
Arm Launches the Cortex-M55 and Its MicroNPU Companion, the Ethos-U55
Recently we discussed the Arm Ethos family. This is Arm’s first push into the dedicated neural processor IP market. The first series of IPs in the Ethos family is the commercialization of the company’s the ML Processor architecture. They covered the range of 1 TOPS to around 5 TOPS from IoT devices all the way to high-end smartphones. Today, Arm is extending its AI-related offering with the launch of two new IPs – the Cortex-M55 and the Ethos-U55.
Cortex-M55
The first part of today’s announcement is the new Cortex-M55 CPU. The M55 brings a number of new features that Arm announced over the past year. The first new feature is support for custom instructions. Arm first announced custom instructions at 2019 Techcon and pushed it out with the Cortex-M33. This feature follows similar abilities provided by RISC-V based IP cores by companies such as SiFive and Andes. The intent is to advantageously fold tight sequences of instructions into a single instruction in heavily-executed kernels to save on power and possibly throughput. What this feature lets you do is inject a limited amount of logic to the core decode stage in order to parse a limited set of custom instructions and then add custom execution logic to perform the desired operation. Now, Arm already had the ability to do something similar in the past. Traditionally, you could achieve this using memory-mapped devices. More recently, such as in the Cortex-M33, the coprocessor interface can be used to integrate operations more tightly with the CPU. This new feature offers significantly tighter integration. In contrast to the coprocessor interface which runs in parallel to the CPU, this feature offers custom instructions that are interleaved with Arm standard instructions in the same datapath and exposes the internals of the CPU such as the register file to the extension logic.
Beyond custom instructions, Arm is billing the Cortex-M55 as ‘the most AI-capable Cortex-M processor’ and that’s because this is the first processor to implement Helium. Helium, also called M-Profile Vector Extension (MVE), is an extension to the Armv8.1-M architecture that introduces new SIMD 128-bit vector operations designed to enhance DSP and ML applications and performance. It relies more on existing registers instead of vector registers like NEON and introduces new support for things such as lane prediction, loop prediction, and complex operations such as scatter-gather. More importantly, it does this by executing smaller chunks of data (32-bit) called beats in order to keep the silicon area of the IP to a minimum. For machine learning, Helium offers instructions such as the VMLAV horizontal vector multiply-accumulate instruction. Arm is quoting up to 15x uplift in ML performance and up to 5x uplift in DSP performance versus the prior Cortex-M IPs without the vector extension.

Ethos-U55
Along with the Cortex-M55, Arm is also launching the Ethos-U55. This is an extension to the Ethos family we recently discussed. The Ethos-U55 is a little different from the Ethos-N series in that it specifically targets the Cortex-M CPUs and for this reason, there are a couple of pretty big differences. First, unlike the Ethos-N which are independent IP blocks that can be dropped onto the SoC CCN-500 network, the Ethos-U is designed to tightly work with a companion Cortex-M CPU and leverage its processing capabilities. The Cortex-M55 is particularly well-suited to work with the U55 due to the Helium extension, but it can work with older Cortex-M processors such as the M7, M4, and the M33.

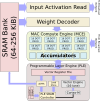
If you look at the MLP design, you’ll see it’s built using multiple instances of compute engines, each with a few major components, the SRAM, MAC Compute Engine (MCE), and the Programmable Layer Engine (PLE). The Ethos-U55 has a much simpler design due to the power and area constraints. Arm is calling it a microNPU. That’s a pretty decent description. Conceptually, you can actually think of it as an MLP with just a single compute engine. But the simplification goes further. The Ethos-U55 gets rid of the PLE. The reason for this simple, the PLE in the Ethos-N series integrates a Cortex-M CPU with a 16-lane Vector Engine. That’s quite costly on area and power but acceptable for high-performance SoCs. By combining the Ethos-U55 with a CPU like the Cortex-M55 you can get rid of the PLE and do the processing on the companion Cortex-M processor instead. It’s obviously not an exact substitute, but it’s an acceptable compromise given the strict power and area constraints.
 Machine Learning Processor (MLP) – Microarchitectures – ARM
Machine Learning Processor (MLP) – Microarchitectures – ARMAs with the PLE, a relatively expensive dedicated SRAM bank was also removed. Instead, it’s got a tiny bit of SRAM to do just enough processing internally. The Ethos-U55 assumes the external system has some sort of cache. This can be shared with the Cortex-M processor or something more global. It can still do everything else the MLP was designed to do. For example, it still got the DMA to be able to go out and fetch the NN layers as needed. Additionally, the NPU still works off compressed weights and activations from memory which will get decoded on the fly just prior to processing.
To better tune the NPU to the application, the MAC Compute Engine can be configured with 32, 64, 128, or 256 MACs. With 256 MACs, this would actually make it comparable to a 2-CE MLP since a single compute engine only has 128 MACs. The Cortex-M goes into a whole array of chips and a wide range of process technologies. Arm says that on a mature node such as the 55 nm or 40 nm, they expect to see the Ethos-U55 clocked at speeds ranging from 100 MHz to 400MHz or even higher. This gives you a peak compute performance of 6.4-25.6 GOPS with the smallest configuration of 32 MACs and up to 51.2-205 GOPS with the largest configuration of 256 MACs. On a leading-edge node such as the 7 nm or 5 nm nodes, the U55 can easily reach 1 GHz or higher. Here the peak compute performance is a respectable 0.25 TOPS and 0.5 TOPS for the 128-MAC and 256-MAC configuration.
If we were to put this in the context of the rest of the Ethos NPU family, the largest Ethos-U55 configuration on a leading-edge node would be at roughly half the raw ML performance of the Ethos-N37. In terms of PPA, the Ethos-U55 is less than half the silicon area at the same OPs/sec (at iso-process). The actual performance will vary greatly depending on the full SoCs. Beyond just the frequency, on a leading-edge node, one would expect more complex SoC subsystems that can benefit the U55 which won’t be found on older nodes. More caches and possibly more dedicated caches (associated with the Cortex-M itself) are expected on those chips which will significantly improve the performance.
| Ethos NPUs Comparison | |||
|---|---|---|---|
| SKU | U55 | N37 | |
| SKU | 55/40nm | 7/5nm | 16-5nm |
| Quads | N/A | N/A | 1 |
| CEs | N/A | N/A | 4 |
| Max Frequency | 100-400 MHz* | 1+ GHz | 1 GHz |
| SRAM Banks | Shared | Shared | 128 KiB |
| Total SRAM | N/A | N/A | 512 KiB |
| OPS | 64-512 OPs/clk | 64-512 OPs/clk | 1024 OPs/clk |
| Performance (Int8) |
6.4-25.6 GOPS (32 MACs) 51.2-205 GOPS (256 MACs) |
64 GOPS (32 MACs) 512 GOPS (256 MACs) |
1.024 TOPS |
* depends on many things such as process, Std cells, SRAM, memory subsystems, and over SoC design.
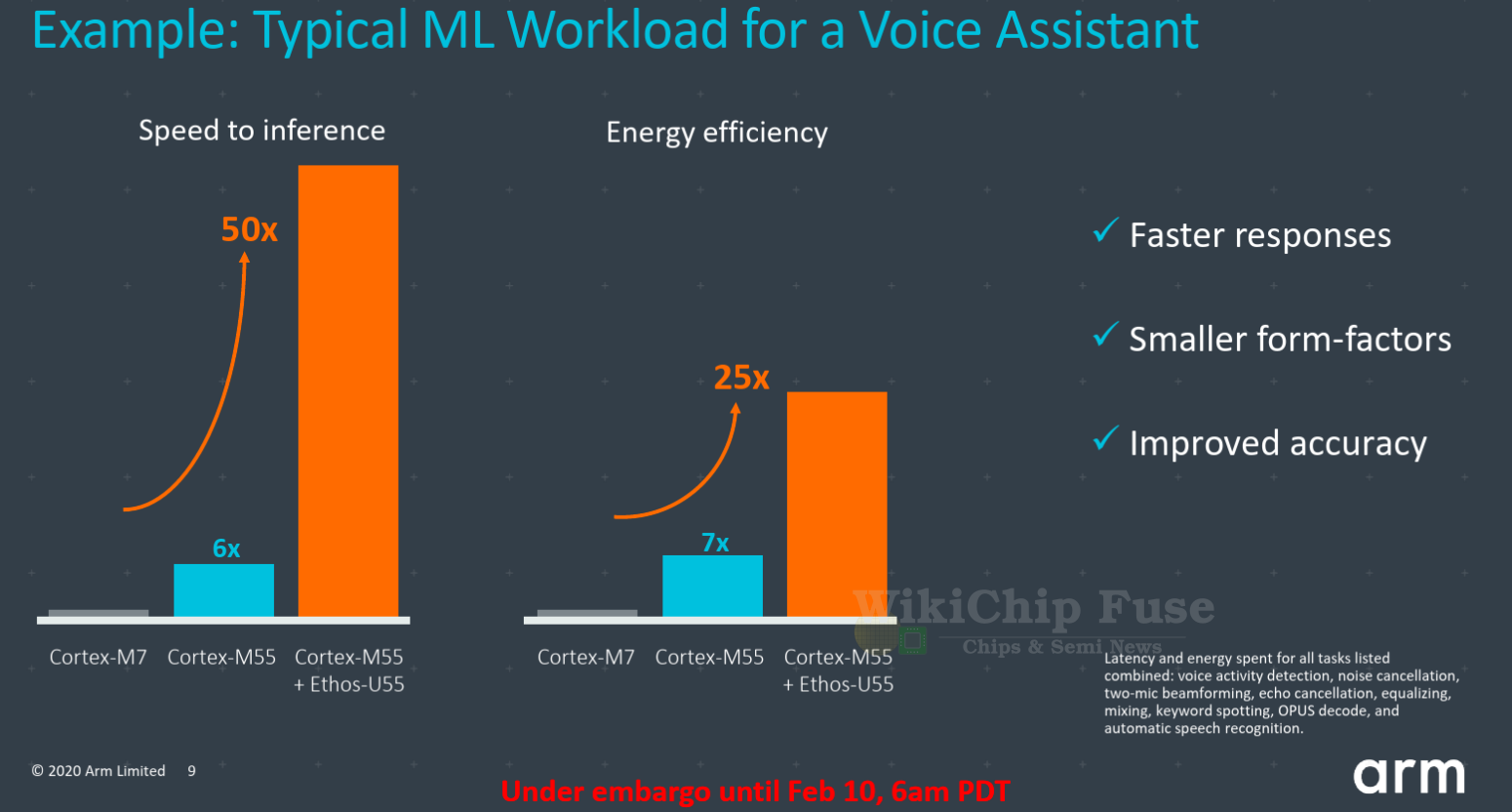
Arm claims that for a typical voice assistant type of workload, the Cortex-M55 will deliver up to as much as 6x in inference performance as much as 7x improvement in power efficiency due to the Helium extension. When combined with the Ethos-U55, Arm claims this improvement is increased up to 50x and 25x respectively. Those comparisons are done against the Cortex-M7. It’s worth pointing out that to get this kind of performance uplift, the code has to be recompiled specifically to take advantage of not only the new M-Profile Vector Extension, but also the Ethos MAC engine processing capabilities.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–