
Intel Details Golden Cove: Next-Generation Big Core For Client and Server SoCs

In the last two years, Intel has jumped back into its yearly big core cadence. Last year the company rolled out Willow Cove, the successor to Sunny Cove which took better advantage of the underlying process technology to improve performance through frequency while consuming less power. This year, at Intel’s 2021 Architecture Day, the company is unveiling its next-generation big core successor – Golden Cove.
This article is part of a series of articles covering Intel’s 2021 Architecture Day:
- Intel’s Gracemont Small Core Eclipses Last-Gen Big Core Performance
- Intel Details Golden Cove For Next-Generation Client and Server CPUs
- Intel Unveils Alder Lake: Next-Generation Mainstream Heterogeneous Multi-Core SoC
- Intel Unveils Sapphire Rapids: Next-Generation Server CPUs
- Intel Introduces Thread Director For Heterogeneous Multi-Core Workload Scheduling
- Intel’s Mount Evans: Intel’s First ASIC DPU
- Intel Unveils Xe HPG – Discrete Graphics For Gamers
- Intel Unveils Xe HPC And Ponte Vecchio
Golden Cove is Intel’s next-generation performance core (P-Core). It is designed to go into everything from low-power mobile devices and scale all the way to their Xeon Server CPUs. Like its predecessor, this core does have various features that are only offered at their respective market segments.
High-Level Overview
Intel’s Golden Cove builds on the prior generation of the big core (i.e., Sunny Cove). While general-purpose performance was a key architectural goal, this core also introduced improvement for AI acceleration and security. Additionally, Intel added some new features that tackle some of the undesired behaviors of the prior cores, specifically in the area of AVX-512 and power management. A new power management controller was introduced into the core which is said to be able to capture and account for events in fine-grain granularity on the order of microseconds instead of milliseconds, controlling various power-performance knobs based on actual application usage.

For the data center, the Golden Cove core also supports the new Advanced Matrix Extension (AMX). In the current implementation, Golden Cove will support 2,048 int8 operations/cycle which is 8 times the operations/cycle of the AVX-512 VNNI extension found in the prior core (and this one).


Front-End Improvements
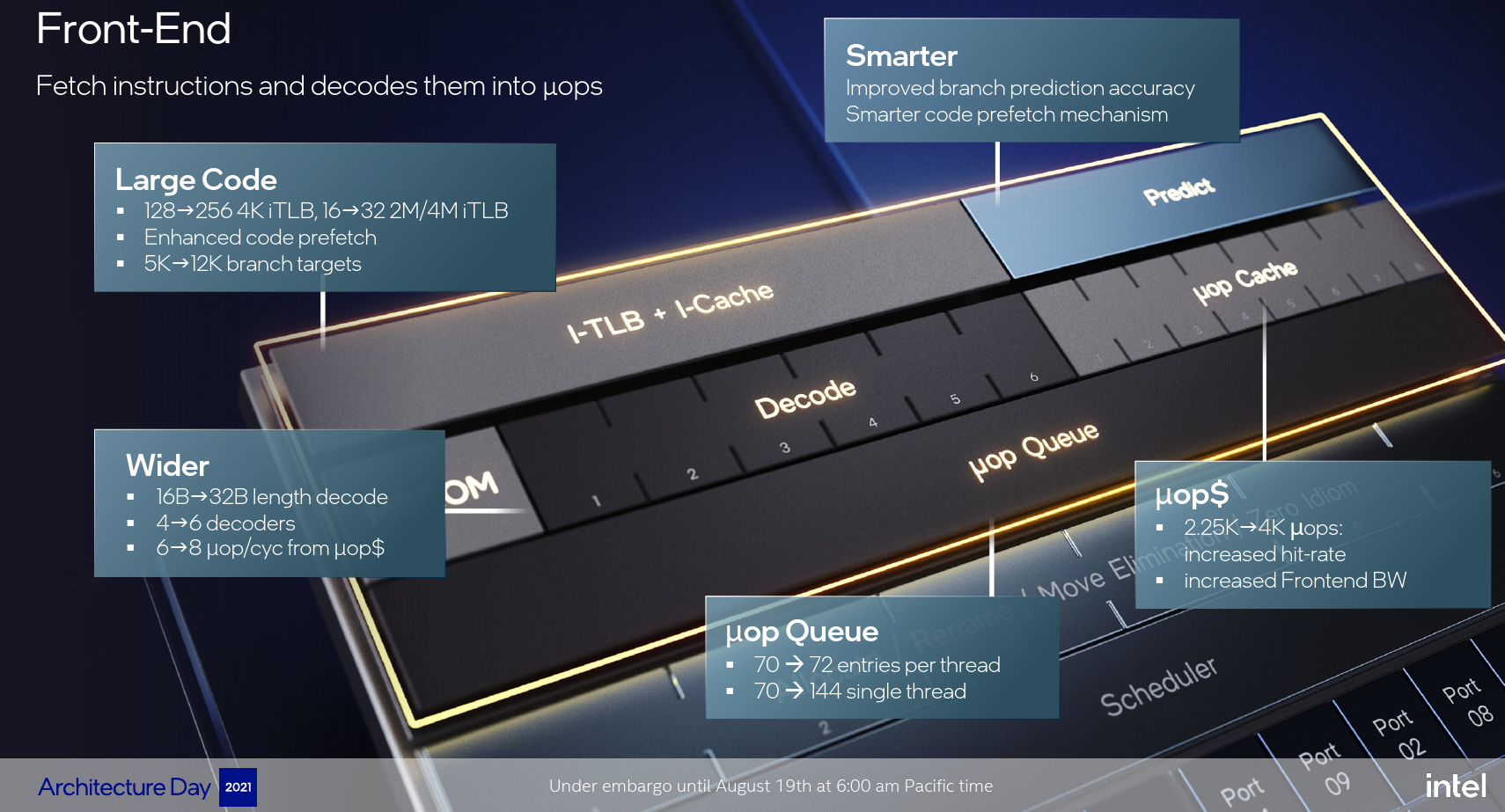
There are some really major changes in the Golden Cove microarchitecture. The front-end on Golden Cove is perhaps the biggest genealogical change in the microarchitecture going as far back as Sandy Bridge or even earlier. Although the cache itself is unchanged, Golden Cove can now fetch 32 bytes each cycle, doubling the fetch bandwidth versus all prior cores (I believe all the way back to the original P6). The higher bandwidth was necessitated by the largest change in the code – the decoders. Golden Cove is now 50% wider than all previous cores, adding 2 additional decoders for a total of six.
To complement that higher fetch and decode bandwidth from the MITE path, the DSB path was also enlarged. Intel nearly doubled the micro-op cache to 4K and increased the delivery bandwidth by a third – from 6 μOPs/cycle to 8 μOPs/cycle.
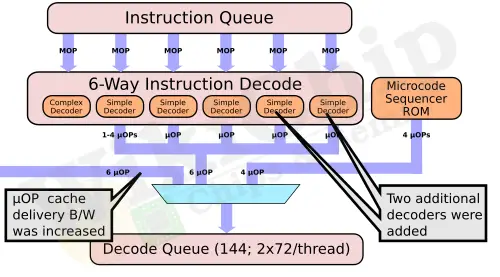
Golden Cove has some additional page capacity for large software code. Here Intel doubled the number of 4K pages and 2M/4M pages to 256 entries and 32 entries respectively. The branch predictor on Golden Cove is also said to have improved. One of the changes that were made was in its internal buffer capacities. Golden Cove features a BTB that’s almost 2.5x the prior generation at 12K entries. Intel says that an AI model is used to dynamically grow or shrink its active size based on the running workload in order to save on power by shutting off excess capacity when not needed – or alternatively – enable extra capacity in order to improve performance.
Backend Improvements
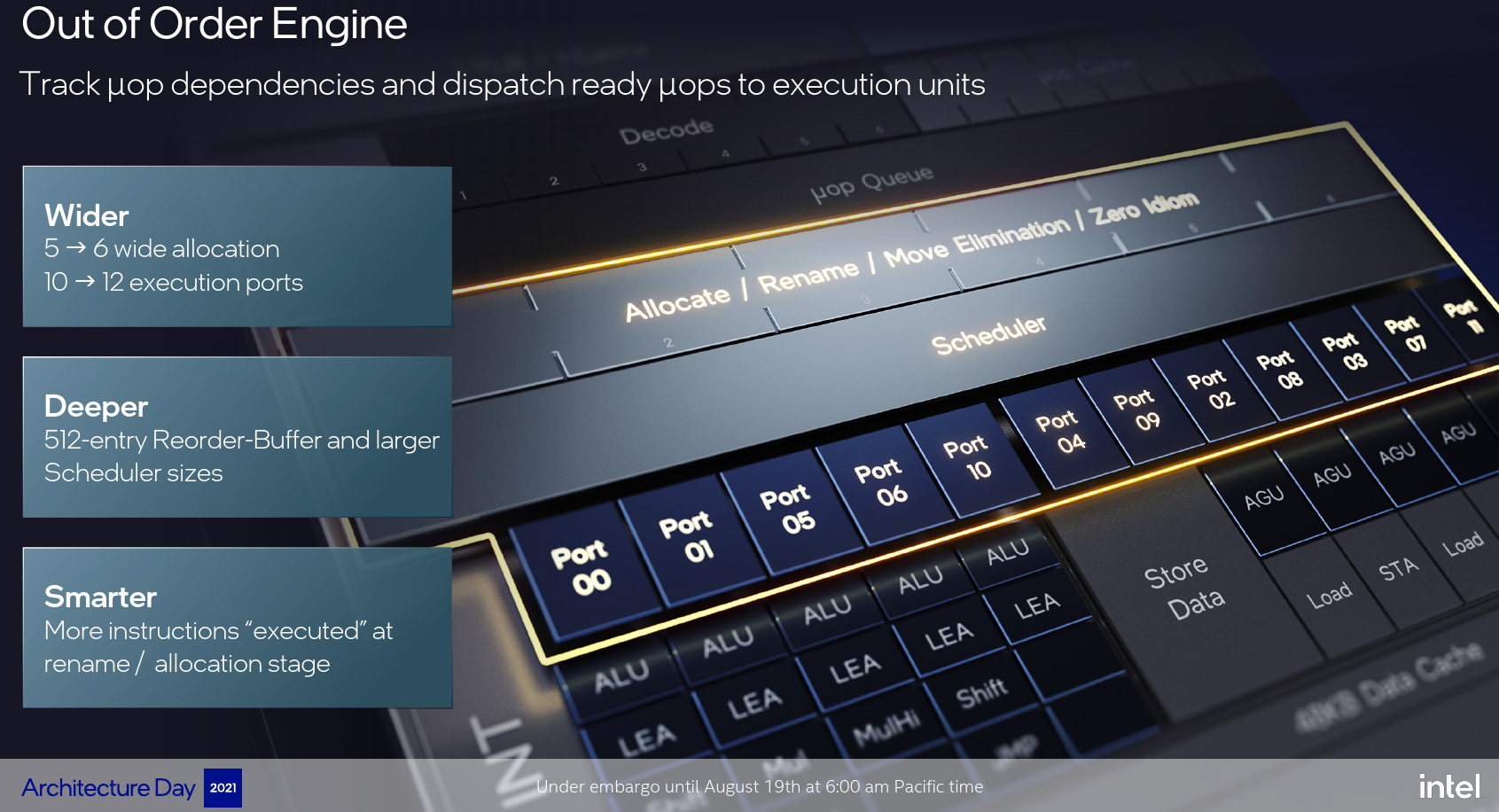
The back end of Golden Cove was enhanced alongside the front end. As with the fetch bandwidth and decode bandwidth, the allocation stage on Golden Cove was also widened to a 6-wide allocation. Intel also added two new execution ports to the scheduler for a total of 12 ports.
To accommodate a larger out-of-order window, Intel increased the ROB size by nearly 50% to a whopping 512-entry ROB. The jump from Sunny Cove to Golden Cove is an increase of 160 entries – nearly the entire ROB size of Sandy Bridge. The actual scheduler size and physical register files were also increased, however, Intel chose to not disclose their exact sizes at this time. One of the interesting additions to the rename/allocate stage is the introduction of a new mechanism that allows for the execution of ‘simple instructions’ during the rename/allocate stage such that they collapse lengthy dependency chains. Intel says this feature saves on resources down the execution pipe while reducing power and enabling higher instruction-level parallelism.
| Intel Microarchitecture ROB Size | |||
|---|---|---|---|
| Intro | uArch | ROB | 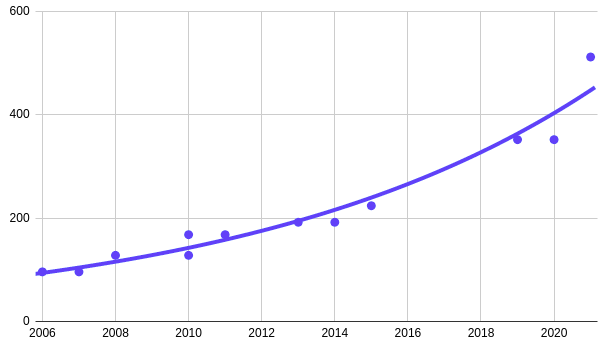 |
| 2006 | Core | 96 | |
| 2007 | Penryn | 96 | |
| 2008 | Nehalem | 128 | |
| 2010 | Westmere | 128 | |
| 2010 | Sandy Bridge | 168 | |
| 2011 | Ivy Bridge | 168 | |
| 2013 | Haswell | 192 | |
| 2014 | Broadwell | 192 | |
| 2015 | Skylake | 224 | |
| 2019 | Sunny Cove | 352 | |
| 2020 | Willow Cove | 352 | |
| 2021 | Golden Cove | 512 | |
Execution Engine
On the execution engine side, Intel added a 5th integer pipeline with a 5th ALU and a 5th LEA. All five ports support single-cycle LEA operations for general-purpose arithmetic calculations. The LEA on port 10 is said to be able to also do scaled operations in a single cycle similar to the LEA on ports 1 and 5.

On the floating-point side, Intel added new fast adders (FADD) on ports 1 and 5. The new FADDs have 3-cycle latency with a 2-cycle latency bypass for back-to-back FP add operations. Intel says that previously, those operations were 4 cycle when executed on port 0 and 1 and 6 cycle when executed on port 5. Golden Cove also introduced support for FP16 data type in AVX-512 mode along with new complex number support.

Memory Subsystem
On the memory subsystem side of Golden Cove, Intel added a new Port 11 with a third load AGU. Golden Cove now supports up to 3 loads per cycle and up to 3 256b loads/cycle while maintaining the previous 2x512b loads for 512b operations. To expose more memory parallelism, the load and store buffers were also enlarged. Intel said it has added more cases where store data operations are directly passed to a load, with improved latency.
Intel increased the data TLB by 50% to 96 entries. They also increased the fill buffer to 16 to support more misses. Additionally, the new core supports twice as many simultaneous page walks (from 2 to 4).

Because Golden Cove goes into two distinctly different markets – client and server – the L2 cache and memory subsystem has two different optimization points. For the client market, Golden Cove features a 1.25 MiB L2 cache optimized for better latency while the server market enjoys a larger capacity 2 MiB of private L2. The number of simultaneous cache misses that can be handled in parallel has been increased from 32 to 48. In says that a new feedback-based prefetcher has been developed for Golden Cove. The new prefetcher is said to observe the instruction stream and generate estimation for the likelihood of future memory access patterns. This, in turn, is used to identify multiple potential future sequences and operate on multiple future prefetch paths while taking into account their estimated likelihood.

Performance Claims
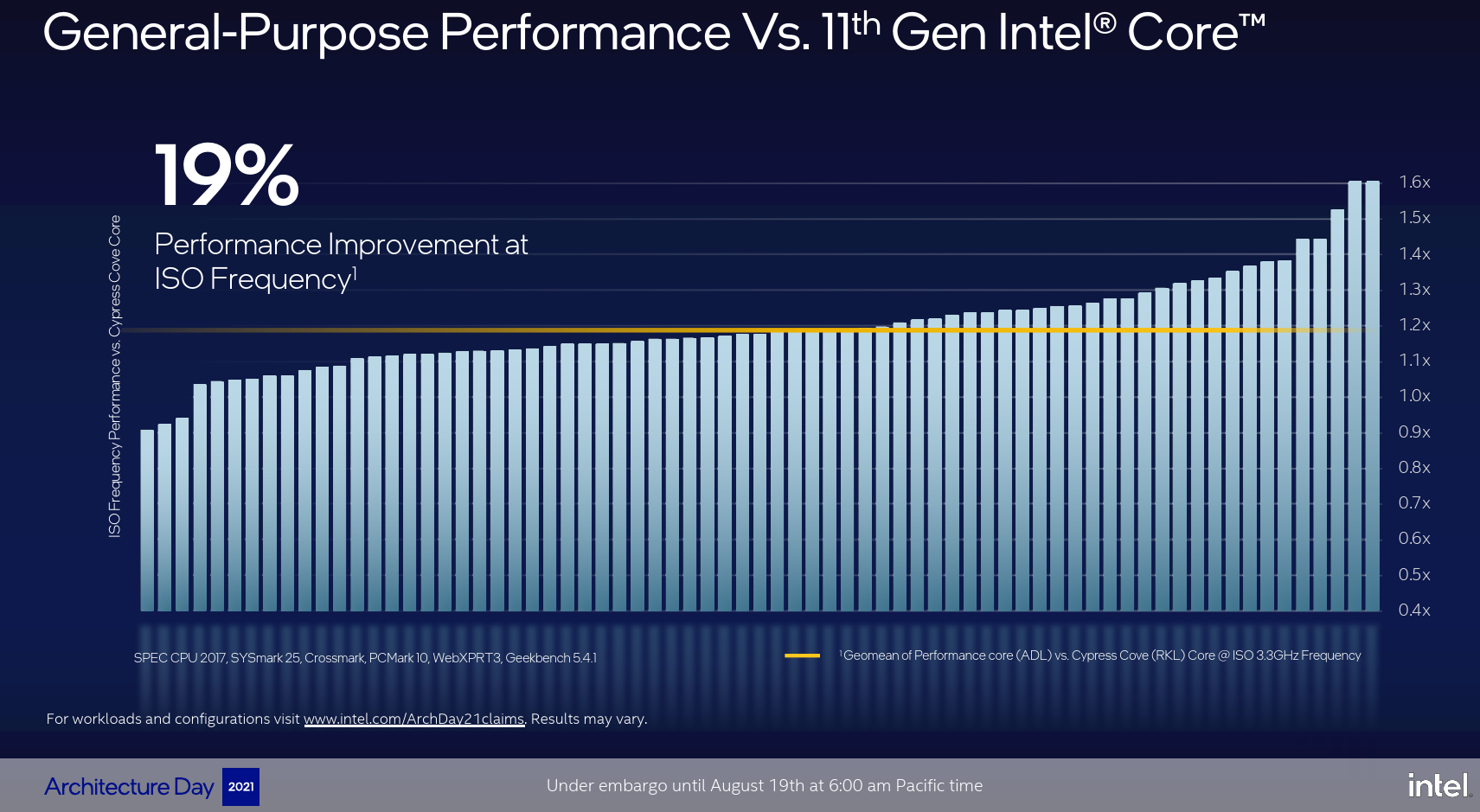
All in all, Intel says that Golden Cove achieves nearly 20% improvement in IPC versus Sunny/Cypress Coves. This is based on the geomean of an array of benchmarks including SPEC CPU 2017, SYSmark 25, Crossmark, PCMark 10, WebXPRT3, and Geekbench 5.4.1. “This level of improvement is even larger than what we delivered with the Sunny Cove cores over the Skylake cores,” said Adi Yoaz, Chief Architect of Golden Cove.
This article is part of a series of articles covering Intel’s 2021 Architecture Day:
- Intel’s Gracemont Small Core Eclipses Last-Gen Big Core Performance
- Intel Details Golden Cove For Next-Generation Client and Server CPUs
- Intel Unveils Alder Lake: Next-Generation Mainstream Heterogeneous Multi-Core SoC
- Intel Unveils Sapphire Rapids: Next-Generation Server CPUs
- Intel Introduces Thread Director For Heterogeneous Multi-Core Workload Scheduling
- Intel’s Mount Evans: Intel’s First ASIC DPU
- Intel Unveils Xe HPG – Discrete Graphics For Gamers
- Intel Unveils Xe HPC And Ponte Vecchio
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–