
Centaur Unveils Its New Server-Class x86 Core: CNS; Adds AVX-512
![]()
It has been a while since we last heard from Centaur Technology. The company’s last major technology introduction was a decade ago with the Isaiah microarchitecture and the CN core when the company introduced the Via Nano. Since then, the small Austin team refocused its efforts and has been diligently working on its next project – a high-performance data center and edge x86 chip with powerful integrated AI acceleration. Today, Centaur is opening up on its latest core.
Before we dive into the core microarchitecture, it’s important to look at the full SoC Centaur developed, codename CHA. Keep in mind that this is a technology reveal. The final product branding will be determined by Via when it launches.
CHA is Centaur’s new data center and edge server SoC. But it’s not your usual edge server SoC. We think Centaur has something really special here. It’s a new ground-up design that features eight high-performance x86 cores along with a new clean-sheet design AI coprocessor. The inference market is just starting to explode and what’s better than a processor connected to a powerful AI accelerator card? One that comes with one deeply integrated, of course. What Centaur came up with is a pretty powerful accelerator. For completeness, we want to note the individual core microarchitecture is codenamed CNS while the AI coprocessor codename is NCORE.
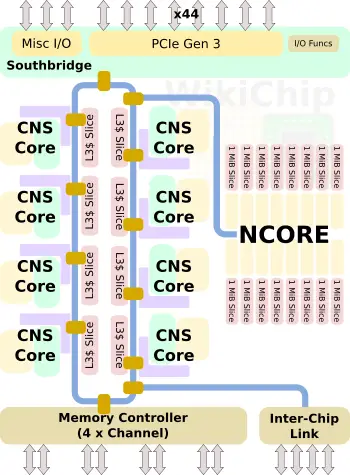
In today’s technology reveal, we’ll be talking about the new core – CNS. Since the NCORE plays a significant role in this chip, we will be discussing the full SoC and the NCORE in more detail in a number of follow-up articles.
CNS
At the heart of the new CHA SoC are eight new high-performance x86 cores, codename CNS. As usual, you can find a fully complete microarchitectural deep dive of the new core on our main CNS WikiChip article. We’ll cover the most interesting aspects here.
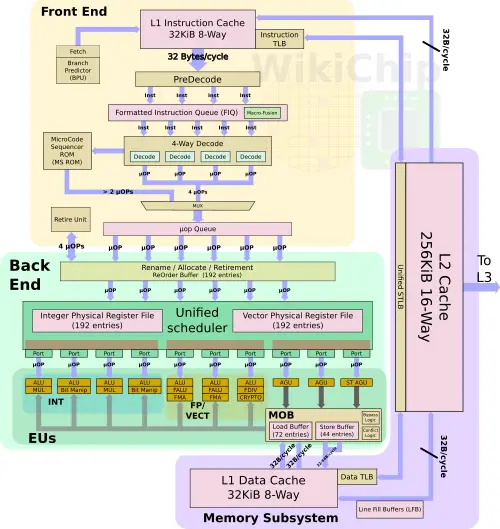
At a high level, Centaur significantly improved the front-end of the machine versus prior generations. The new core has a better branch predictor and better prefetchers. The core is capable of fetching up to 32 bytes each cycle from a 32 KiB L1I$ and decoding up to four instructions each cycle. In that respect, Centaur is quite comparable to most recent Intel cores as well as recent AMD cores, including Zen and Zen 2.
| Level 1 Instruction Caches | |||||
|---|---|---|---|---|---|
| Company | Centaur | AMD | AMD | Intel | Intel |
| uArch | CNS | Zen | Zen 2 | Coffee Lake | Sunny Cove |
| L1I Capacity | 32 KiB | 64 KiB | 32 KiB | 32 KiB | 32 KiB |
| L1I Org | 8-way, 64 sets | 4-way, 256 sets | 8-way, 64 sets | 8-way, 64 sets | 8-way, 64 sets |
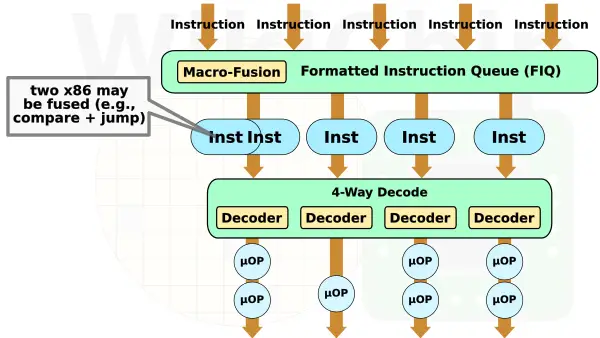
One of the more interesting features Centaur has had for a while in its cores is the ability to do macro-fusion. This was improved further with the new CNS core. Macro-fusion happens prior to the decode stage in a similar fashion to Intel’s core. CNS can detect certain pairs of adjacent instructions such as a simple arithmetic operation followed by a conditional jump and couple them together such that they get decoded at the same time into a fused operation. This enables CNS to decode up to five instructions per cycle, reducing the effective bandwidth across the entire pipeline from the fused operations.
When looking at the front-end, you’ll notice that the CNS does not integrate a micro/macro operation cache of any kind. Turns out Centaur didn’t add one with this design – a crucial component found in all Intel big cores for the past decade and something AMD has added with its recent Zen-based microarchitecture series. The cache provides higher throughput and lower-power route for already predicted and decoded instruction streams. Centaur believes it can achieve its target performance without it in this generation. Going forward, Centaur told WikiChip it has a number of ideas for the next few generations and the cache is certainly one of the number of components they plan on introducing in their future roadmap, albeit the exact kind of implementation might differ from existing designs. Additionally, it’s worth pointing out that a number of alternative solutions showed up in the production chips in recent years. Most recently, Intel’s own small-core team introduced an entirely radical approach to this problem with multiple out-of-order decode clusters.
Back-End
At the out-of-order side of the machine, Centaur made a number of major improvements. Firstly, matching the decode width, the CNS is able to rename (and later retire) four instructions per cycle. This is similar to all recent Intel cores. Secondly, the pipeline itself much wider now. Centaur’s last chip used relatively old process node – 65 nm and later 45 nm. The move to a more leading-edge node (TSMC 16-nanometer FinFET, in this case) provided them with a significantly higher transistor budget. Centaur takes advantage of that to build a wider out-of-order core. To that end, Centaur’s CNS core supports 192 OoO instructions in-flight. This is identical to both Intel Haswell and AMD Zen.
| Out of Order Window | |||||
|---|---|---|---|---|---|
| Company | Centaur | AMD | Intel | AMD | Intel |
| uArch | CNS | Zen | Haswell | Zen 2 | Sunny Cove |
| Renaming | 4/cycle | 6/cycle | 4/cycle | 6/cycle | 5/cycle |
| Max In-flight | 192 | 192 | 192 | 224 | 352 |
It’s worth adding that there are some caveats to the renaming limit. For example, AMD cache throughput of six comes from a smaller number of instructions – some of which must have produced multiple operations.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–