
IBM Introduces Next-Gen Z Mainframe: The z15; Wider Cores, More Cores, More Cache, Still 5.2 GHz

On Thursday IBM unveiled their new mainframe, the z15. Overall, the z15 represents an evolutionary change over its predecessor, the z14. However, there are plenty of enhancements across the board.
High-Level Changes
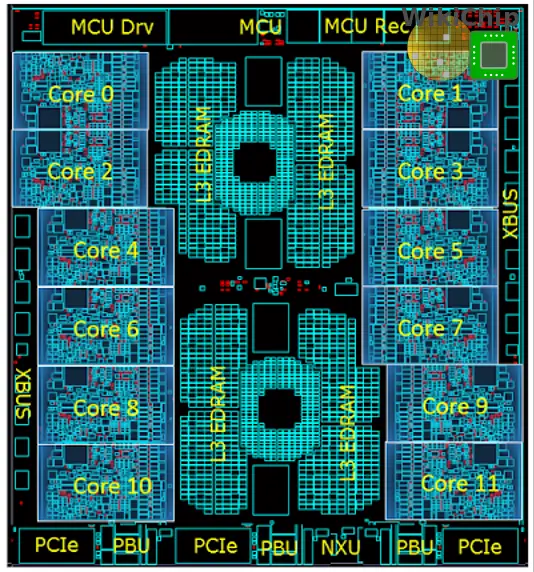
At the system level, IBM continues to use central processor complex (CPC) drawers which incorporate the processors, memory, and I/O interconnects. A drawer on the z15 comprises two logical CP clusters and one SC. The split cluster design is intended to improve memory traffic. This is the same design as the z14. However, the similarities stop here. On the z14, a single drawer comprises six central processors and a single system controller chip. Within a drawer, everything is fully connected via the X-Bus.
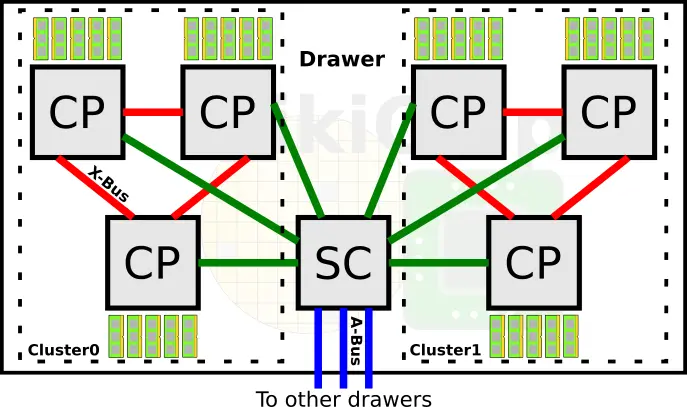
On the z15 IBM scaled back on the number of central processors. There are now four processors and a single SC chip per drawer. We will get as to why we believe IBM made this change later on. Within a drawer, everything is still fully connected via the X-Bus. Each processor is connected to the other processor within a cluster as well as to the SC chip.
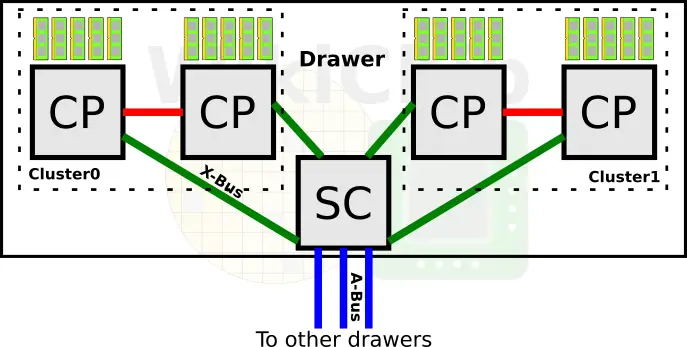
The change from six to four central processors is an interesting one. We will touch on the z15 processor in more detail late in this article but for now, we want to point out that the z15 has twelve cores per processor, two more than the z14. This means that in total, the z15 drawer has 48 cores while the z14 had 60 cores. As far as memory channels are concerned, this has not changed from the z14. There are five channels per CP for a total of 20 channels per CPC Drawer.
Taking another step back, the full z15 system configuration supports one additional drawer compared to the z14. With up to five CPC Drawers, IBM can compensate for the reduced processor count per drawer and offer up to 190 cores or 380 threads (note that the system is overprovisioned for redundancy). Note that the max z14 configuration was capped at 170 cores so you are looking at roughly 12% more cores on the new system. By the way, the usable memory has also increased from 32 TiB to 40 TiB. Communication inter-drawer is done over the A-Bus just like in the prior architectures. With four drawers, the SC on the z14 only needed three A-Bus links. On the z15, IBM added a fourth A-Bus link in order to fully connect every drawer to every other drawer.


z15 Central Processor
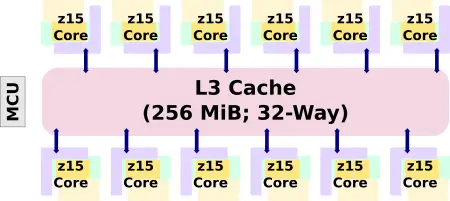
The overall architecture of the chip itself is very similar to the z14. Each core has a private L1 and L2. There is a massive L3 cache that is shared by all the cores. IBM increased the core count by 2 from 10 to 12. The L3 cache has been doubled to a whopping 256 MiB.
| L3 Cache Comparison | ||||||
|---|---|---|---|---|---|---|
| uArch | z12 | z13 | z14 | z15 | ||
| Capacity | 48 MiB | 64 MiB | 128 MiB | 256 MiB | ||
| Organization | 12-way | 16-way | 32-way | 32-way | ||
| Line Size | 256 B | 256 B | 256 B | 256 B | ||
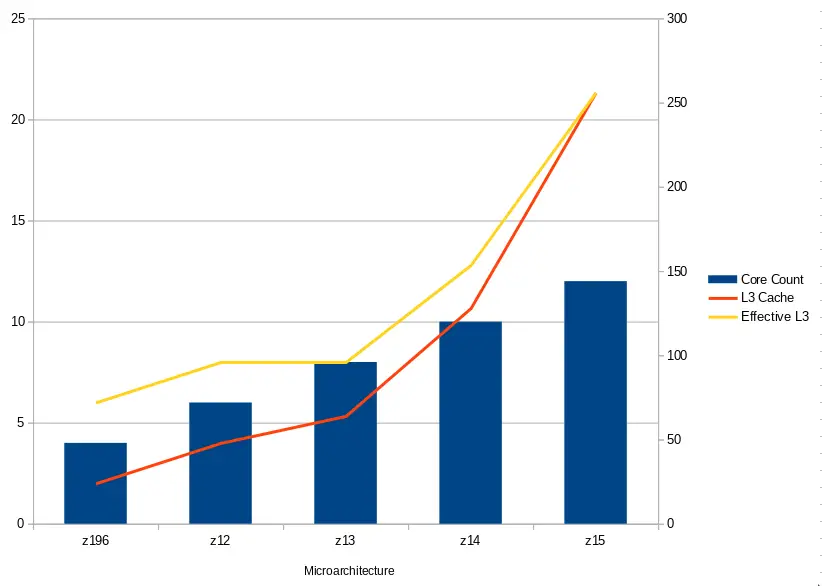
Another way to compare the cache size is by ratio to core count. The z15 nearly doubles the effective per-core L3 cache.
| L3 Cache Comparison | ||||||
|---|---|---|---|---|---|---|
| uArch | z196 | z12 | z13 | z14 | z15 | |
| Core Count | 4 | 6 | 8 | 10 | 12 | |
| Capacity | 24 MiB | 48 MiB | 64 MiB | 128 MiB | 256 MiB | |
| Effective per-core capacity | 6 MiB | 8 MiB | 8 MiB | 12.8 MiB | 21.33 MiB | |
Back in July 2013, IBM introduced the IBM zEnterprise Data Compression (zEDC) card. With the large L3 cache, IBM decided to move the Nest Acceleration Unit (NXU) on-chip. Because the NXU is on-chip, it can perform compression directly in the L3 cache, removing the I/O bottleneck. IBM is claiming up to 17 times the throughput compared to the old zEDC card with up to 260 GB/sec of compression throughput.
z15 Core – Wider, IPC Uplift
The z15 CPU improves on the prior z14. They are still manufactured on GlobalFoundries 14-nanometer using 17 metal layers. This is still 14HP, a special FinFET on SOI process that was co-designed by IBM and GlobalFoundries. Interestingly, although the z15 die is identical in size to the z14, at almost 700 mm², IBM has managed to pack 3 billion more transistors – 9.1 billion transistors in total. Late in this article, we will explain the magic.
Like its predecessor, the z15 operates at up to 5.2 GHz – but now with two more cores. Compared to the z14 at 5.2 GHz, IBM claims an average 10-13% uplift in single-thread performance.
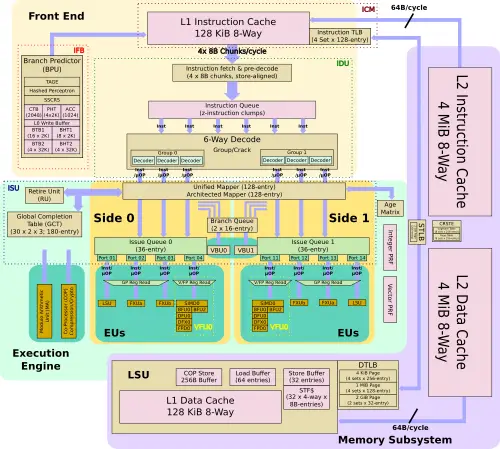
Front End
Like the z14, the z15 features 128 KiB private L1 instruction cache.
| L1I Cache Comparison | ||||||
|---|---|---|---|---|---|---|
| IBM | Intel | AMD | ||||
| uArch | z12 | z13 | z14 | z15 | Sunny Cove | Zen 2 |
| Capacity | 64 KiB | 96 KiB | 128 KiB | 128 KiB | 32 KiB | 32 KiB |
| Organization | 4-way | 6-way | 8-way | 8-way | 8-way | 8-way |
| Line Size | 256 B | 256 B | 256 B | 256 B | 64 B | 64 B |
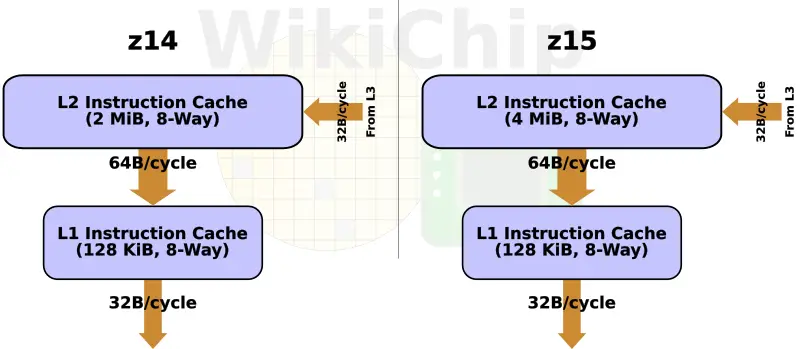
As with its predecessors, the z15 continues to use a split-cache hierarchy within the core itself. On the z15, IBM doubled the size of the level 2 instruction cache to 4 MiB, reaching parity with the data cache size. Unlike any other non-IBM processor, those caches are not implemented in SRAM but, instead, use their highly dense eDRAM cell.
| L2I Cache Comparison | ||||||
|---|---|---|---|---|---|---|
| uArch | z12 | z13 | z14 | z15 | ||
| Capacity | 1 MiB | 2 MiB | 2 MiB | 4 MiB | ||
| Organization | 8-way | 8-way | 8-way | 8-way | ||
| Line Size | 256 B | 256 B | 256 B | 256 B | ||
Improved BPU – New TAGE Predictor
Asynchronously of instruction processing, the branch predictor operates ahead of the instruction stream, locating and predicting branch instructions. On the z14, IBM used a number of different algorithms. The z14 has a first level BTB and history table (BHT) as well as a second level BTB. The z14 also has a BTB pre-buffer (BTBp) which was essentially an L1 BTB1 victim cache. Once used, it passes it on to the L1 BTB. On the z15, the BTBp has been removed. Instead, it was replaced by a simpler write buffer with the two independent read ports being replaced by single double-bandwidth port. Additionally, the L1 BTB has increased from 4 sets of 2K rows to 8 sets of 2K rows. The L2 BTB is unchanged.
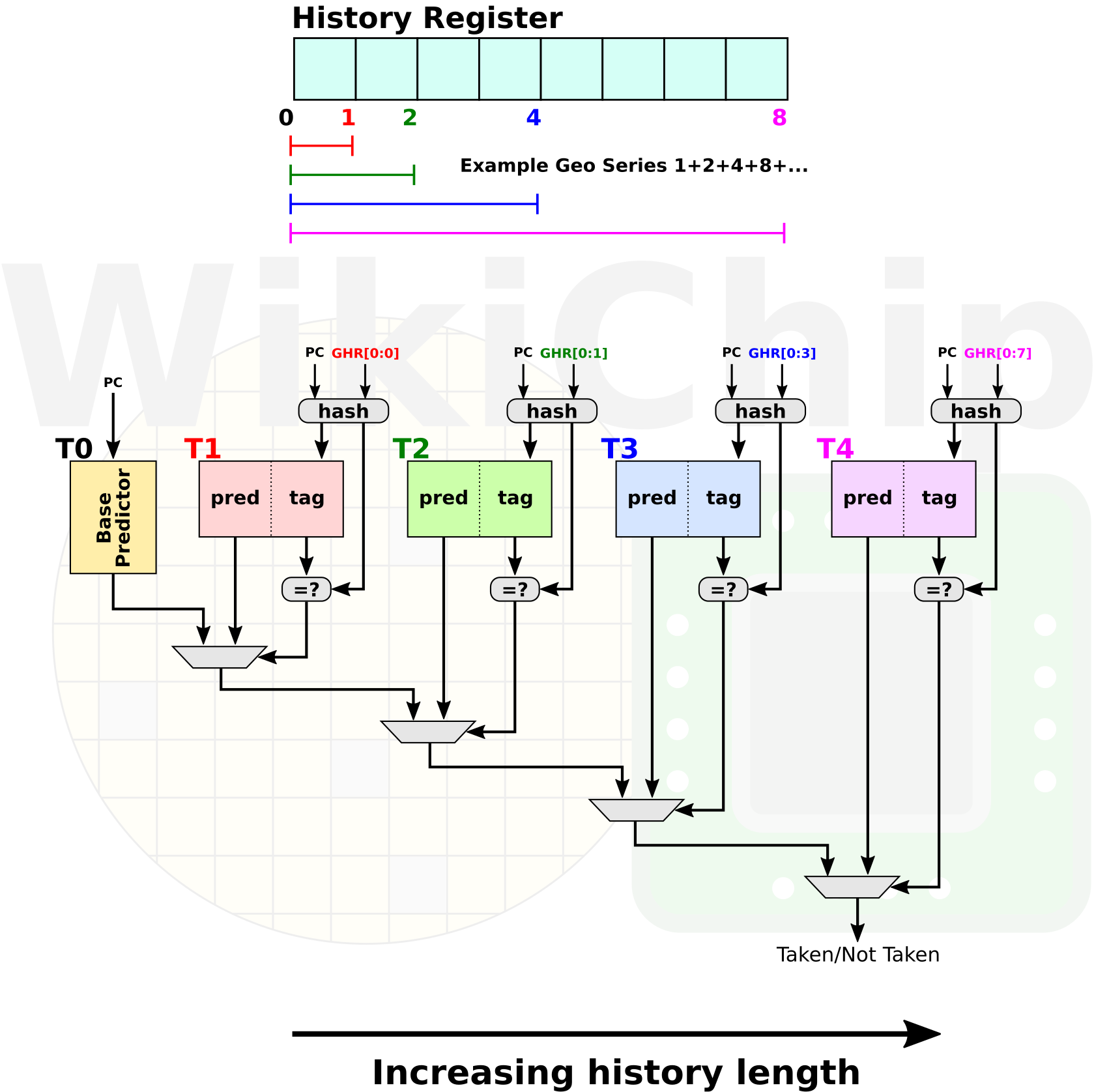
With the introduction of z14, IBM added two new predictors – a Hashed Perceptron and a simple call-return stack for target prediction. With the z15, IBM made a number of enhancements. First, the simple call-return stack can now return to branches located up to 8 bytes past the next sequential instruction. Previously, the predictor was limited to returning to the next sequential instruction. The most major addition to the z15 is the introduction of a new TAGE predictor. AMD has recently added the same predictor to their Zen 2 core. If you are interested, we have covered the behavior of the TAGE predictor in this article.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–