
Goldmont Plus detailed, large improvements, setting the stage for a 32-core model
When Intel launched Gemini Lake just two weeks ago, they disclosed very little about the underlying Goldmont Plus microarchitecture. There was also very few leaks apart from the the rumored 4-way decode we tweeted based on a kernel patch about half a year ago which turned out to be partially wrong. This afternoon Intel has finally updated their Optimization Manual to include Goldmont Plus.
As usual, the complete details, block diagrams, and in-depth overview of Goldmont Plus will be added to our Goldmont Plus article.
Improvements Everywhere
If you thought Goldmont Plus is meant to be a simple refresh or introduce just a handful of enhancements over Goldmont because of the “Plus”, you’re in for a real treat. It turns out Goldmont Plus is just as large of a generational improvement as Goldmont itself was when it widened the pipeline from 2-way to 3.
We didn’t quite get it right when it came to the four-way decode, but as it turned out, we were pretty close. The front end did receive some light treatment including various enhancements to the branch prediction unit but it is the back end that has been massively enhanced. While Goldmont Plus did not touch the fetch and decode which are still 3-way, the back-end has been widened to support 4-way allocation and 4-way retirement. In other words, Goldmont Plus has a new peak retirement rate of 4 per cycle.
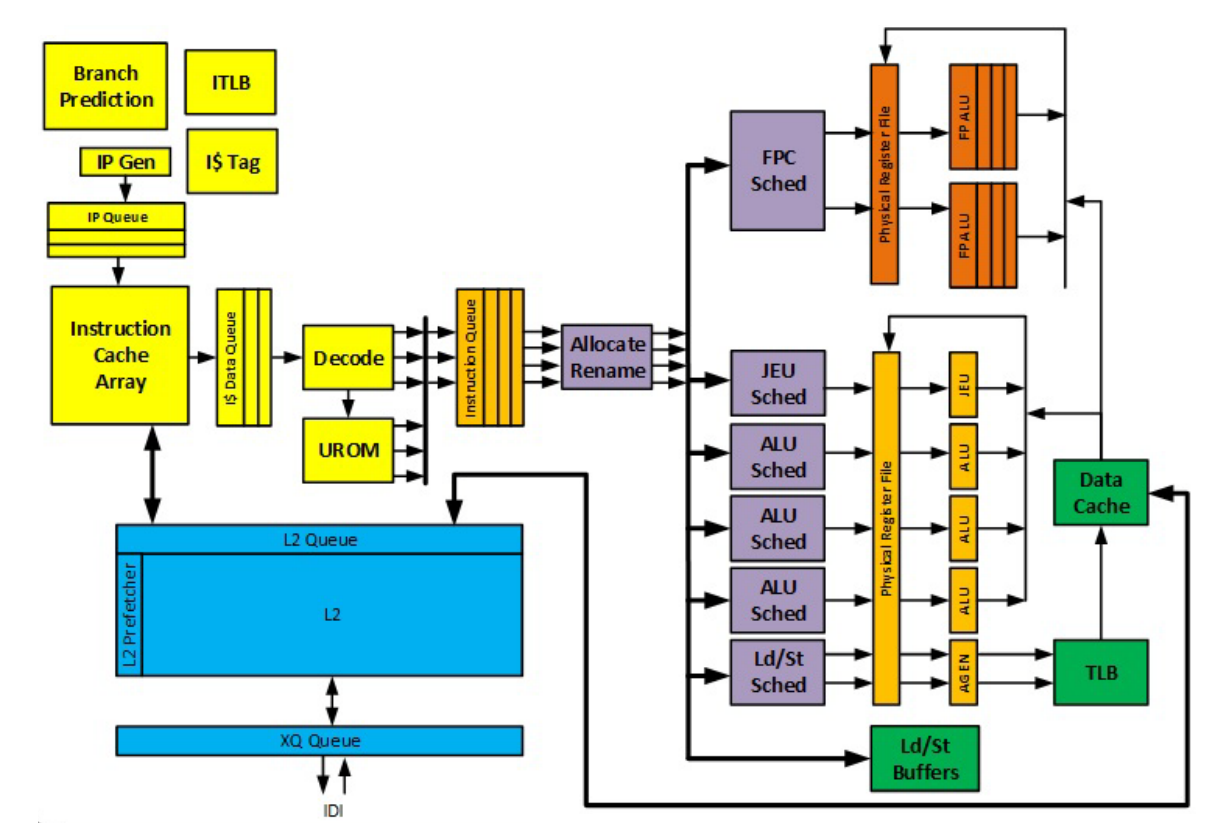
Intel also noted that the reservation station and reorder buffer have been enlarged to support a larger out-of-order window. Similarly, the load and store buffers have also been expanded. Certain store-to-load forwarding operations for store data from register have been optimized as a general improvement. They did not specify the exact amount of entries those buffers grew by so we’ll be figuring this out ourselves once those parts make it to the shelf.
The caches received a similar treatment. The L2 has doubled and the L2 predecode cache which was added in Goldmont has been quadrupled from 16 KiB to 64 KiB. Additionally, there is a new shared instruction and data second-level TLB.
The new microarchitecture has had many improvements in the execution units as well. The integer execution cluster (IEC) has been widened to 4 ports with the 4th port having a new dedicated jump execution unit (JEU) which supports faster branch redirections. AES instructions have also been improved in throughput and latency.
Perhaps the most interesting change is in the floating point divider. The floating point divider has also been upgraded to a fast radix-1024 based design (i.e., 10 bits), improving scalar/packed single, double, and extended precision FP divisions. With this change, bandwidth has been increased significantly and latency for those operations were cut in more than half. We’ll have to wait for actual benchmarks to know how much of an impact this has in practice but we don’t think we’ll be disappointed.
| Goldmont vs Goldmont Plus FP Division | ||||
|---|---|---|---|---|
| Goldmont | Goldmont Plus | |||
| Latency | Throughput | Latency | Throughput | |
| x87 fdiv (extended-precision) | 39 | 39 | 15 | 11 |
| x87 fdiv (double-precision) | 34 | 34 | 14 | 10 |
| x87 fdiv (single-precision) | 19 | 19 | 11 | 7 |
| scalar single-precision (divss) | 19 | 18 | 11 | 7 |
| scalar double-precision (divsd) | 34 | 33 | 14 | 10 |
| packed single-precision (divps) | 36 | 35 | 16 | 12 |
| packed double-precision (divpd) | 66 | 65 | 22 | 18 |
32-core on the horizon?
A more subtle change that was done in Goldmont Plus is the move from duplexes to quadplexes. Prior to Goldmont Plus, Intel packed two cores along with their shared L2 cache into a core level multiprocessing (CMP) module. A single core can be disabled to create a single-core processor. Likewise a module can replicated to create a quad-core configuration. Multiple CMP modules can then be hooked together using an intra-die interconnect (IDI) fabric connected to a coherent crossbar Tracker Unit (T-Unit) at the system agent.
In their microserver line such as the Silvermont-based Avoton SKUs, Intel had up to 8 cores in 4 duplexes hooked together.

In the more recent Goldmont-based Denverton SKUs, Intel doubled that up to 16 cores in 8 duplexes.

With Goldmont Plus, Intel has moved to a quadplex CMP module with 4 MiB of L2 cache. For desktop and embedded processors (e.g., Pentium Silver) this means a single CMP module is used with either 4 active cores or just 2. This is why all the recently launched Gemini Lake parts have 4 MiB of level 2 cache.
With Denverton having 8 CMP modules, we suspect the new quadplex CMP modules will play a crucial role in Intel’s next generation Goldmont Plus server parts. That is, if Intel continues with 8 CMP modules, we might see a 32-core when Intel introduces their Atom C4000-series sometimes next year.

We will have to wait and see whether this pans out. Nonetheless the new Gemini Lake Celeron and Pentium models should have a solid performance improvement over their predecessors.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–