
Intel Sunny Cove Core To Deliver A Major Improvement In Single-Thread Performance, Bigger Improvements To Follow
With mobile Ice Lake processors shipping today, Intel is disclosing the final pieces of information about their new Sunny Cove cores.
Overview
The front-end of Sunny Cove is quite similar to Skylake. Depending on the source of the µOP, Sunny Cove can deliver 4, 5 or 6 micro-ops to the back-end. Up to 5 µOP may be delivered from the decoders with up to 6 µOP possible from the µOP cache which stores pre-decoded operations. On Sunny Cove, Intel increased the µOP cache by 50%. It can now store up to 2.25K µOPs. The branch predictor has also been improved from Skylake.
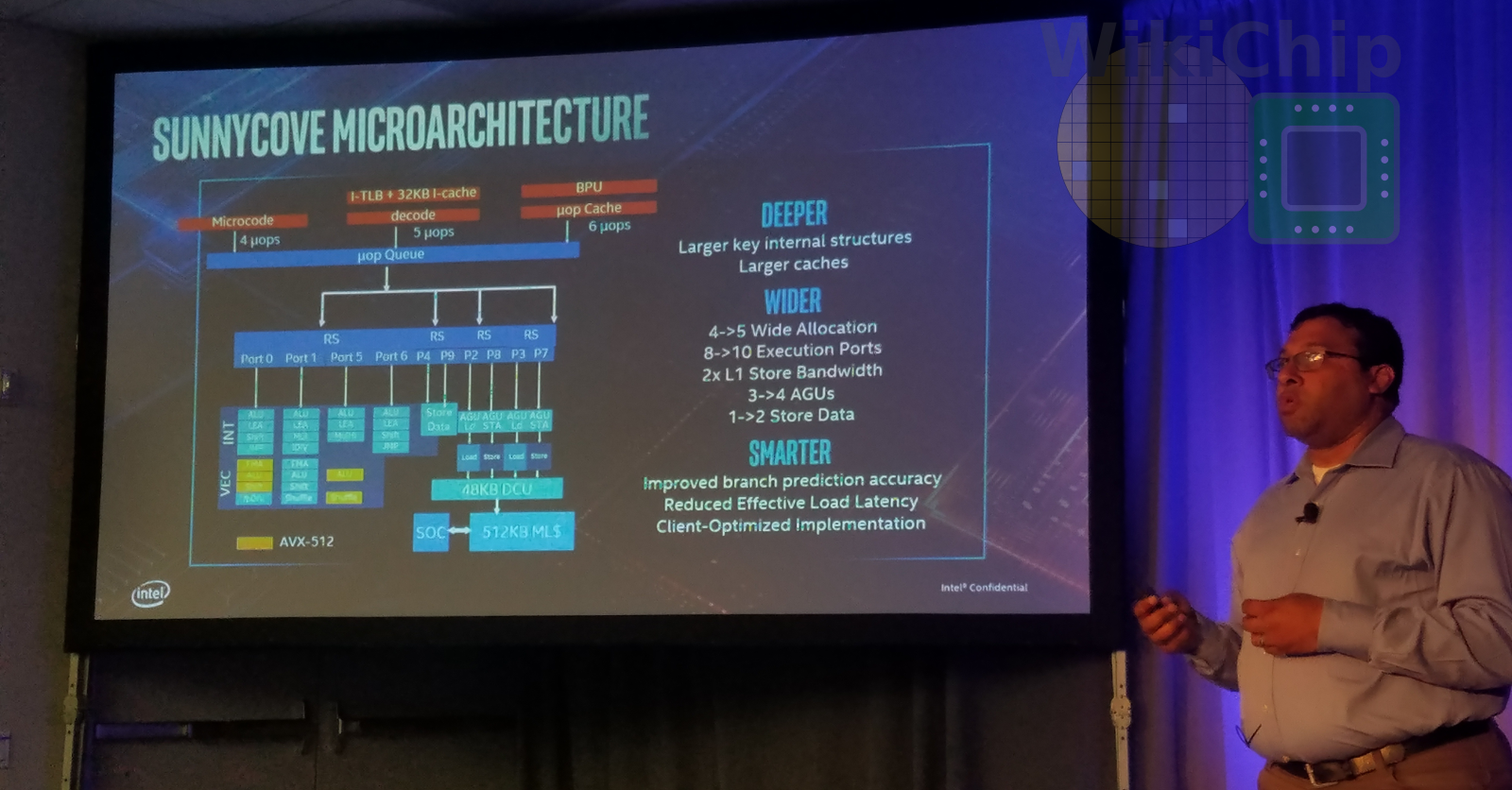
The major improvements can be found in the back-end of the machine which is now wider and deeper. Sunny Cove can now allocate up to five µOPs each cycle and send up to 10 µOPs for execution each cycle, an increase of 1.25x for both.
AVX-512
What’s new with Ice Lake U and Y specifically is the introduction of AVX-512 in this segment of the market (note that there is a single Cannon Lake chip that also features AVX-512 but has never made it to mass production). The AVX-512 implementation in mobile Ice Lake chips is optimized for the power levels available on a laptop. In other words, the implementation here differs from the one found in the Ice Lake server parts. On those parts, you can do one 512-bit or two 256-bits FMA operations.
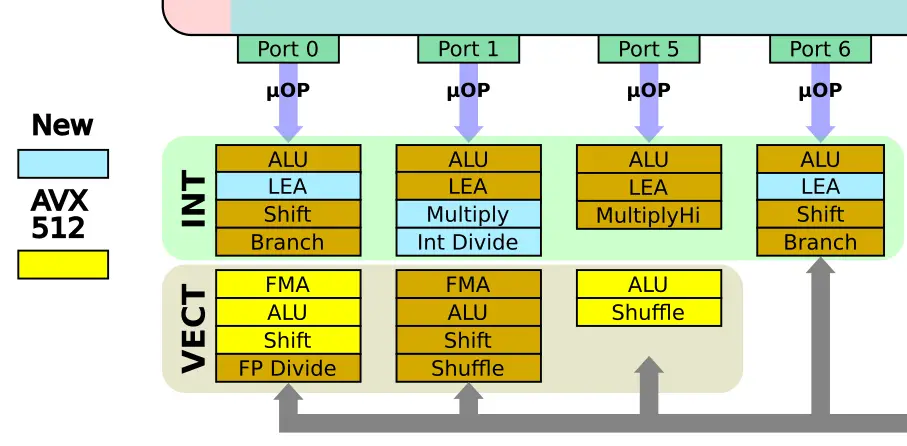
Caches
The level 1 data cache on Sunny Cove has grown to 48 KiB. This is the first time Intel has increased the L1 cache in over a decade. Sunny Cove also doubled the second level cache from 256 KiB to 512 KiB. Along with this Intel also increased the TLB sizes. The previously shared 4K and 2M/4M L2 TLB has been split up into a 4K L2 page table and a 2M/4M table.
| Intel Microarchitecture Cache Comparison | |||
|---|---|---|---|
| Component | Haswell | Skylake | Sunny Cove |
| L1D Cache | 32 KiB | 32 KiB | 48 KiB |
| L2 Cache | 256 KiB | 256 KiB | 512 KiB |
| L2 TLB | 1024 | 1536 16 (1G) |
2048 (4K) 1024 (2M/4M) 1024 (1G) |
| µOP Cache | 1.5K µOPs | 1.5K µOPs | 2.25K µOPs |
OoO Window
Sunny Cove overhauled the core microarchitecture in order to extract significantly more single-thread performance for existing code. Intel increased the reorder buffer by over 50% from 224 entries in Skylake to 352 entries in Sunny Cove. Likewise, the amount of inflight loads and stores has been increased by over 50% to 200 memory operations inflight.
| Intel Microarchitecture Cache Comparison | |||
|---|---|---|---|
| Component | Haswell | Skylake | Sunny Cove |
| ROB | 192 | 224 | 352 |
| In-flight loads | 72 | 72 | 128 |
| In-flight stores | 42 | 56 | 72 |

IPC Claims
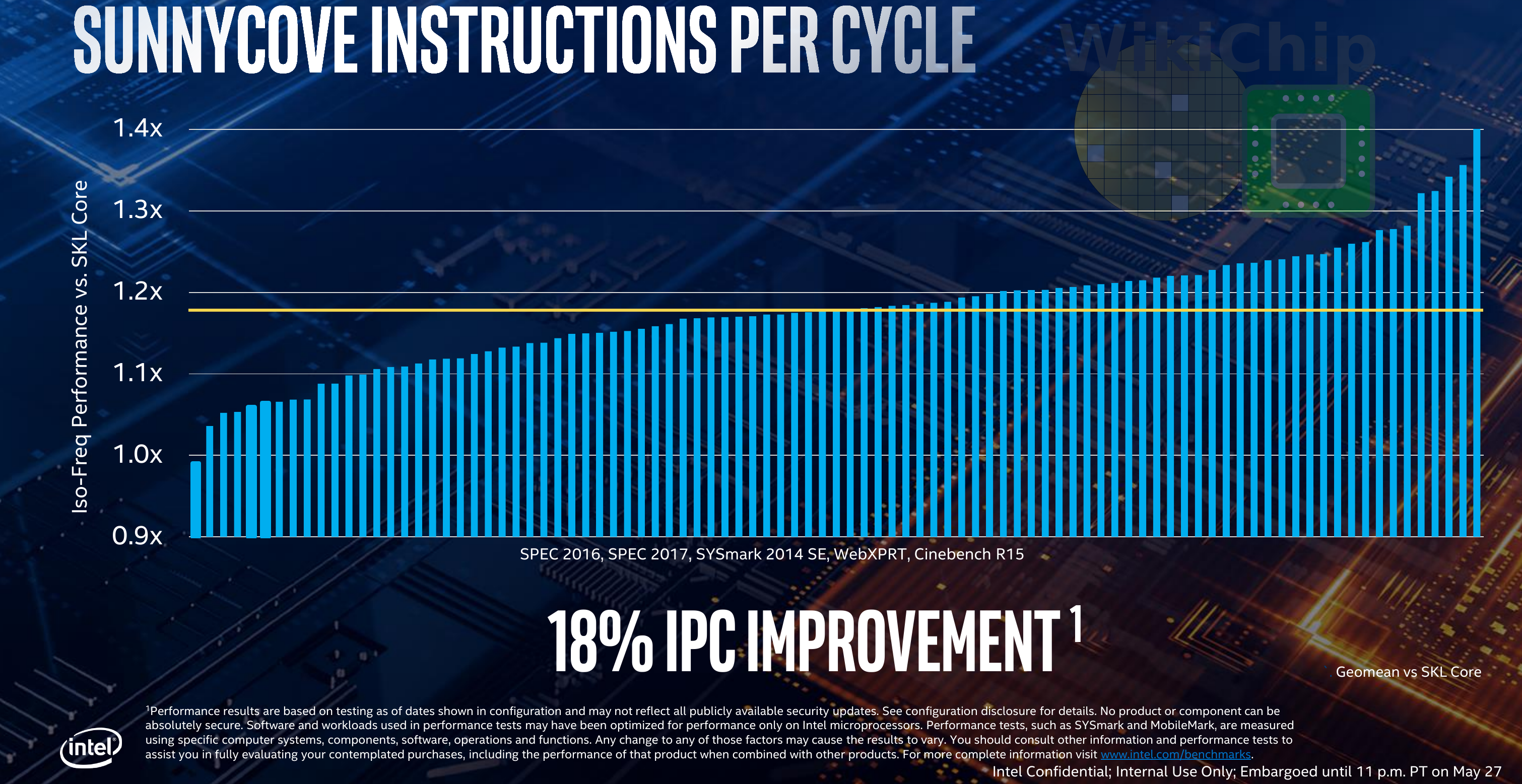
What do all of those changes amount to? For out-of-the-box performance, compared to the Skylake core, at the same frequency, same memory bandwidth, and same binaries, Intel is claiming an average of 18% increase across a range of proxy workloads such as SPEC 2006, SPEC 2017, SYSmark 2014 SE, WebXPRT, and Cinebench R15. “The last time we have had something in this range was during the Merom era,” Ronak, Intel Chief Core Architect, said. He added,
I have had some of you ask me, “can you actually push the IPC further anymore or are we running out of steam doing this?” And the answer is: No. And Sunny Cove is one example of this. The other microarchitectures we are working on back at home will go even beyond this. Sunny Cove is the foundation for our next wave of innovation.
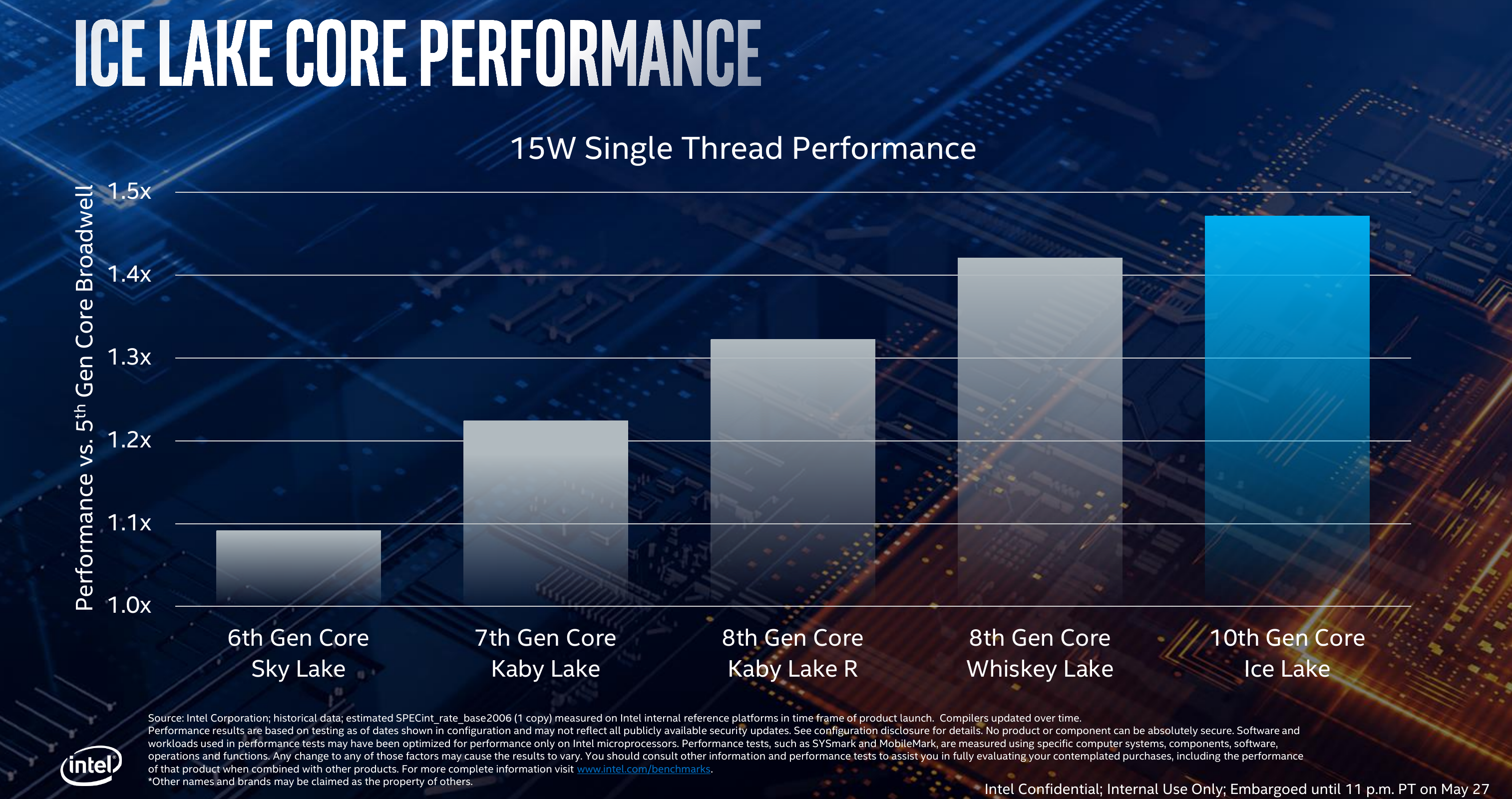
Update: Our original story erroneously reported that Ice Lake supported one 512-bit AND a 256-bit FMA operation at once. It is actually one 512-bit OR 2 256-bit FMA operations at once. We apologize for the mistake.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–