
ISSCC 2018: AMD’s Zeppelin; Multi-chip routing and packaging
![]() At last last year’s conference, AMD presented the voltage regulation and power management of their Zen core. This year, at the 65th International Solid-State Circuits Conference (ISSCC), AMD was back to talk about their multi-chip architecture – particularly as far as communication, routing, and packaging is concerned. The paper was presented by Noah Beck, SoC Architect at Advanced Micro Devices, Inc.
At last last year’s conference, AMD presented the voltage regulation and power management of their Zen core. This year, at the 65th International Solid-State Circuits Conference (ISSCC), AMD was back to talk about their multi-chip architecture – particularly as far as communication, routing, and packaging is concerned. The paper was presented by Noah Beck, SoC Architect at Advanced Micro Devices, Inc.
This article assumes the reader is familiar with AMD’s recent “Zen” core and the concept of a “CPU Complex” (CCX). As a refresher, we recommend skimming through our Zen microarchitecture article.
A few years ago, when AMD was well into the development of the Zen x86 core, they were confronted with a problem. On the one hand, they needed a mainstream PC processor; but on the other, enterprise customers were asking for a step-function increase in core count for the server market. What they came up with is “Zeppelin”, an SoC designed from scratch that incorporates the Zen core for multi-chip architectures. The Zeppelin SoC was flexible enough to allow AMD to develop three processor families – EPYC for servers, Ryzen for desktop, and Ryzen Threadripper for the HEDT market.
Zeppelin
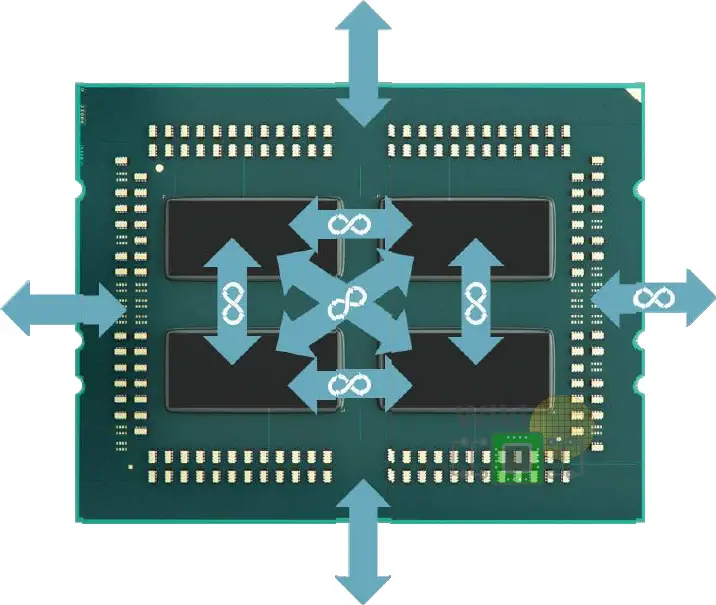
Below is the Zeppelin die with the main functional areas labeled.
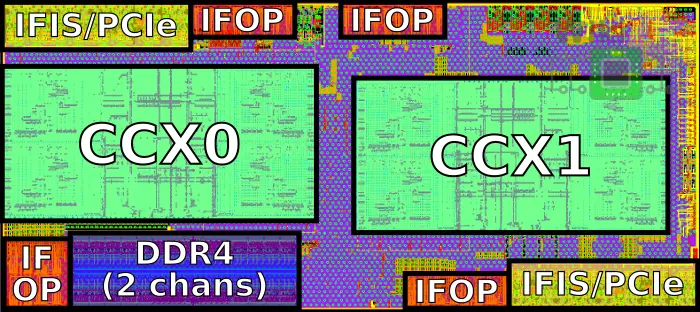
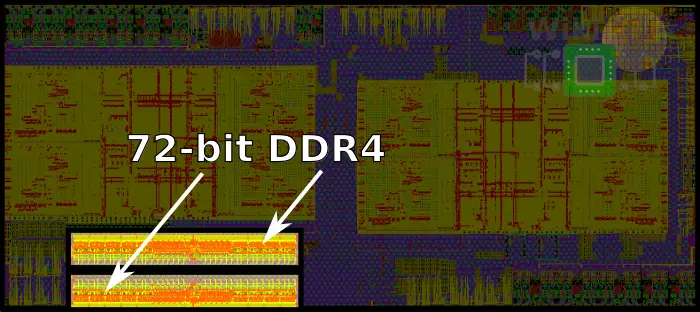
The Zeppelin SoC has two DDR4 channels with ECC support, each channel supporting up to 256 GiB of memory. Those are located at the bottom left corner of the die.
At the bottom-right and top-left corner of the die are x16 lane SerDes for a total of x32 lanes. On those SerDes AMD MUX’ed the Infinity Fabric InterSocket (IFIS) protocol with PCIe Gen 3.

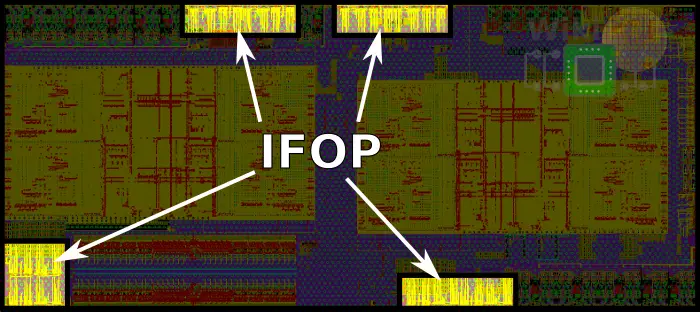
For communication between dies on the same substrate, there are four Infinity Fabric On-Package (IFOP) SerDes with two located at the top of the die and the other two at the bottom.
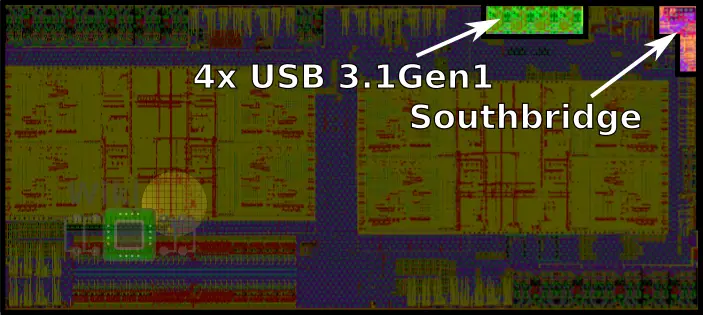
On the upper-right side of the die are four USB 3.1 Gen1 ports. Additionally, the entire southbridge is also located on the upper-right corner which AMD calls the Server Controller Hub (SCH) which supports all the lower-speed interfaces such as SPI, LPC, UART, I2C, and SMBus. The SCH also includes the real-time clock (RTC).
Infinity This and Infinity That
It seems that someone at AMD’s marketing had a little too much fun and decided to name just about every bus they could find on the chip the “Infinity Fabric“.
Marketing aside, the Infinity Fabric can be broken down into its constituent parts – the Scalable Data Fabric (SDF) and the Scalable Control Fabric (SCF). This article focuses on the Scalable Data Fabric (SDF) plane which deals with data traffic. It does not cover the SCF plane.
Below is the diagram of the Zeppelin with the key communication blocks.
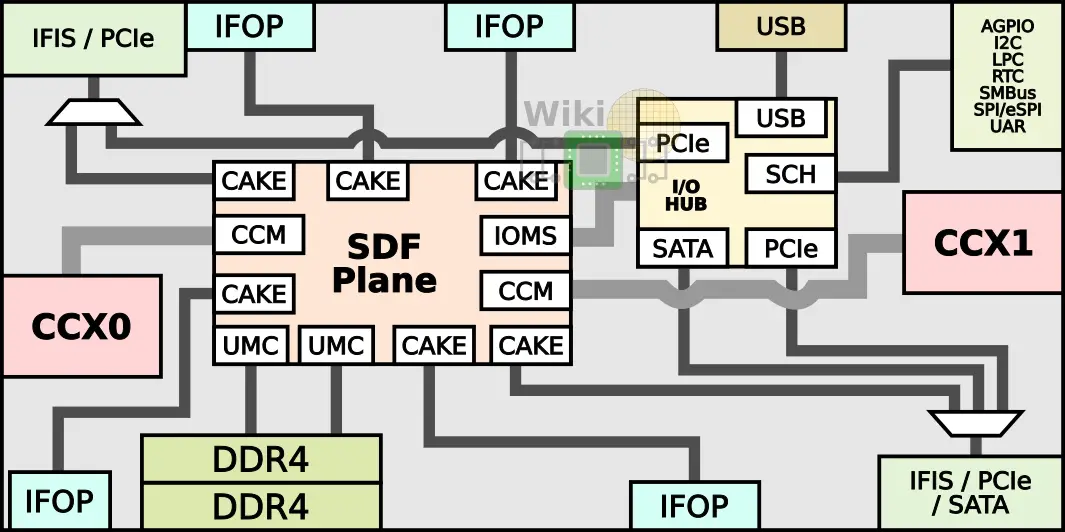
The two CCX’s are directly connected to the SDF plane using the Cache-Coherent Master (CCM) which provides the mechanism for coherent data transports between cores. There are two Unified Memory Controllers (UMC) for each of the DDR channels.
The SDF plane also features a single I/O Master/Slave (IOMS) interface for the I/O Hub communication. The Hub contains two PCIe controllers, a SATA controller, the USB controllers, and the southbridge.
The workhorse mechanism behind AMD’s multi-chip architecture is the Coherent AMD socKet Extender (CAKE) module which encodes local SDF requests onto individual packets each cycle and ships them over any SerDes interface. In total, there are six CAKEs – four for the IFOPs and two for the IFISs. Note that the IFIS CAKEs are actually multiplexed with the PCIe controllers and for one of the ports, there is also a SATA controller MUX’ed onto it as well. The I/O subsystem muxing is discussed in more detail later on.
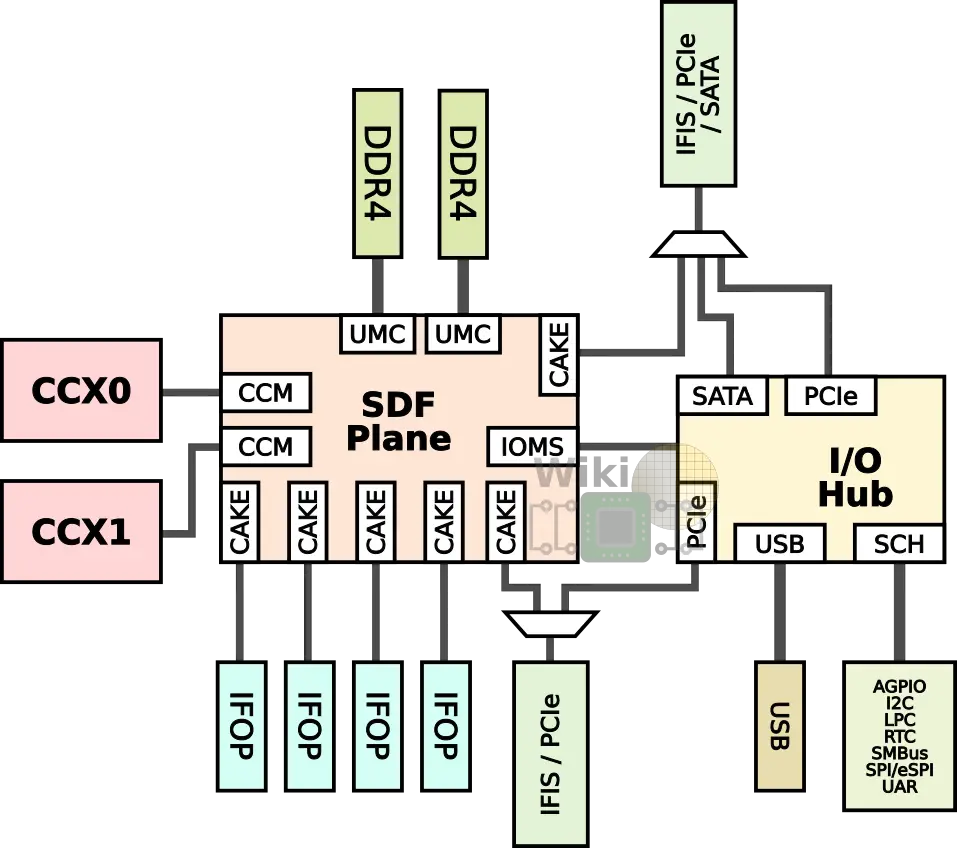
It’s worth noting that all SDF components run at the DRAM’s MEMCLK frequency. For example, a system using DDR4-2133 would have the entire SDF plane operating at 1066 MHz. This is a fundamental design choice made by AMD in order to eliminate clock-domain-crossing latency.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–