
Arm Launches Its New Flagship Performance Armv9 Core: Cortex-X2

Last year Arm forked the big core in the client segment into two series – the preexisting Cortex-A7x series and a new Cortex-X series. The A7x continued with the traditional sustained efficient performance as the prior generations whereas the Cortex-X series cores took a slightly different route, focusing on peak bursty high performance. To that end, today Arm is introducing the second-generation Cortex-X flagship performance CPU – the Cortex-X2.

This article is part of a series of articles covering Arm’s Tech Day 2021.
- Arm Unveils Next-Gen Armv9 Big Core: Cortex-A710
- Arm Unveils Next-Gen Armv9 Little Core: Cortex-A510
- Arm Launches Its New Flagship Performance Armv9 Core: Cortex-X2
- Arm Launches The DSU-110 For New Armv9 CPU Clusters
- Arm Launches New Coherent And SoC Interconnects: CI-700 & NI-700
Right off the bat, there are a couple of things that should be highlighted about the new Cortex-X2. For one, this is the first Armv9 based implementation in the Cortex-X series. It also comes with the Scalable Vector Extension 2 (SVE2) support. Finally, this core was specifically optimized for AArch64 only. This is because of Arm’s ongoing effort to transition to 64-bit Arm only in the mobile space.
Front-End
All the microarchitectural enhancements in the new Cortex-X2 were made while maintaining the maximum frequency capability from the prior generation. As with the Cortex-A710, a large portion of the effort in this generation of CPU improvements took the form of improvements to the instruction stream prediction mechanism.
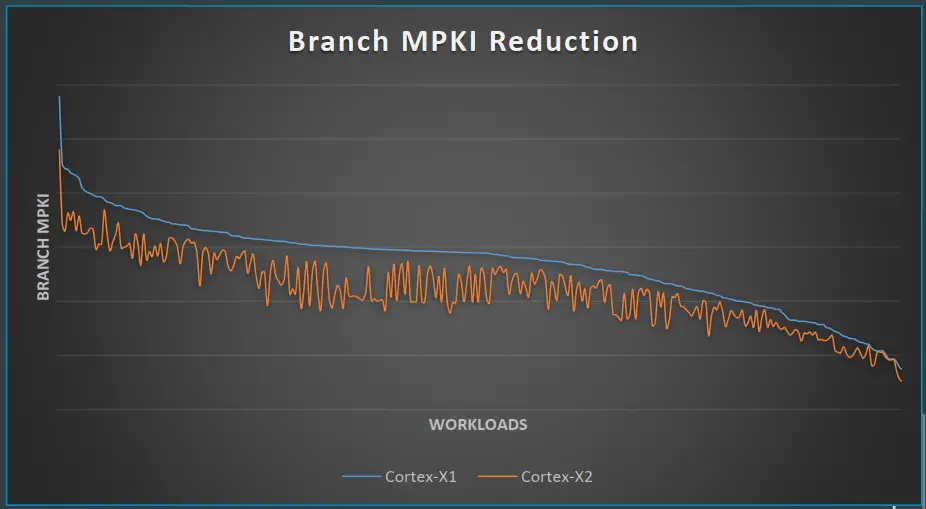
Starting off with the branch prediction unit on the X2, it is decoupled from fetch similarly to the last few generations of the Cortex-A. The decoupling allows for faster run-ahead which allows its branch prediction to detect instruction cache misses much earlier. This in turn allows the instructions to be prefetched from the private L2 cache much earlier. Ideally, the result is hiding bubbles from the downstream cores with the new instructions stream ready to be fetched.
There were also other improvements such as the usual generational improvements to the conditional branch prediction accuracy. The X2 also doubled the branch predictor state size from the Cortex-X1 for conditional branches. Arm also added a new alternate path branch predictor that targets hard-to-predict branches. For improving performance on large instruction footprint workloads, the effective size of the branch target buffer was increased.
All of this translates to a sizable improvement to branch misprediction on real workloads. This usually also correlates with better power efficiency.
OoO Back-End
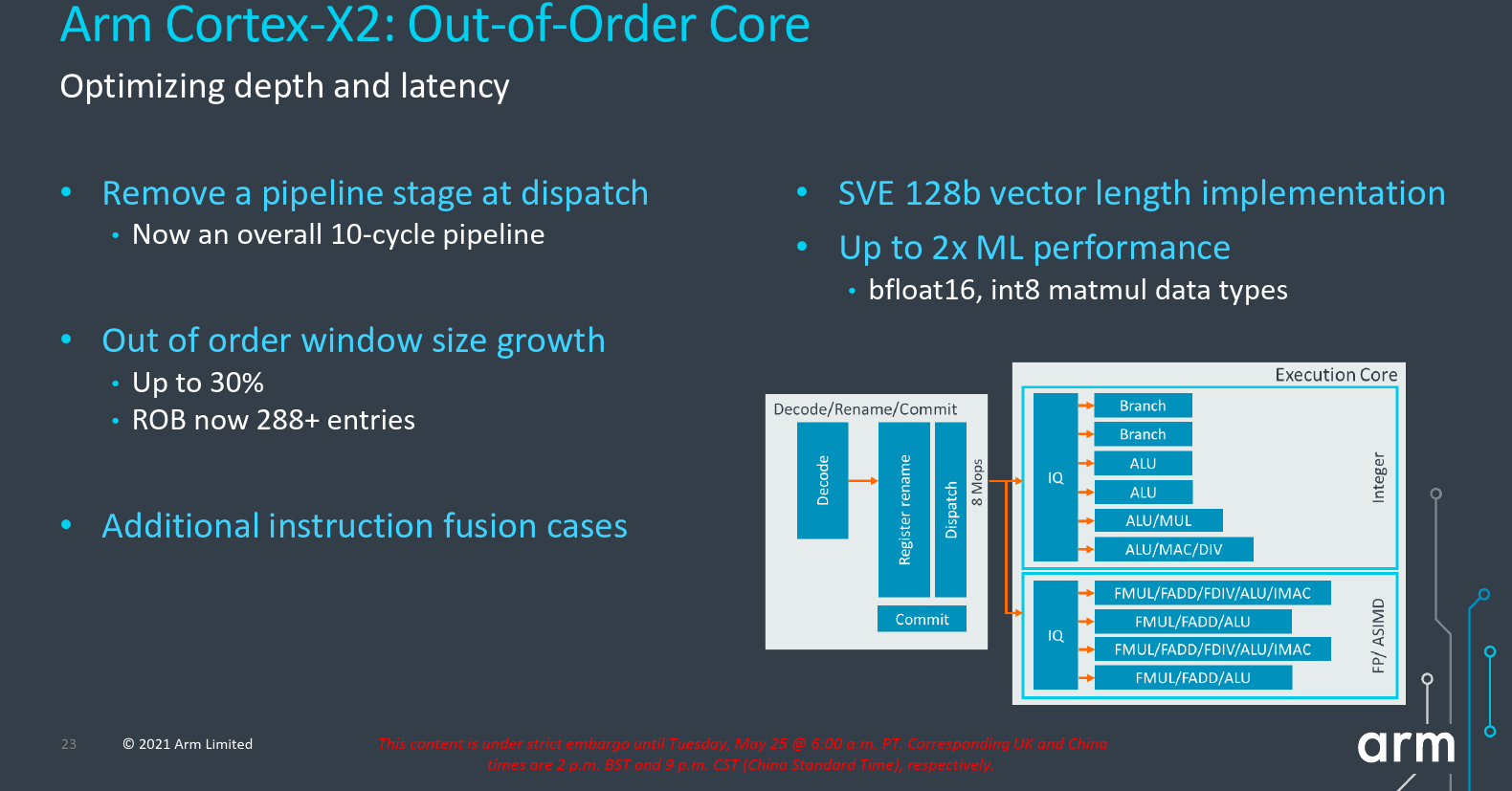
On the out-of-order back end of the core, the main focus in the X2 was the optimization of latency and depth of the pipeline. By working out and redesigning the rename rebuild after a branch mispredictions and optimizing some bottlenecks, the Arm Cortex-X2, like the new Cortex-A710 core, eliminated a single stage from dispatch. Overall, the new Cortex-X2 is a 10-cycle pipeline measuring from branch prediction to branch execute.
Like the X1, Arm continued to increase the out-of-order window. To that end, the new Cortex-X2 has a significantly enlarged reorder buffer with the capacity of 288-entries – up from 224 in the prior generation. Arm also added a few new instruction fusion cases which can further increase the effective capacity.
Execution
The new Cortex-X2 supports the Scalable Vector Extension 2 (SVE2). To that end, it implements a 128b vector unit. The X2 also implements the bfloat16 data type as well as the int8 matrix multiply extension which allows for up to 200% the theoretical ML performance over the prior generation.
Memory subsystem
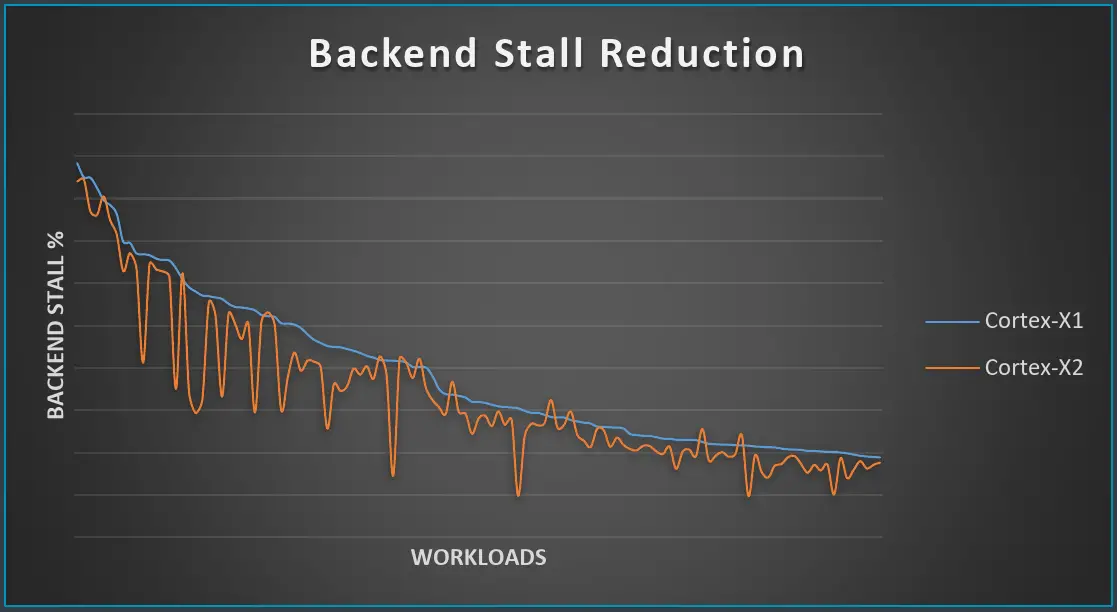
More memory parallelism was extracted with the new Cortex-X2. Pretty much across the board, Arm increased the load-store window and structure sizes by around 33%. For the improvement of large footprint workloads Arm increased the data TLB by roughly 20% to 48 entries.
Various blocks on the prefetching side were also enhanced. Further stride access and tablewalk prefetching coverage were added. The Temporal prefetchers were also improved in both coverage and accuracy. These changes produced a modest improvement to the backend stalls across various real-world workloads.
In terms of bandwidth, the Cortex-X2 is the same as the Cortex-X1 – supporting up to 3 address generations per cycle or up to three loads and two stores per cycle.
Performance
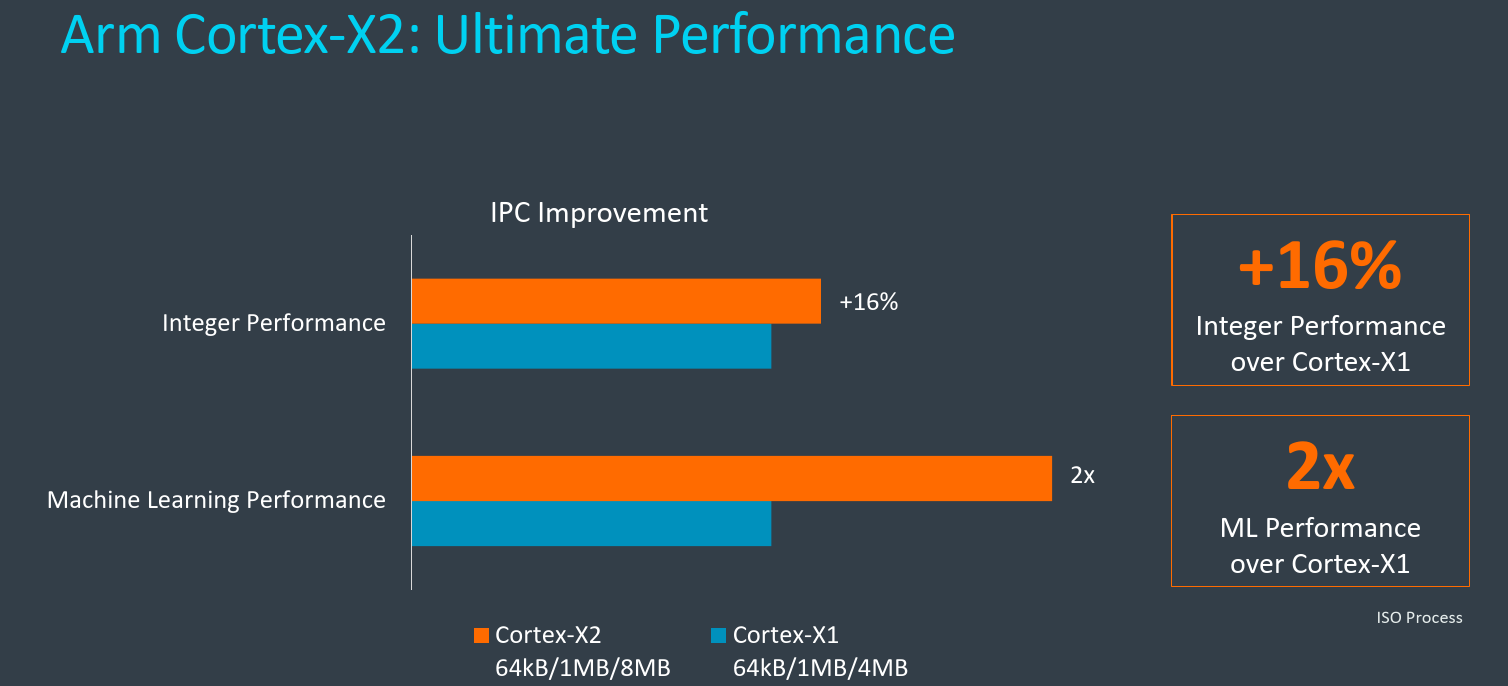
Moving from the X1 to X2, Arm says they are seeing up to 16% IPC improvement on integer performance (on the SPECint 2006 benchmark). This is at iso-process with the same frequency and same local cache (L1 and L2) configuration. Arm says that some partners are looking to clock the cores higher and add improvements to the path to main memory. In those cases higher performance is possible.
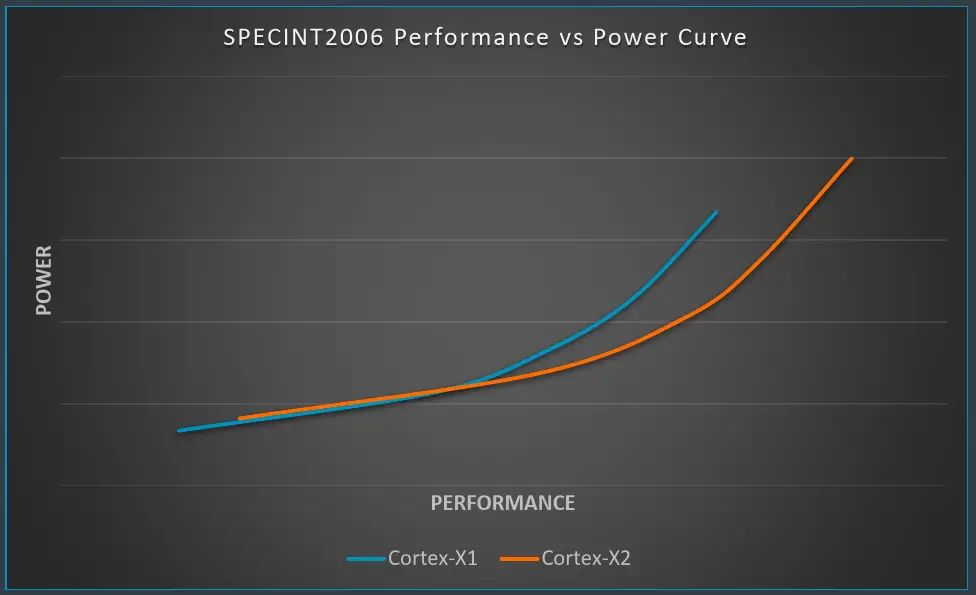
On Arm’s own reference implementation which they use as a proof point and as a way of verifying PPA demonstrated the power curve shown below on the SPECint 2006 benchmark.
Compared to the X1, the new Cortex-X2 does consume higher peak power, but in doing so they exceeded the X1 performance by a sizable amount. Alternatively, when you go slightly lower on the power curve, the Cortex-X2 also achieves the peak performance points of the X1 at lower power levels.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–