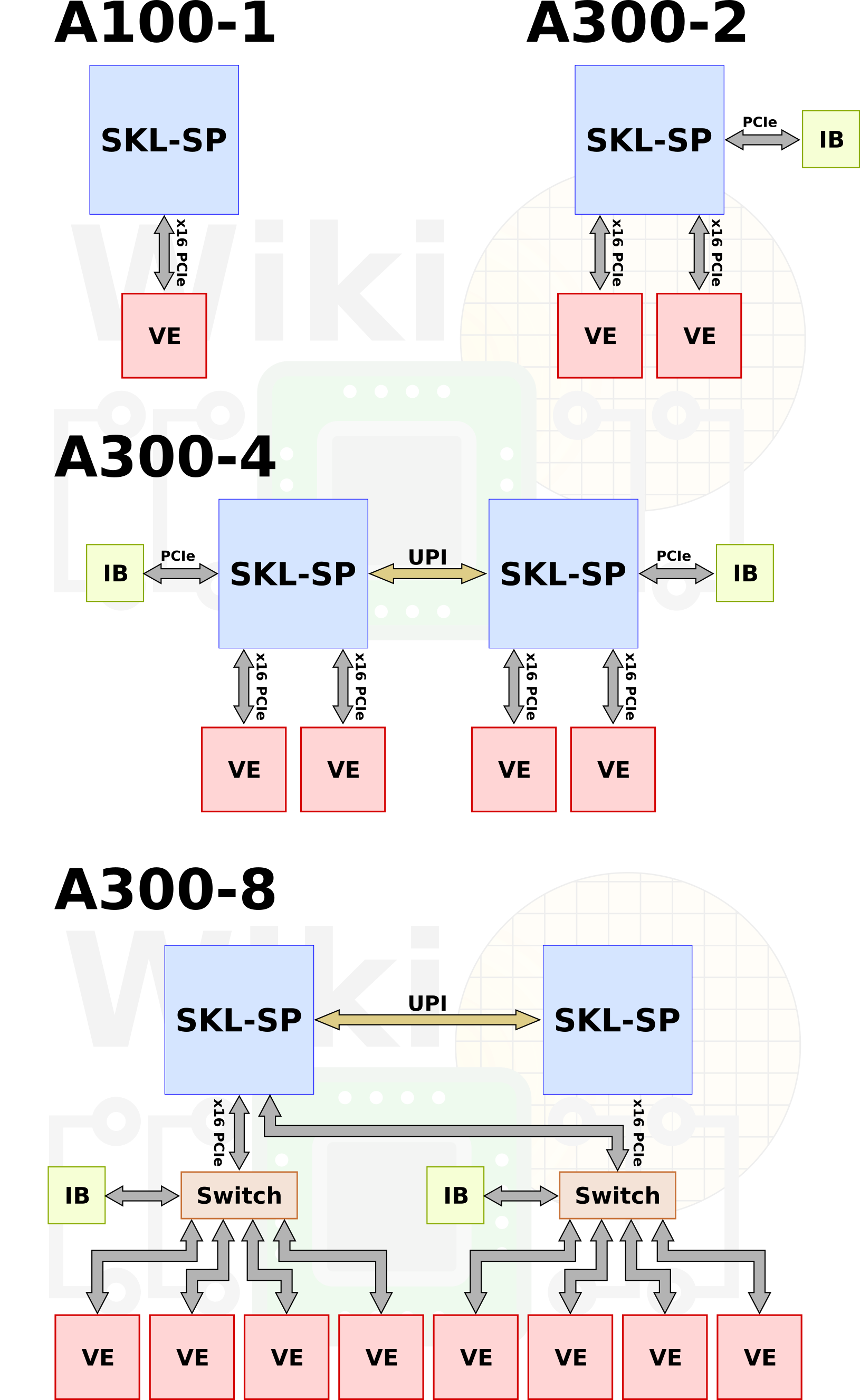
[foogallery id=”1840″]
For their supercomputer model, the A500 series, NEC incorporates up to 64 VE in 8 racks connected over InfiniBand. The A500 series uses direct liquid hot water (40 °C) cooling.

Offloading Programs, Not Operations
Although the configurations shown above look similar to a typical accelerator such as a GPGPU, the NEC vector engine card is quite a bit different. The VE follows an OS offload model. That is, the full program is transferred to and is executed on the vector engine exclusively except for the occasional system calls and other I/O functionality. This drastically reduces the requirements of data transfer across the PCIe link, avoiding bottlenecks. Additionally, the VE relies on larger capacity memory (currently 48 GiB) and can be used by standard languages such as C, C++, and Fortran without the need for special programming models and platforms such as CUDA. The main motivator behind this execution model was addressing the common problem with many conventional accelerators which rely on frequent data transfers between the host and the accelerator which tends to bottleneck easily. It’s also worth pointing out that to ease development, generally, system calls on the vector engine are transparently offloaded to the vector host, therefore, programmers do not need to take care of those manually.
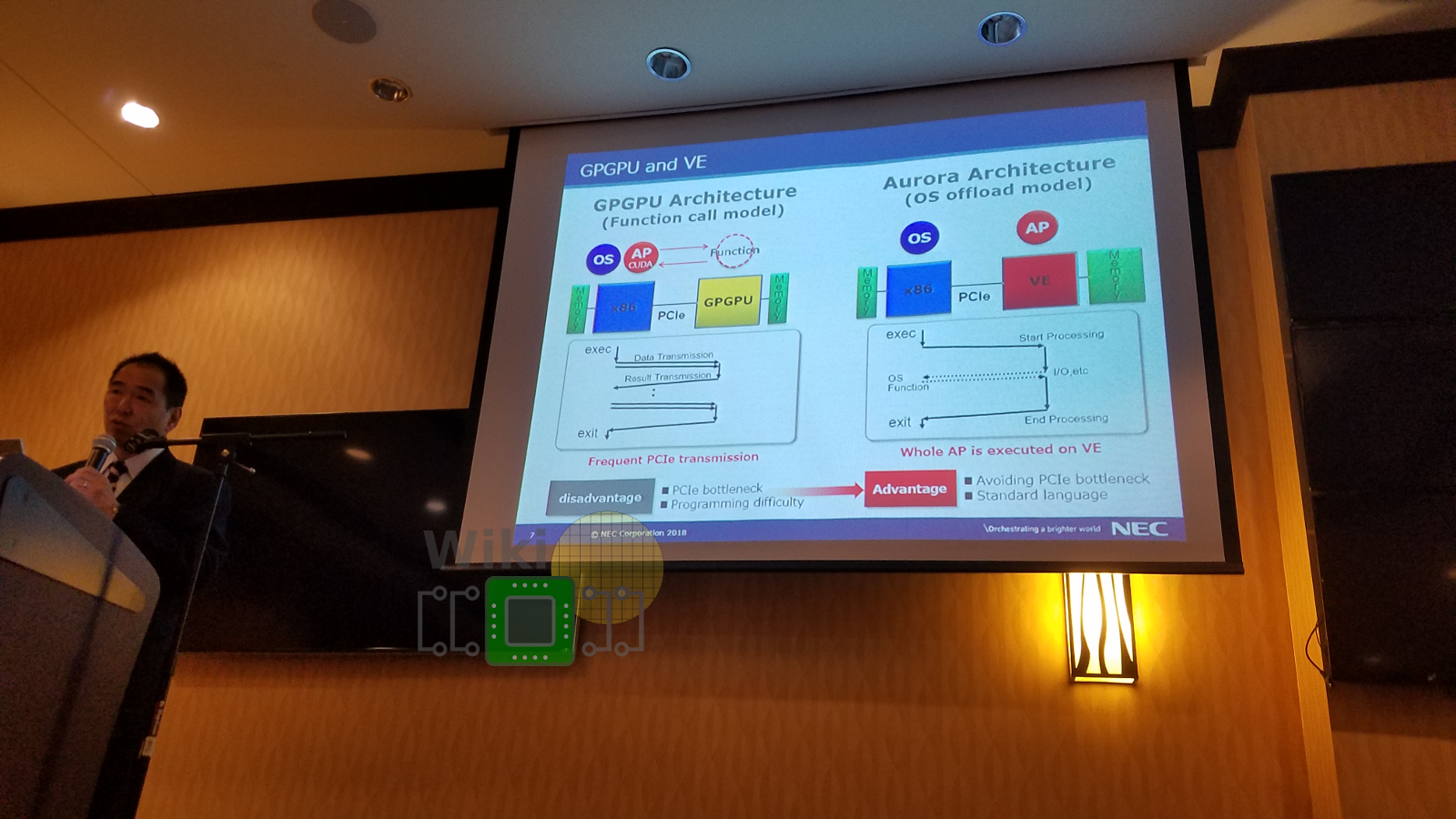 |
 |
The main execution model doesn’t work for everything. Addressing this, NEC is currently working on two more models – VH Call and VEO. Under the vector-host call (VH Call) model, applications are offloaded to the vector engine with scalar suited parts of the program executing on the host processor (Intel Xeon). Likewise, the vector engine offload (VEO) looks like a traditional accelerator where only the vectorized portion is offloaded.
 |
 |
The way a typical program is executed is relatively simple. A special program called ve_exec is used to invoke the user’s vector program. The ve_exec program then requests the OS running on the vector engine to create a new process. Ve_exec then iterates over the executable ELF file, reading each segment and passing it over to the vector engine. A pseudo-process is also created on the vector-host machine (x86) which has a virtual address space parallel to that of the vector engine. For example, upon a certain memory manipulation, a virtual address page is first allocated followed by a request to the vector engine OS to allocate a page on the physical address space on the VE. The VE handles the virtual address translation and protection.
The SX-Aurora has a special instruction called the store host memory (SHM) instruction. On an exception, the SHM instruction is used to communicate the system call ID and its arguments back to the pseudo-process on the vector host. A monitor call (MONC) instruction is then executed which halts the VE core and invokes an interrupt on the VH. The VE Linux driver on the VH wakes up the pseudo-process to handle the exception.
SX-Aurora Vector Engine
At the heart of the PCIe card is the SX-Aurora vector engine processor. This is a single chip with eight very big cores. It’s fabricated by TSMC on their 16 nm FinFET process. Prior chip, the SX-Ace, featured a whopping 16 channels of DDR3 memory, requiring significant board space. The move from a dense server board to a PCIe card meant NEC had to increase the memory bandwidth to cope with the higher compute power, all while reducing the board size. NEC solved this by opting to use HBM2. In total, 6 HBM2 modules sitting on a very large interposer were integrated along with the vector engine processor on a single chip.
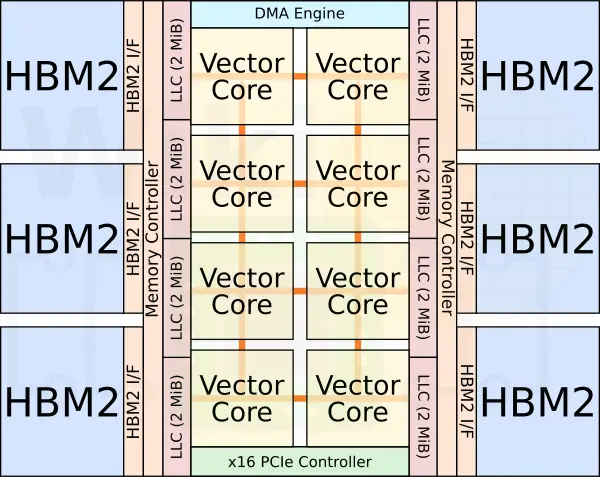
Vector Cores
There are eight vector cores in each chip, double its predecessor. Still, despite the seemingly low core count, each one is actually capable of performing up to 192 double-precision floating pointing operations per cycle. With the top binned chip clocked at 1.6 GHz, this works out to 307.2 gigaFLOPS per core for a total of up to 2.45 teraFLOPS.
Each core has three major functional blocks – the scalar processing unit (SPU), the vector processing unit (VPU), and the NoC interface.
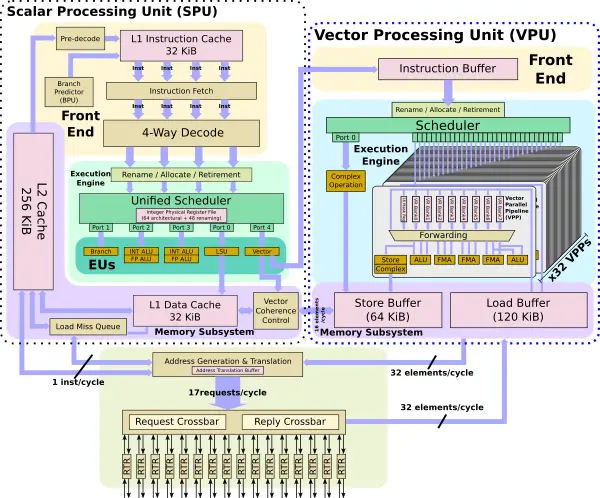
Although this is a vector processor, the scalar processing unit is still quite important. Keep in mind that since applications run entirely on this chip, the SPU has to have relatively good serialized code performance. For that reason, the SPU is a four-wide OoO core – capable of fetching, decoding, and renaming four instructions per cycle. It has all the facilities necessary to run a complete operating system. We won’t touch much on the SPU in this article but we do cover it in more detail here. One important task the SPU has to do is make sure the vector processing unit is constantly doing busy work. The SPU can pass one instruction per cycle over to the VPU instruction buffer to get executed. While this is happening the SPU can also send the address generation unit a vector instruction so that the vector addresses can be calculated ahead of time.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–