
IBM Introduces Next-Gen Z Mainframe: The z15; Wider Cores, More Cores, More Cache, Still 5.2 GHz
IDU
The rest of the front-end is largely the same as the z14 and is therefore beyond the scope of this article. In short, it still fetches four 8B chunks of store-aligned text (32B) and parses it into pre-decoded z-instructions for decoding consumption. Remember that z-instructions, like x86, are variable-length. They can range from 2 to 6 bytes. A 6-way decoder can decode/group/crack up to six instructions/micro-operations each cycle in two groups of three decoders.
The decoders can form groups of micro-operations. A group is a collection of up to 3 micro-ops, which can span multiple instructions. micro-ops are grouped for performance reasons, removing various hazards and simplifying the rest of the pipeline. For example, simple instructions such as reg-reg and reg-storage are typically stored together. If it’s a branch, it will typically be the last instruction in the group if predicted taken. The full list of rules is a bit more complex.
In total, up to six instructions are then sent for renaming in the out-of-order portion of the core. On the z15, this translates to up to 2 groups each cycle.
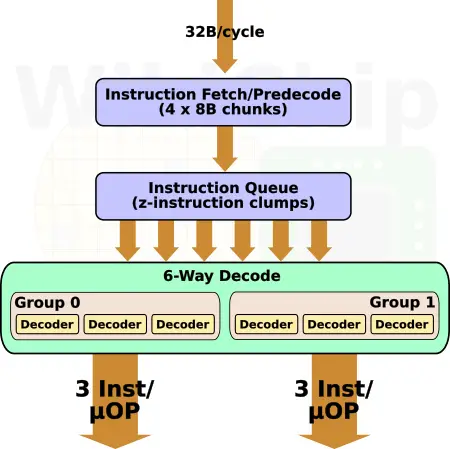
Back-end
IBM made numerous enhancements in the back end of the z15 core. The number of instructions in-flight has increased thanks to a number of main components that have been enlarged. From the front end, grouped instructions and μops are sent to the issue queues (and GCT) which operate out-of-order. Throughput the back-end, tracking of in-flight operations is done in groups. When a new group is sent to the issue queue, an entry is allocated in the global completion table (GCT). This component is similar to the RCU on AMD Zen or the ROB on Intel Sunny Cove. However, instead of tracking individual uops, the GCT tracks simple groups. There are two issue queues on the z15, one on each side. Those are deeper, with a capacity of 36 entries each (up from 30 in the z14). The capacity of the GCT has increased by 25% as well, from 144 (24 x 2 x 3) instructions to 180 (30 x 2 x 3). In addition to its capacity, the GCT can now execute and retire a total of up to 12 instructions each cycle, two more instructions than the z14.
| Reorder Buffers | ||||||
|---|---|---|---|---|---|---|
| Company | IBM | AMD | Intel | |||
| uArch | z14 | z15 | Zen 1 | Zen 2 | Skylake | Sunny Cove |
| ROB Capacity | 144 (24 x 2 x 3) |
180 (30 x 2 x 3) |
192 | 224 | 224 | 352 |
Renaming from logical registers to physical registers is done by the mapper. This is a fairly complex piece of hardware as some instructions require as much as five input source registers to get mapped. The z15 has two mappers: a unified mapper which is used for mapping instructions during processing from dispatch to completion, and an architected mapper which handles the post-completion mapping. IBM says that the mapper was redesigned in the z15. Both mappers on the z14 had 64 entries. As part of the redesign, the z15 mappers doubled in size with 128 entries. IBM says that both the integer and vector physical register files have been increased in capacity but did not disclose their new size. On the z14, the PRFs were 120 and 127 respectively.
| OoO Resources | |||||
|---|---|---|---|---|---|
| uArch | z196 | z12 | z13 | z14 | z15 |
| Mapper | 48 | 48 | 64+64 | 64+64 | 128+128 |
| GCT | 3 x 24 | 3 x 30 | 3 x 2 x 24 | 3 x 2 x 24 | 3 x 2 x 30 |
| Issue Queue | 20/side | 20/side | 30/side | 30/side | 36/side |
| Branch Queue | N/A | 12/side | 14/side | 16/side | 16/side |
| Integer PRF | 80 | 80 | 120 | 120 | >120 |
| Vector PRF | 48 | 64 | 127 | 127 | >127 |
On the z14, each cycle, up to ten instructions can be issued to the execution units. The z15 has a wider back-end that can issue up to 12 instructions each cycle. There is now a brand new Modulo Arithmetic (MA) unit to support Elliptic Curve Cryptography along with a new Message-Security-Assist Extension 9 (MSA-X9) and Elliptic Curve Signature Authentication (ECSA) instruction extension. The Vector and Floating Unit (VFU) was also improved. IBM added addition sub-units within the BFUs, doubling the throughput of single- and double-precision Binary Floating Point.
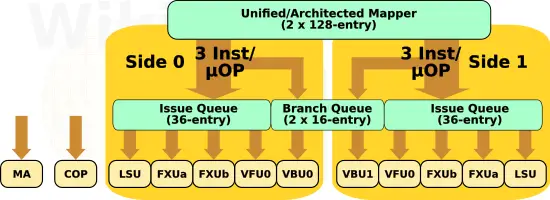
Making Some Room
Both the z14 and z15 are roughly 700 mm². They are both fabricated on the same 14-nanometer FinFET on SOI process. Yet, somehow IBM managed to improve the z15 cores, add two more cores, and double the L3 cache by adding 128 MiB of additional capacity? IBM claims that through a new eDRAM macro design they are able to deliver twice the density. Slightly over half of those transistors can be accounted for with the new cache addition. Based on the floorplan diagrams shown by IBM, it appears that through various redesigns and a new physical floorplan, they were also able to shave a few squared millimeters from each core. This bought them roughly 20 mm² or so of additional silicon on each side of the die. Additionally, if you recall earlier we pointed out that they have gone from 6 processors per drawer down to 4. While IBM is billing this as a reliability advantage due to a reduced number of components, we believe the real reason for this change is so they could remove one X-Bus receiver and driver from the die. By our estimates, this bought them another ~9 mm² of silicon on each side of the die. Additionally, IBM dropped the GX bus and instead used the silicon area for the new NXU and another PCIe root complex.
By making the physical layout of each core slightly shorter but longer, with the slightly smaller core, they were able to squeeze one additional core on each column.
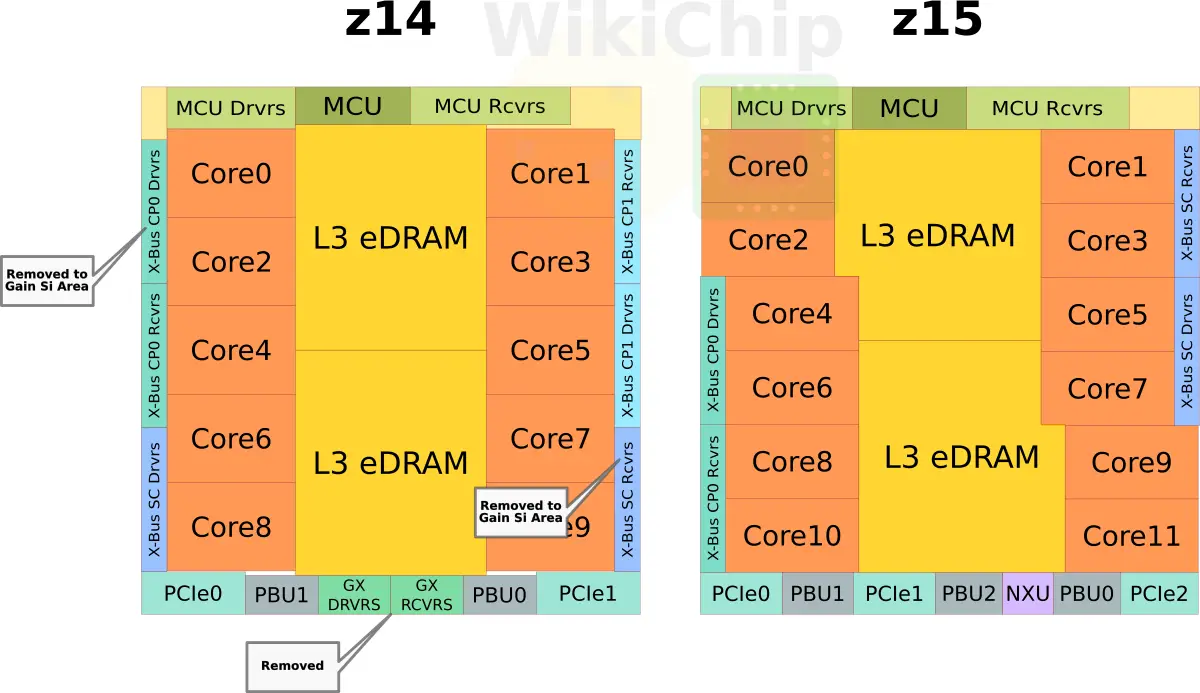
System Controller
The system controller facilitates that inter-drawer communication. Additionally, it implements the L4 cache. As with the L2, and L3, the L4 cache is also implemented using eDRAM. On the z15, IBM increased the L4 capacity to 960 MiB. This is 288 MiB more than the z14. It is non-exclusive of all the L3s. In a full z15 mainframe configuration, across all five CPC drawers, there is a total of nearly 5 GiB of L4 cache. This is on top of the total 5 GiB of L3 cache that’s spread across all 20 processors.
| L4 Cache Comparison | ||||||
|---|---|---|---|---|---|---|
| uArch | z12 | z13 | z14 | z15 | ||
| Capacity | 384 MiB | 480 MiB + 224 MiB (NIC) | 672 MiB | 960 MiB | ||
| Organization | 24-way | 30-way + 14-way | 42-way | 60-way | ||
| Line Size | 256 B | 256 B | 256 B | 256 B | ||
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–