
Arm Unveils Next-Gen Armv9 Big Core: Cortex-A710

With Arm announcing the Armv9 architecture earlier this year and the new ARMv9 Neoverse cores-based server processors already being announced, the only thing left is Armv9 client CPUs. And, as has become tradition over the past couple of years around May time, today Arm is introducing their latest next-generation cortex-A78 successor – the Cortex-A710.
This article is part of a series of articles covering Arm’s Tech Day 2021.
- Arm Unveils Next-Gen Armv9 Big Core: Cortex-A710
- Arm Unveils Next-Gen Armv9 Little Core: Cortex-A510
- Arm Launches Its New Flagship Performance Armv9 Core: Cortex-X2
- Arm Launches The DSU-110 For New Armv9 CPU Clusters
- Arm Launches New Coherent And SoC Interconnects: CI-700 & NI-700
The Cortex-A710 is the first ARMv9 implementation in a big core. But not only that, but the new Cortex-A710 is also the first big core to feature the Scalable Vector Extension 2 (SVE2). A big focus of the A710 has been around energy efficiency with optimizations across the board doubling down on features that help reduce the power without harming performance. To that end, Compared to the Cortex-A78, the Cortex-A710 is said to deliver a 30% improvement in energy efficiency for the same performance levels. Likewise, at similar the same power as the A78, we can expect to see a 10% performance uplift in IPC. Both numbers are given at ISO-process. Additionally, thanks to the new SVE support and new ISA extensions, the A710 has twice the ML theoretical peak performance.

Front End

At a high level, most of the major structures in the front-end are the same as the A78. This includes the same 1536-entry MOP cache, the configurable 32/64 KiB private level 1 instruction cache, and the configurable 256/512 KiB private L2 cache. In a very similar manner to how Arm has been tackling the performance improvements of the Cortex-X2, with the Cortex-A710, Arm spent considerable effort on improving the instruction stream prediction mechanisms. Starting with the branch prediction, Arm made generational improvements to its accuracy. Additionally, key branch prediction structures were doubled in capacity. More specifically, the branch target buffer and the global history buffer both doubled in capacity. Additionally, the L1 instruction translation lookaside buffer was also increased by 50% compared to the Cortex-A78. All in all the A710 brings a modest reduction in cache misses and table walks, thereby improving performance.
Narrower Dispatch
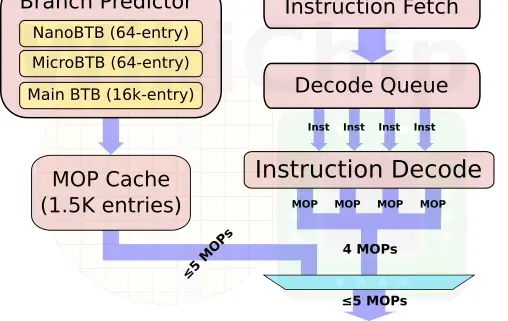
Some of the more interesting changes were made to the middle of the core, especially around the decode unit. With the introduction of the Cortex-A77 and with the Cortex-A78, the decode and rename units both supported delivering up to 6 MOPs from the MOP cache (or up to 4 instructions from the legacy path) each cycle. On the new Cortex-A710, Arm reduced that down to five. This includes the MOP bandwidth from the MOP cache as well as the rename. The change is a pretty major reversal in the key parameter of the pipeline – its width. There were a couple of tradeoffs that played a role in making this change. On the one hand, a narrower pipeline significantly reduces the area and power. On the other hand, this change will inevitably incur a performance penalty. The key for this change to make sense is to make enough improvements to the instruction stream delivery to be able to afford to dial down this part of the machine and still end up with a win.
In fact, that’s exactly what the Arm team did. Various optimizations took place in the MOP cache such as reducing pessimism and improving the efficiency of the packing logic which positively improved the flow of MOPs. Additionally, with a slightly simpler rename, and thanks to working out some bottleneck kinks around the rename rebuild after a branch misprediction, they were able to remove a single pipeline stage at dispatch. Now, the pipeline is an overall 10-cycle pipeline from branch prediction to branch execute.
All in all, the reduction in width produces a significant reduction in area and power albeit at a performance cost, but through improved fetch, MOP cache delivery, and branch prediction, the net result is coming out on top with an improvement to performance at lower power.

The Cortex-A710 introduced a lot of other subtle improvements to mechanisms that help improve the instruction stream without really touching any of the major structures. One such example is the targeted improvements to the hardware prefetchers. Generational improvements were made in the data prefetchers for greater coverage and higher accuracy. Additionally, further stride access and tablewalk prefetching coverage were added. The Temporal prefetchers were also improved in both coverage and accuracy.
When compared to the Cortex-A78, the Cortex-A710 is more aggressive and accurate on the prefetcher. This allows it to reduce the number of requests made to the DSU. This, in turn, allows the DSU to make fewer requests up the memory path and to the DRAM. Arm said they see a sizable reduction in the number of DSU accesses and DRAM refills when compared to the prior generation. Not only does this yield better utilization of the shared resources on the system, but it directly results in lower power consumption under identical workloads.
On the memory side of the execution units, The load-store and addresses generation units bandwidth all remain the same as the prior generation.

Performance
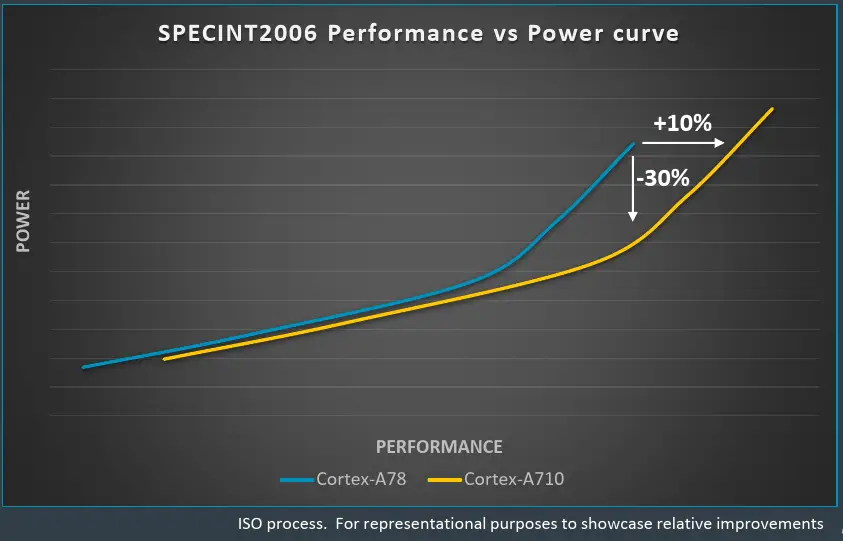
Below is a graph of the DVFS of the Cortex-A710 and the Cortex-A78. The measured benchmark is a single-thread SPECint 2006 performance and power at ISO-process. Compared to the Cortex-A78, the new Cortex-A710 can reach the same level of performance at significantly lower power – up to 30% reduction at peak points. Alternatively, at the same power envelop, the A710 can now reach as much as 10% higher performance. And in fact, the A710 can actually reach even higher performance than advertised if IP customers are willing to loosen up their power restrictions per core.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–