
ISSCC 2018: AMD’s Zeppelin; Multi-chip routing and packaging
Package
The Zeppelin floorplan was carefully designed and optimized for package routing and cost. Zeppelin was designed to scale across all market segments: Server, Desktop, and HEDT. For the server market, AMD designed a 4-Zeppelin-die multi-chip module that went into a new server socket infrastructure they called SP3. For the high-end desktop (HEDT) market, AMD designed a 2-Zeppelin-die multi-chip module that went into a new HEDT socket infrastructure called sTR4 (SocketTR4). For the desktop market, AMD used a single Zeppelin die that went into their existing socket infrastructure called AM4.
Note that although sTR4 and SP3 have similarly looking packages, the mechanical and electrical characteristics of the two are different. They also differ in how the dies are routed internally.
AMD uses a flip-chip package for their chips, meaning the die is flipped with the active side facing the substrate. All images shown in this section are of the die and the traces on the package substrate are of the die facing down with the user viewing it from above.
SP3
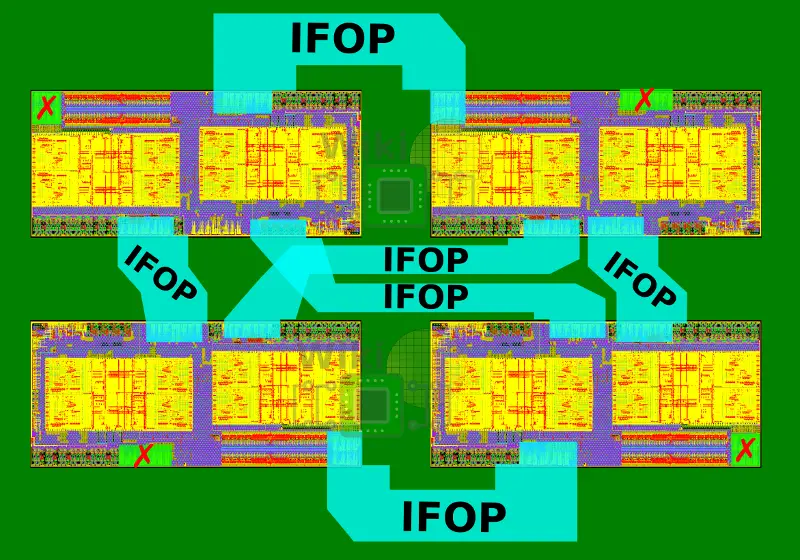
The SP3 package uses a 4-Zeppelin configuration with 8 DDR4 channels and 128 PCIe Gen3 lanes. The SP3 package is an organic substrate land grid array (LGA) with 4,094 contacts measuring 58mm by 75mm. This package was also designed to scale to a 2-socket system.

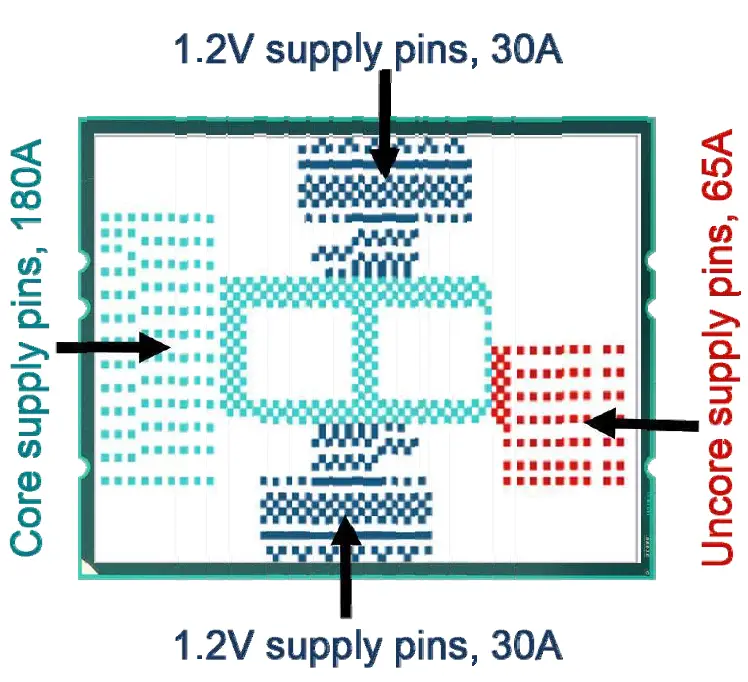
Below are the four power rails with the package contacts marked. SP3 supports up to 300 A current and up to 200 Watt of TDP. There is also about 300 μF of on-package capacitors.
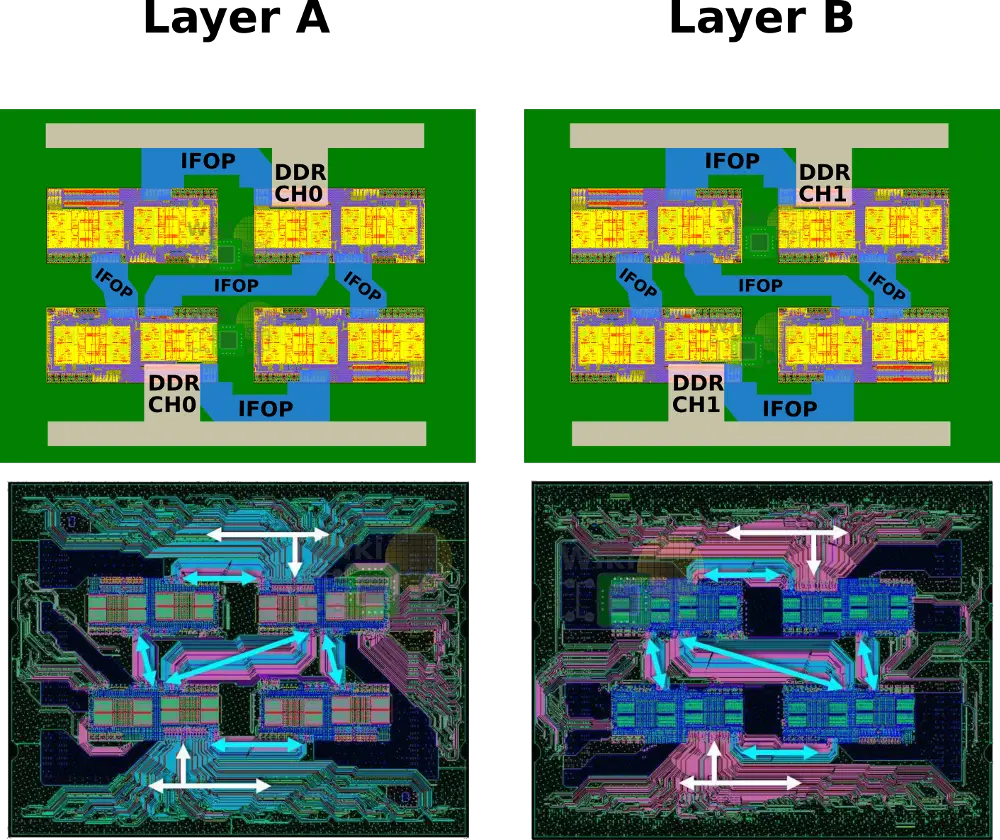
The main problem was dealing with the escape routing of the DDR4 channels from each die. The way this was solved is by placing the channels on the bottom-left corner of the die so that all the DDR channels are facing the package left and right edges. Note that two of the dies are rotated 180 degrees for this. This was done in order to prevent the need to route the DDR channels underneath the die. Within the package, the IFIS links have to be pinned-out at the package left and right sides while the DDR is routed to the top and bottom.
Two layers are needed for the routing of the IFOPs. On Layer A is the routing for a single DDR channel from the two diagonal Zeppelins and a single diagonal IFOP routing. On Layer B is the routing for the second DDR channel from the same two diagonal Zeppelins and the other cross-diagonal IFOP routing.
Two additional layers are needed for the routing of the IFIS. On Layer C is the routing for a single DDR channel from the two remaining Zeppelins and half of the routing of the IFIS links. On Layer D is the routing for the second DDR channel of the same Zeppelins and the other half of the routing of the IFIS links.
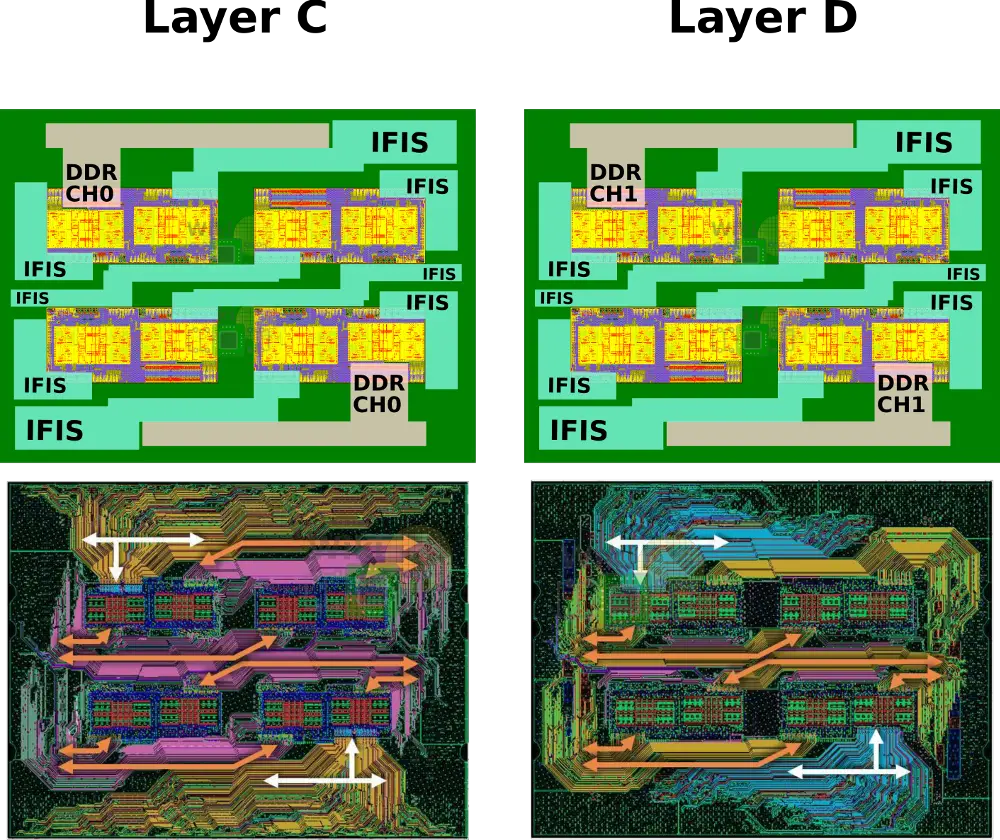
It’s worth pointing out that for full connectivity, a Zeppelin really only requires three IFOP links. AMD chose to add a fourth IFOP link in order to be able to fit all the necessary routing in just four substrate layers. This means a single link per die does get wasted in favor of considerable packaging simplification.
sTR4
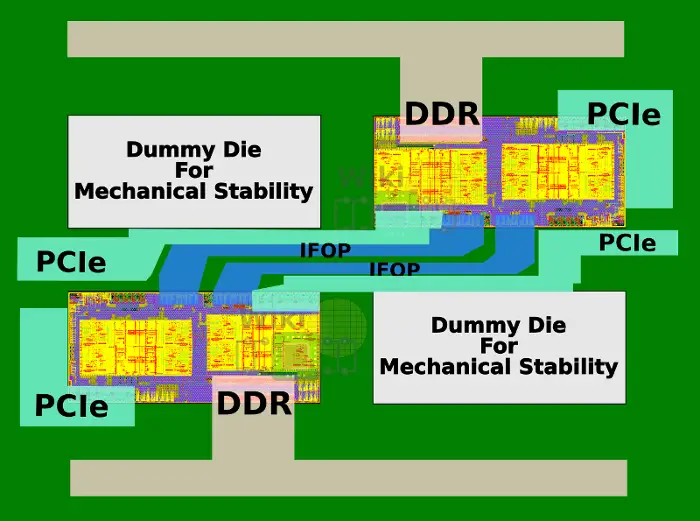
For the HEDT market, the sTR4 package is used. For this, two Zeppelins SoCs are used for a total of 16 cores and 32 threads along with four DDR4 channels. Though the package may look the same, the mechanical and electrical characteristics of the two are different. The two diagonal dies are dummy silicon used for the structural stability of the package.

In the two-die configuration, AMD actually links the two Zeppelins together using two IFOP links for higher bandwidth. With each die providing 2×16 lanes, those chips have a total of 64 PCIe Gen 3 lanes.
AM4
For the mainstream desktop AMD chose to continue with the same AM4 socket infrastructure they’ve used since prior generation. This is probably at least part of the reason why 24 PCIe lanes are offered despite the fact that the chip could offer 32 lanes. In this package, there is a single Zeppelin die which provides 24 PCIe lanes and 2 DDR4 channels. AMD uses 4 of those PCIe lanes for their chipset, extending the I/O capabilities of the system.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–