
A Look At The Habana Inference And Training Neural Processors

One of the few independent AI startups to have shipping products in the market is Habana Labs. The Israeli startup was founded in 2016 and has since secured $75 million in series A and B funding. Habana Labs focuses primarily on the data center, edge, and workstation markets where the high thermal budget allows for a large amount of AI compute. In less than three years the company already delivered a product to market with a second product sampling and a future generation in the works.
Habana has gone with a bifurcated product line that uses two separate chip designs – one for inference and one for training. We have seen this approach used by other companies such as Intel Nervana NNPs. This allows them to better optimize for each of the workload types. In Habana’s case, however, the company still relies on the same base architecture for both training and inference but optimizes the two designs for slightly different workloads. Other companies, such as Intel, for example, rely on two very radically different chip designs.
Goya
Goya is Habana’s microarchitecture for the acceleration of inference. Goya is fabricated on TSMC 16-nanometer process and is actually a simplified version of Gaudi. The two main components of the chip are the TPC (Tensor Processor Core) and the GEMM (general matrix multiply) engine. The TPCs are the company ground up VLIW SIMD CPU/DSP design. Those cores are based on a custom VLIW ISA which features specialized AI SIMD vector instructions. One of the things Habana attempted to do the TPCs is to enable higher flexibility. The cores are fully C-programmable, they can implement any AI function necessary, and they support a whole array of mixed-precision data types including 8, 16, and 32-bit integer and floating-point operations. Using Habana’s software stack, coarse-grained and fine-grained control knobs are offered to control the accuracy of the hardware down to the tensor level. This is important for certain fields where you’d rather take a small performance hit but get slightly better accuracy. The full Goya chip features eight of those TPCs in a cluster. Along with the TPC cluster, the chip integrates a powerful GEMM (general matrix multiply) engine.
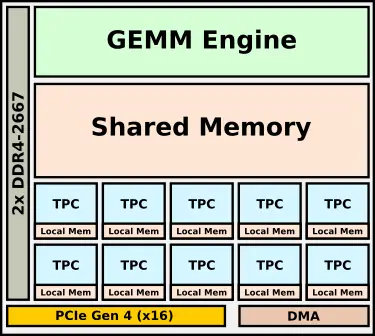
An interesting aspect of the chip is that the TPCs do not have local caches. Instead, they have a local chunk of scratchpad memory along with a large shared memory which is shared by both the GEMM engine and the TPCs. The caches can be managed by the software in order to optimize for lower data movement. This allows them to more easily stream data from the large pool of caches and improve the determinism of the TPCs. Habana says that most models should fit in the cache and be fully contained on-chip. For a larger pool of memory, feeding the chips are two channels of DDR4 memory with a total capacity of 16 GiB.
The Goya inference chip, HL-1000, is wrapped in a PCIe Gen 4 accelerator card. A couple of SKUs are offered. The difference being in cooling type offered (passive/active) and the card memory capacities which range from 4 to 16 GiB. Habana says cards have a max TDP of 200 W but we can expect typical power consumptions to usually be half that.

Gaudi
Gaudi is Habana’s microarchitecture for the acceleration of training. Like Goya, it’s also designed for TSMC 16-nanometer process and features a very similar architecture. The chip integrates eight TPCs in a cluster along with the GEMM engine. Since Gaudi was designed after Goya, Habana did manage to sneak in some new features. As far as data types supported, with the industry converging on bfloat16 as the preferred data type for training, Habana added support for it in Gaudi. In the TPCs and GEMM engines, Habana says it added some new ISA features and hardware capabilities to help accelerate some of the newer algorithms.
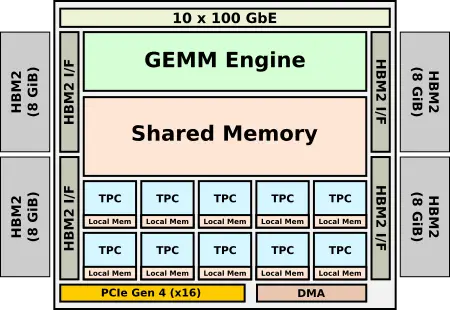
There are, however, a number of key differences. Gaudi was designed to allow for training at scale. Habana says high throughput at low batch size was one of their key requirements as they designed the chip. The other requirement is to go with standard ethernet as the communication medium. This is quite different from the proprietary interfaces such as Intel’s ICL link or Nvidia Nvlink used for their NPUs and GPUs. Habana wanted to give customers the freedom to use existing hardware and leverage standard Ethernet switches to scale instead of introducing and locking them into additional proprietary interfaces. To that end, Gaudi integrates 10 ports of 100 Gb Ethernet along with a RoCE RDMA. Additionally, since training needs higher bandwidth and a larger capacity memory, the dual-channel DDR4 interface was replaced by four HBM2 stacks and 32 GiB of memory.

Habana offers the HL-2000 Gaudi chip in two form factors – an OCP Accelerator Module and a standard PCIe card. Both form factors incorporate 32 GiB of HBM2 memory with a total bandwidth of 1 TB/s. Like Goya, the PCIe cards come in a number of cooling options.

Habana also offers a reference platform in order to allow customers who don’t want to bother designing their own boxes. The HL-1 packs eight Gaudi HL-205 OAM cards. The HLS-1 is a little unique in the fact that it actually has no CPUs. Habana installed the eight Gaudi chips and interlinked them together and then simply exposed connectivity to the outside world. There are 4 PCIe ports and 6 QSFP-DD ports exposed. Customers are free to choose the CPU type and ratio that best suits their workloads and connect them using the four Mini-SAS HD ports.

Goya HL-1000 inference chip has been shipping for close to a year. The Gaudi HL-2000 training chip is currently sampling. Habana is already working on its next-generation inference and training chips which will move to the 7-nanometer process.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–