
DARPA ERI: HIVE and Intel PUMA Graph Processor
Modern microprocessors are usually able to hide much of the gap between compute and memory through a hierarchy of caches. They can do that because many workloads exhibit relatively predictable general memory patterns that can be exploited via spatial locality and temporal locality. Some workloads are also embarrassingly parallel. AI workloads, for example, tend to exhibit such behavior. Provided you can keep the machine fed, more compute equals more performance. AI workloads also tend to have very predictable memory patterns along with high data reuse abilities which helps all of the above.
Unfortunately, not all algorithms have those desirable characteristics. One such example is a graph. Companies use graphs for big data extensively. Those data structures tend to have upwards of trillions of edges and employ special graph algorithms to operate on the data. Graph algorithms have very random-like memory access patterns resulting in workloads that are highly bound by the memory latencies, forcing compute elements to get stuck stalling much of the time. It’s essentially a really big pointer-chasing problem, exhibiting behavior that is contradictory to most workloads that run on GPUs and CPUs.
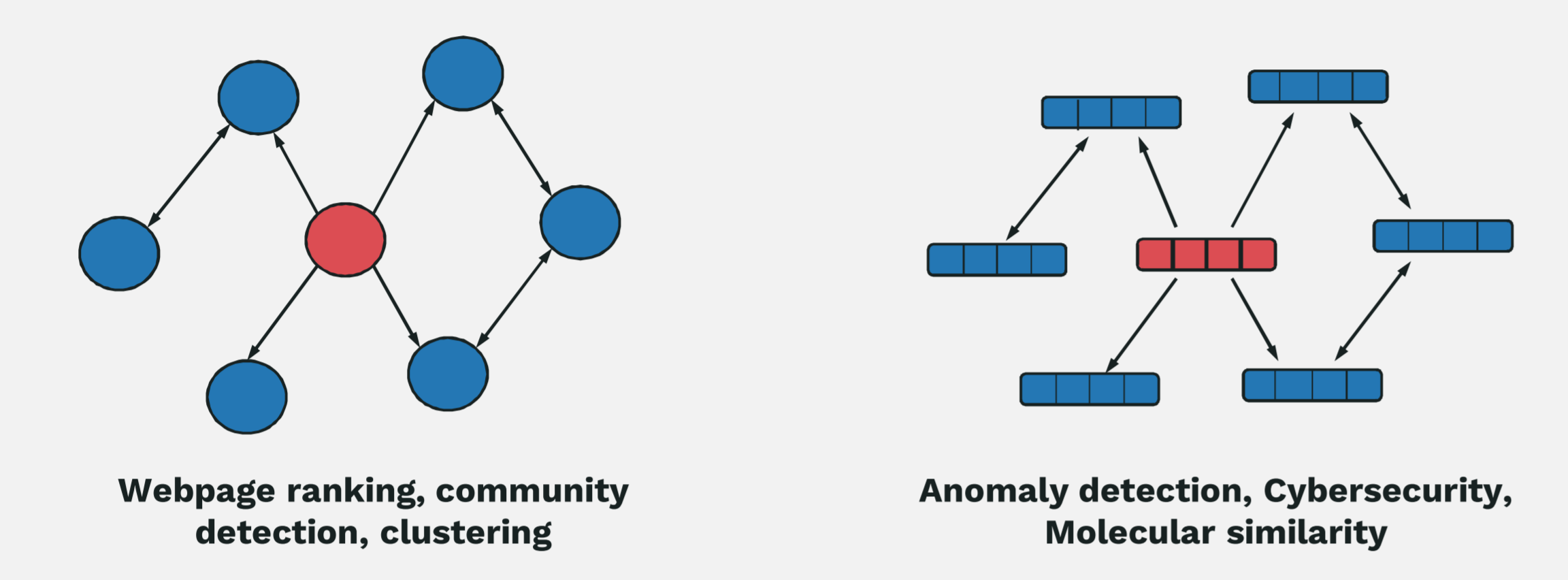
To make matters worse, graph algorithms tend to have very poor sub-linear scaling properties. You simply can’t throw more processors at the problem. With the sparse and irregular nature of the data, the next data access will often be on an entirely different node and transferring the data around ends up bottlenecking the entire system.
DARPA HIVE
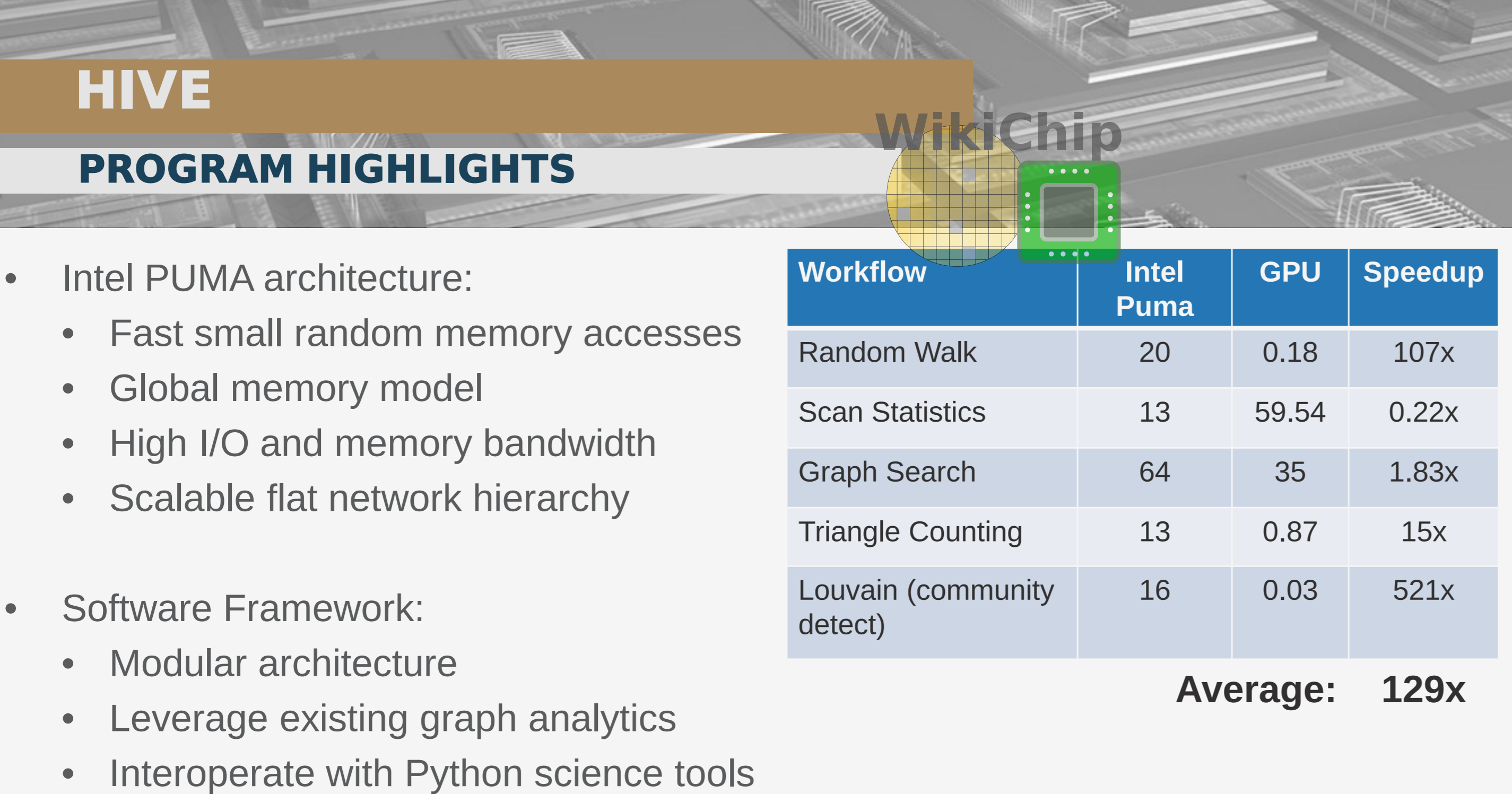
The Hierarchical Identify Verify Exploit (HIVE) program is an ongoing DARPA program that is attempting to address those shortcomings. HIVE is taking a two-pronged approach: new hardware and new software. For the hardware component of the program, a next-generation ASIC for the processing of graph data is being developed. For the software component, a new full-stack graph framework is being developed. With the specialized graph processor and an optimized software stack, DARPA hopes to achieve a 1000x higher performance efficiency than current best-in-class GPUs.
At the DARPA ERI Summit which was held late last month, Peter Wang gave a status update on the program. Wang is the co-founder and CTO of Anaconda, Inc. He is also the principal investigator for the software architecture of HIVE.
Introducing Intel PUMA
Intel is responsible for the hardware architecture part of HIVE and they have been working on a new architecture that tries to address those issues. Inside Intel’s Data Center Group (DCG) is a secret team, the PUMA team. They are responsible for the development of the Graph Analytics (GA) processor. This is a complete product they are secretly working on which Intel intends on eventually commercializing.
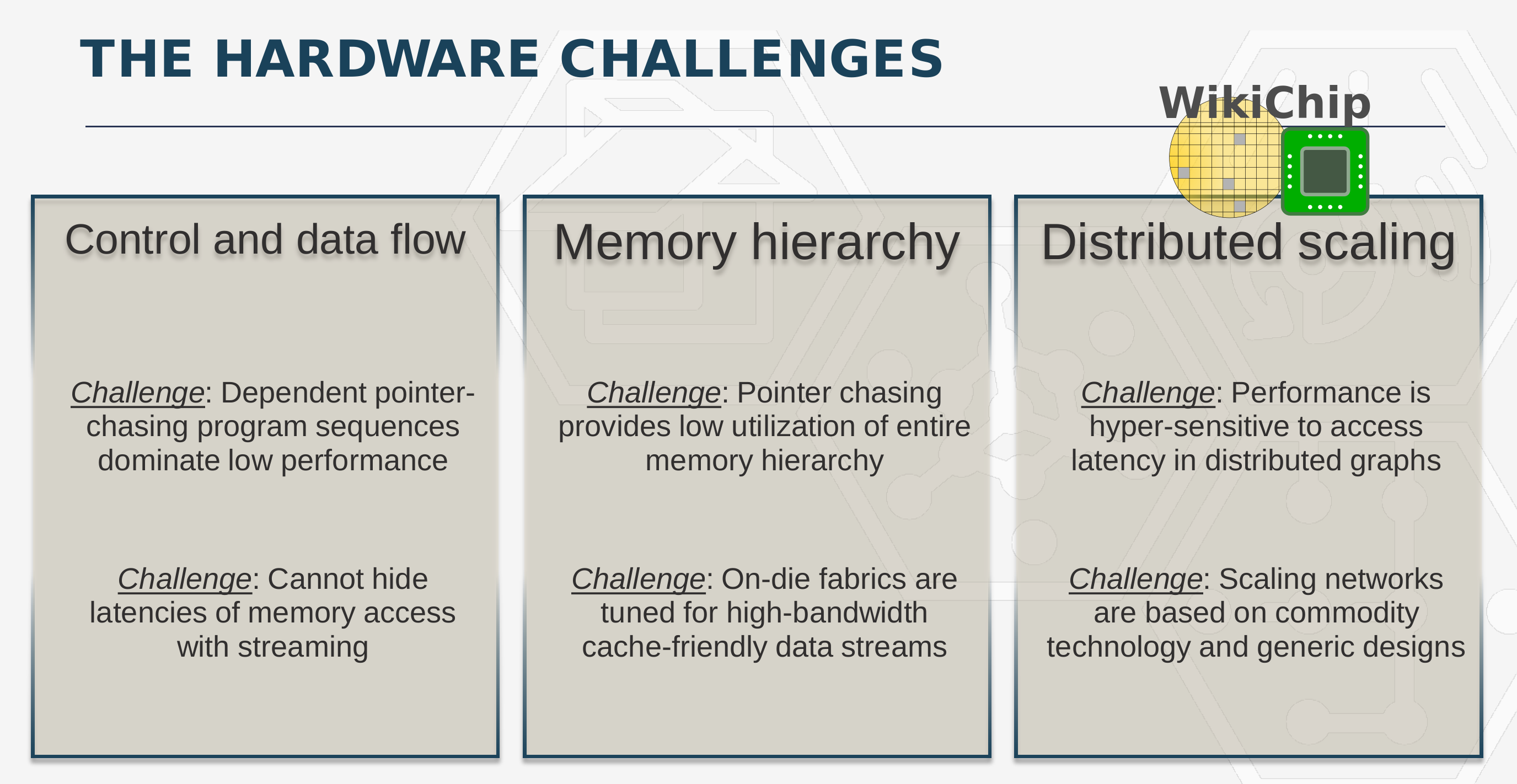
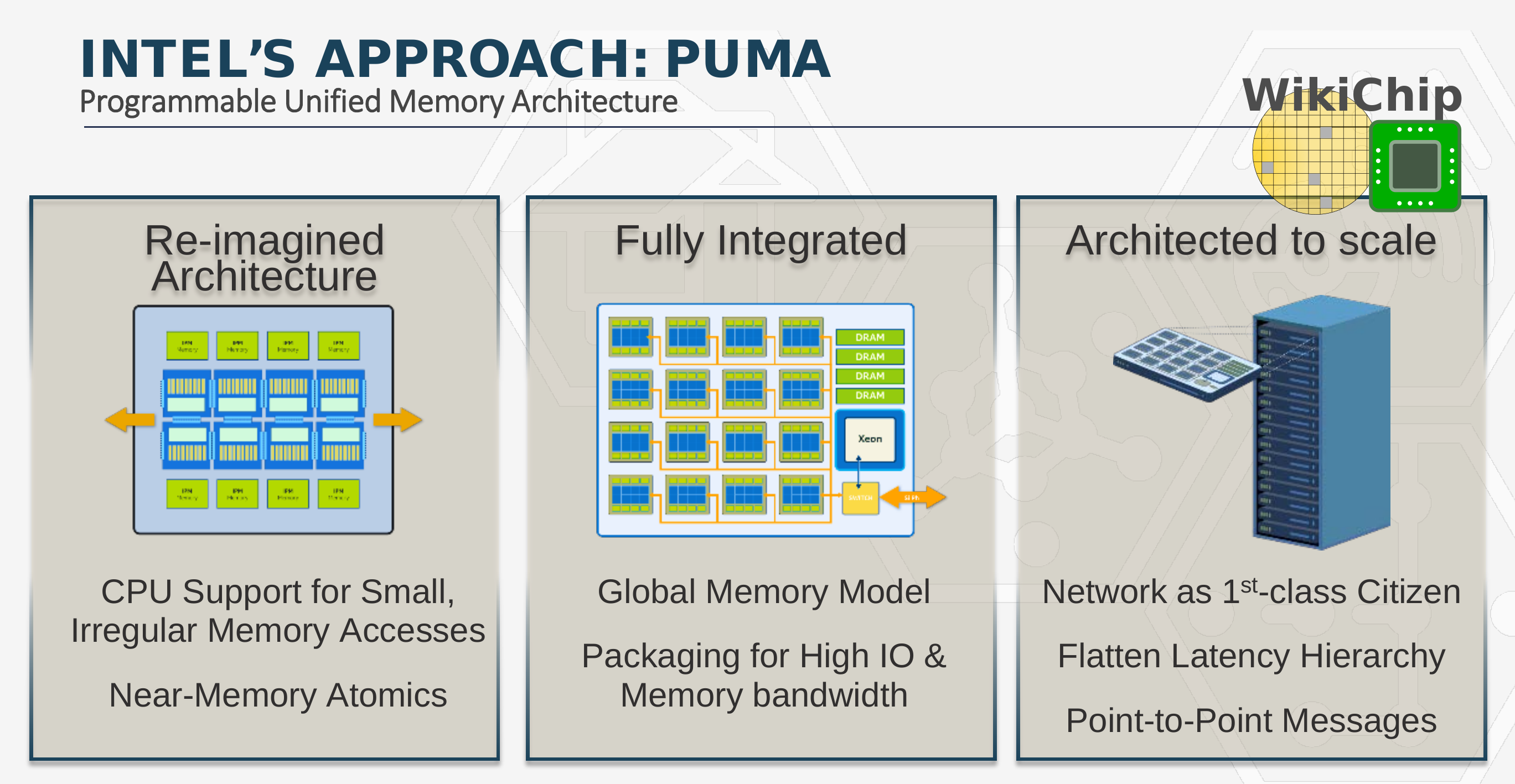
The new graph processor is based on a newly developed architecture called the Programmable Unified Memory Architecture or PUMA. This is a new architecture designed for small irregular memory accesses across a globally-unified memory space. Under this architecture, the chip forgoes many of the fundamental assumptions that are used by modern CPUs and GPUs – it does not assumes it has all the memory nearby, it does not assume that a memory access will repeat itself in the near future, and it does not assume that a memory access to a specific address means nearby memory addresses will also get accessed. “By throwing away those basic assumptions, you build an entirely different hardware architecture around small accesses to globally unified data, and then at every stage, every time there is a wire interconnect or anything connecting one compute unit to some other data unit or other compute unit, every single point is optimized for latency,†Wang said. PUMA fundamentally changed the behavior associated with memory accesses, making memory accesses that are small, efficient, and making the latencies for accessing those memories longer but flattened across the entire system.
PUMA is fully integrated at the chassis level with good communication across processing elements, memory. It is designed to scale to large systems, across multiple racks and multiple clusters.
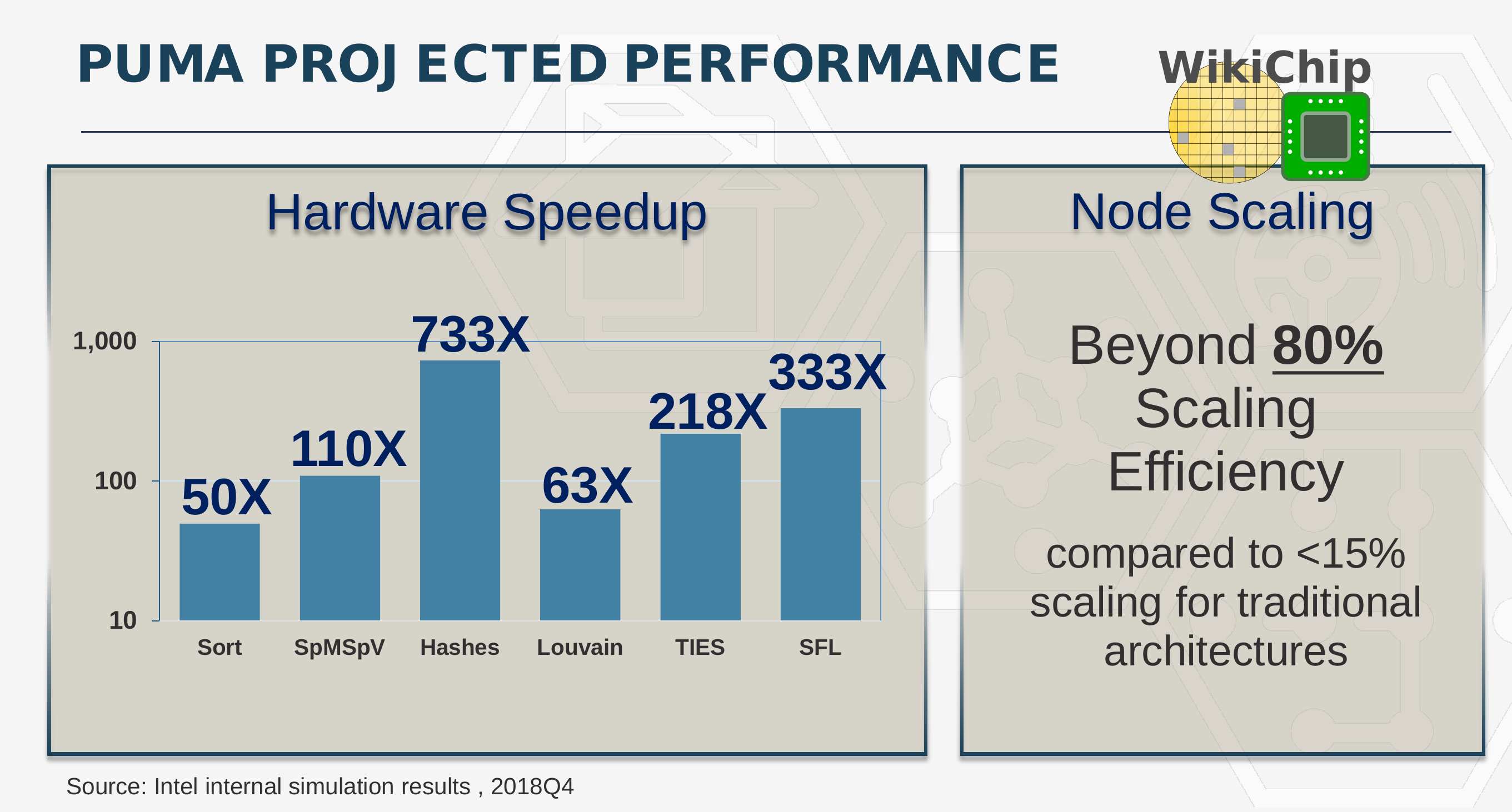
Wang presented some initial performance figures based on internal simulation results from Intel. “The node scaling is really the critical problem. When we talk about trillions of edges, we know those numbers are going to get bigger,†Wang said. To that end, Wang is reporting beyond 80% scaling efficiency. “What this allows us to do is actually parallelize our approach to graph problems,†Wang added.
Software Infrastructure
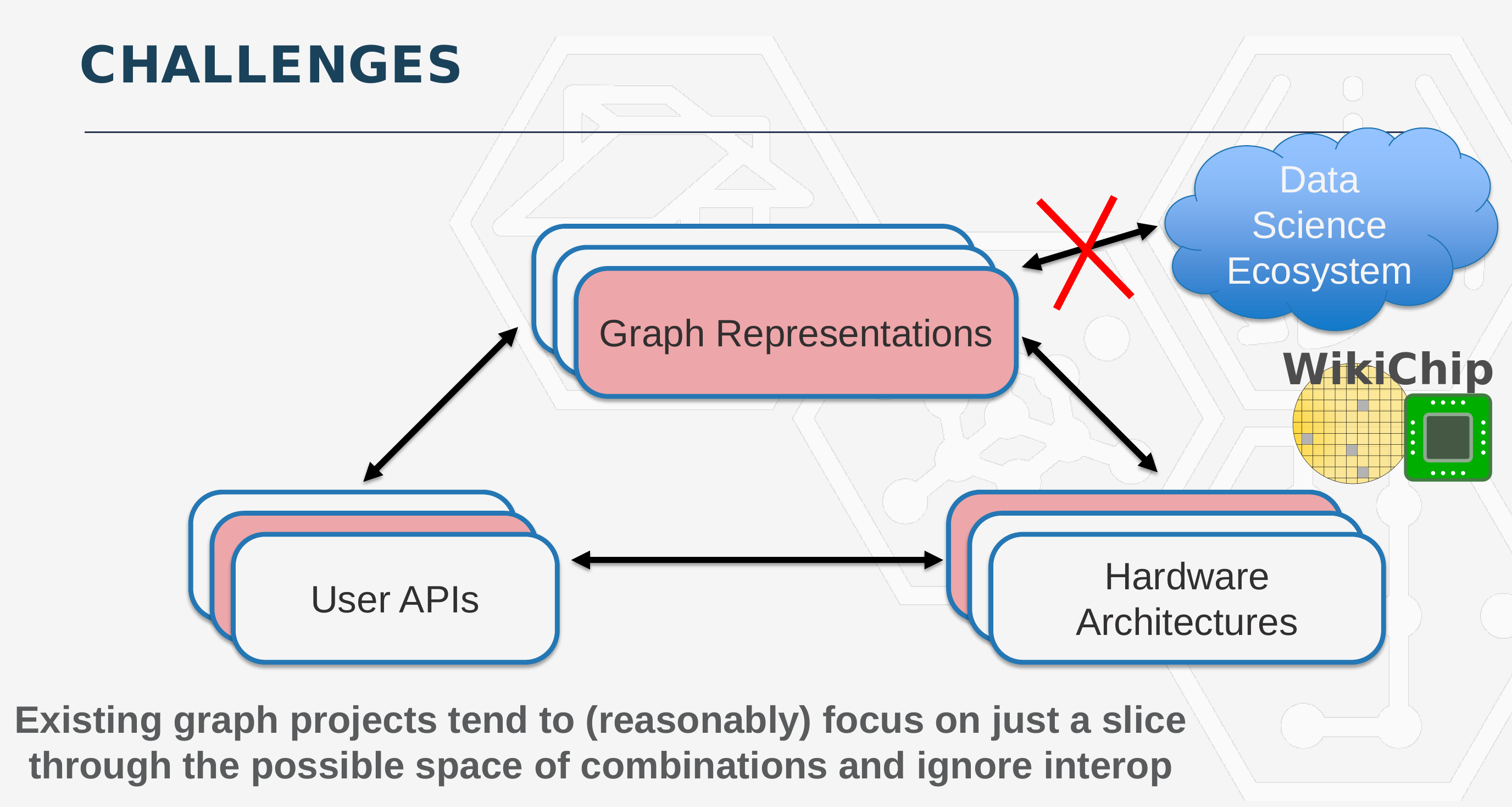
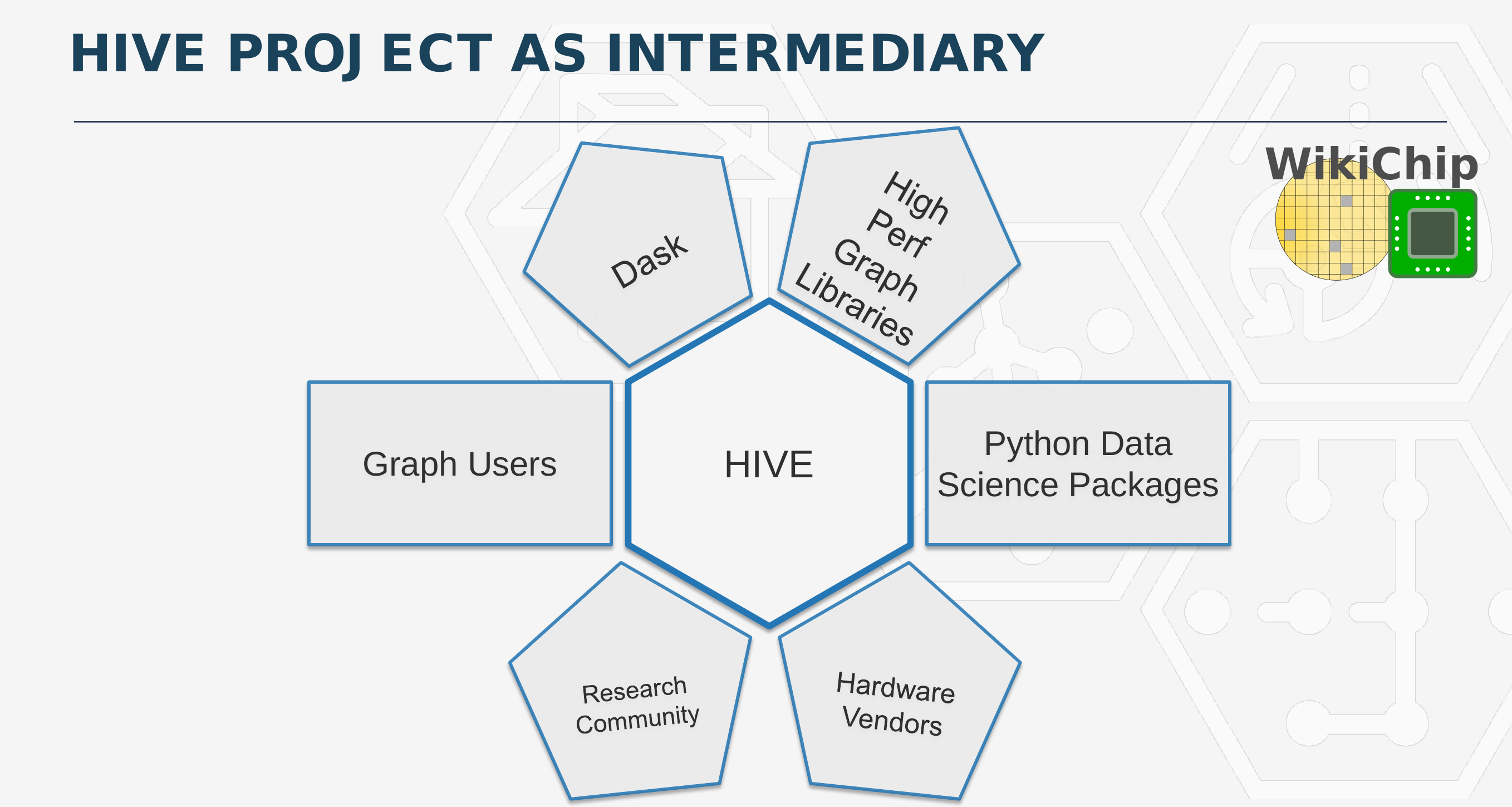
The second phase of HIVE is building the software infrastructure. The new software must not only work well with the new hardware but also with existing CPUs and GPUs. Additionally, the new software must work with a large amount of existing software that is actively used by the data science community. There is a large collection of existing software that has been developed to solve particular graph-based problems in a certain way. Part of the goal of this program is to be able to hook up existing software and libraries into the HIVE software framework in order to streamline onboarding.
Current software consists of algorithms that were exposed via APIs, an internal graph representation of the data, and a hardware backend (GPUs, CPUs, FPGAs, or ASICs). Wang explained that under the current platforms, major tradeoffs must be made, whether it is optimized for a certain type of hardware or certain algorithms. “If you specialize for graph representation, then you disconnect from the data science ecosystem because you are cut off from some major libraries,” Wang said.
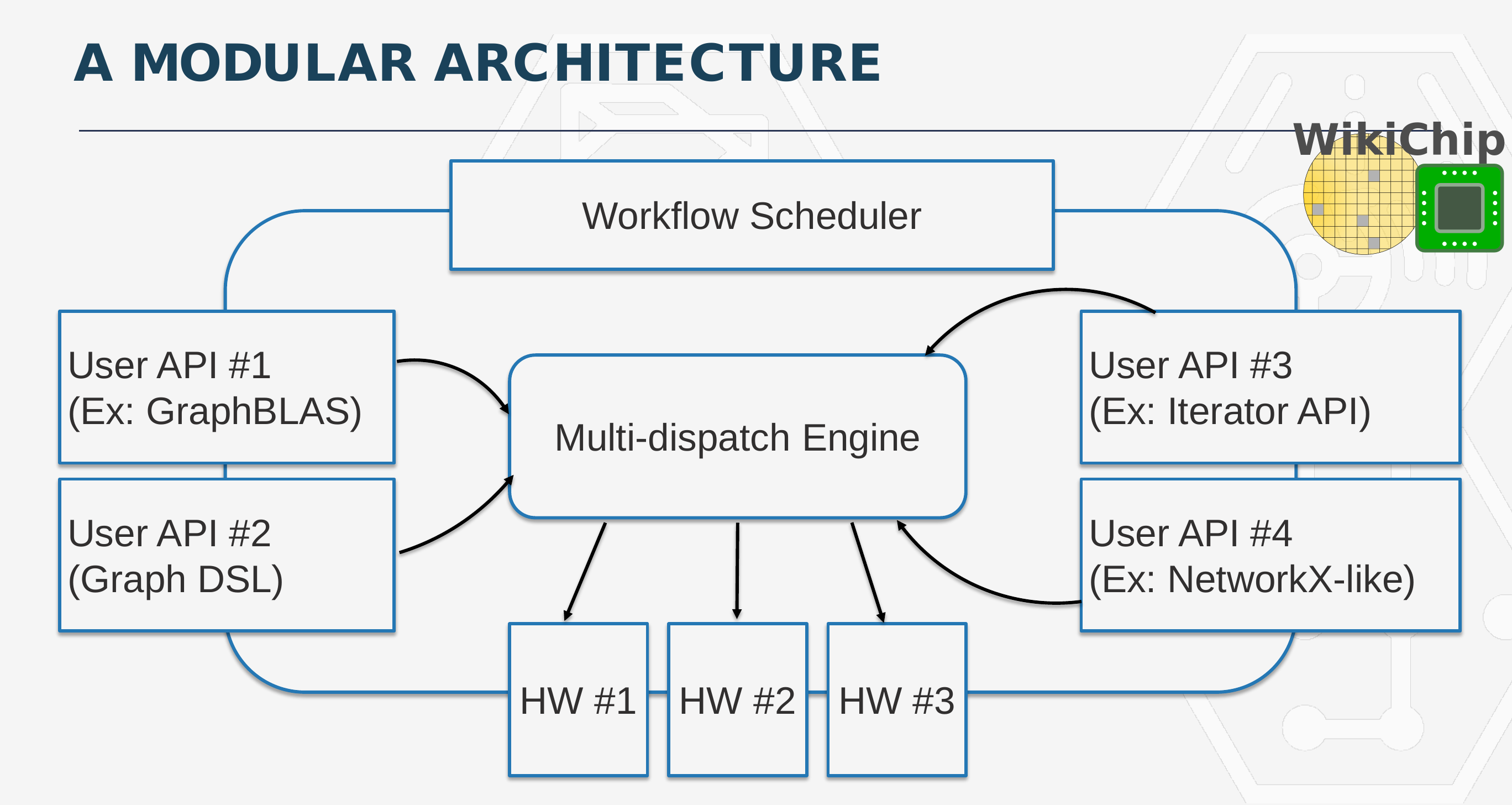
As part of phase 2 of HIVE, they are developing a modular architecture framework. Existing software is getting refactored into their constituent parts so that they could be plugged into the framework based on what that piece of software does best. The architecture comprises a Workflow Scheduler and a Dispatch Engine which are used to route User API workload tasks to the backend. They make use of the DASK task scheduler to do this. This is also how they do backend switching and scheduling. By the way, it’s important to note that while they are working closely with Intel to co-develop this framework so that it is able to achieve their performance targets with the PUMA architecture, the software framework is not designed exclusively for PUMA. In fact, they fully intend on targeting a broad range of hardware, so data scientist could leverage the same software infrastructure across CPUs, GPUs, and FPGAs right away. And ultimately use the same infrastructure to speed up the same workload using the PUMA graph processor.
It’s worth pointing out that, if necessary, on the backend, the framework includes a set of transformers that are capable of translating data between different kinds of formats.
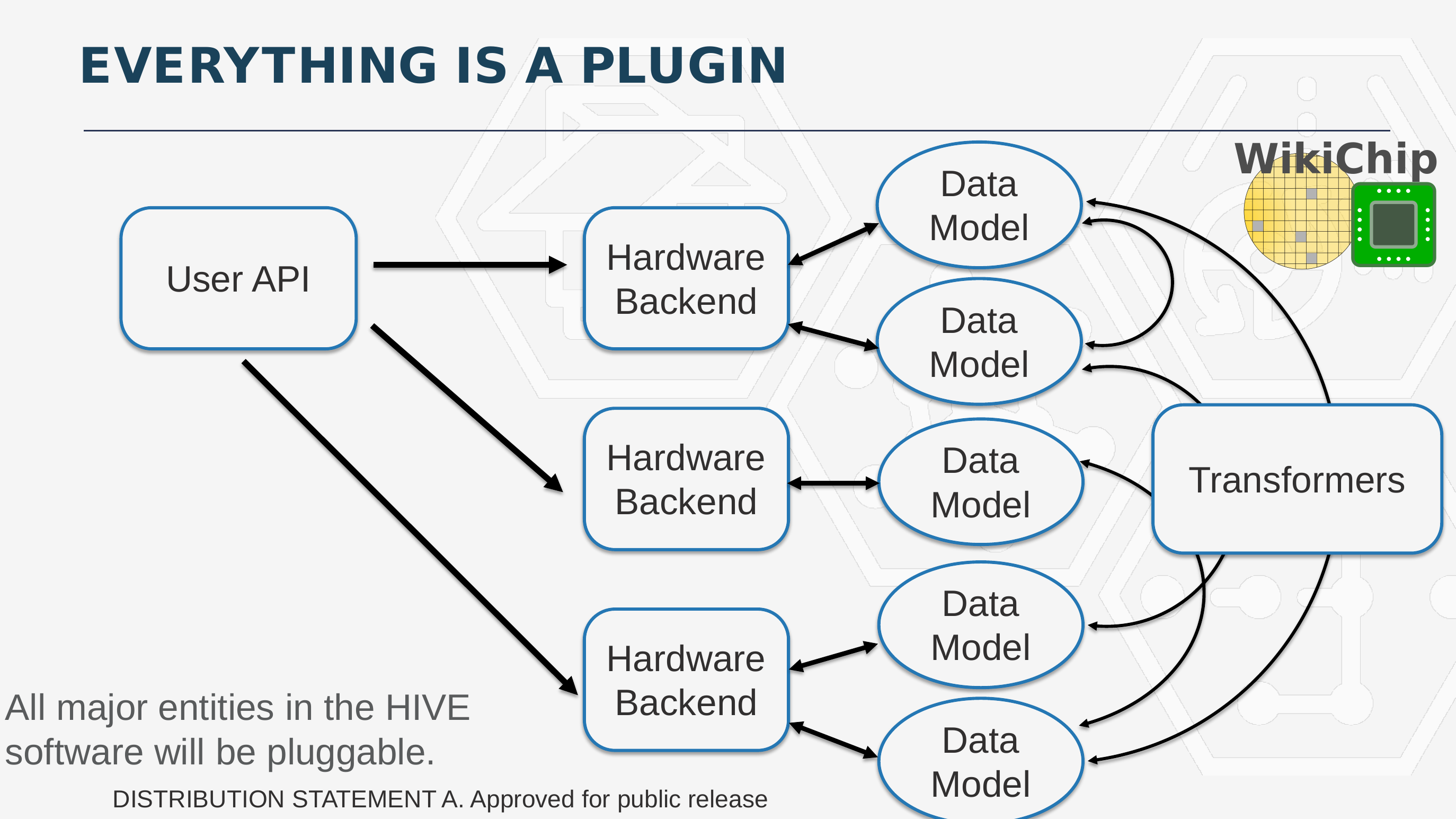
This design provides two major benefits – integrating new hardware means designing a new hardware backend, adding support for the data model if it’s different from existing models, and adding a transformer that can translate from an existing data model to the new one. Likewise, integrating a new User API only requires adding an interface and at least one implementation of the algorithm on one of the hardware choices.
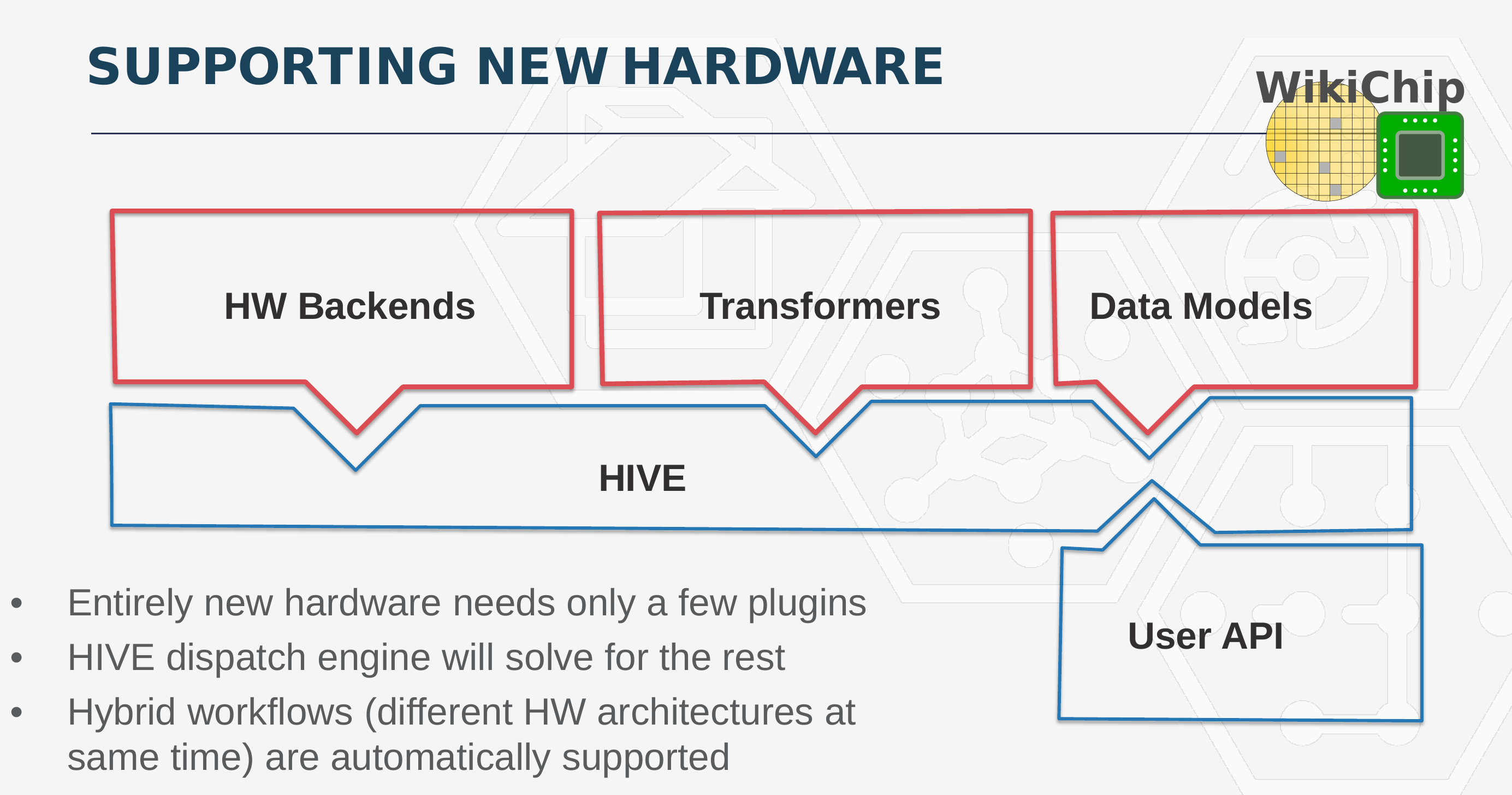
Ultimately, with HIVE, the overarching goal is to unify and streamline the process of getting graph software to talk to hardware in an optimized way by allowing hardware vendors to bring their hardware and integrate a good backend for it while allowing the data scientist to leverage this hardware with their own API and algorithms.
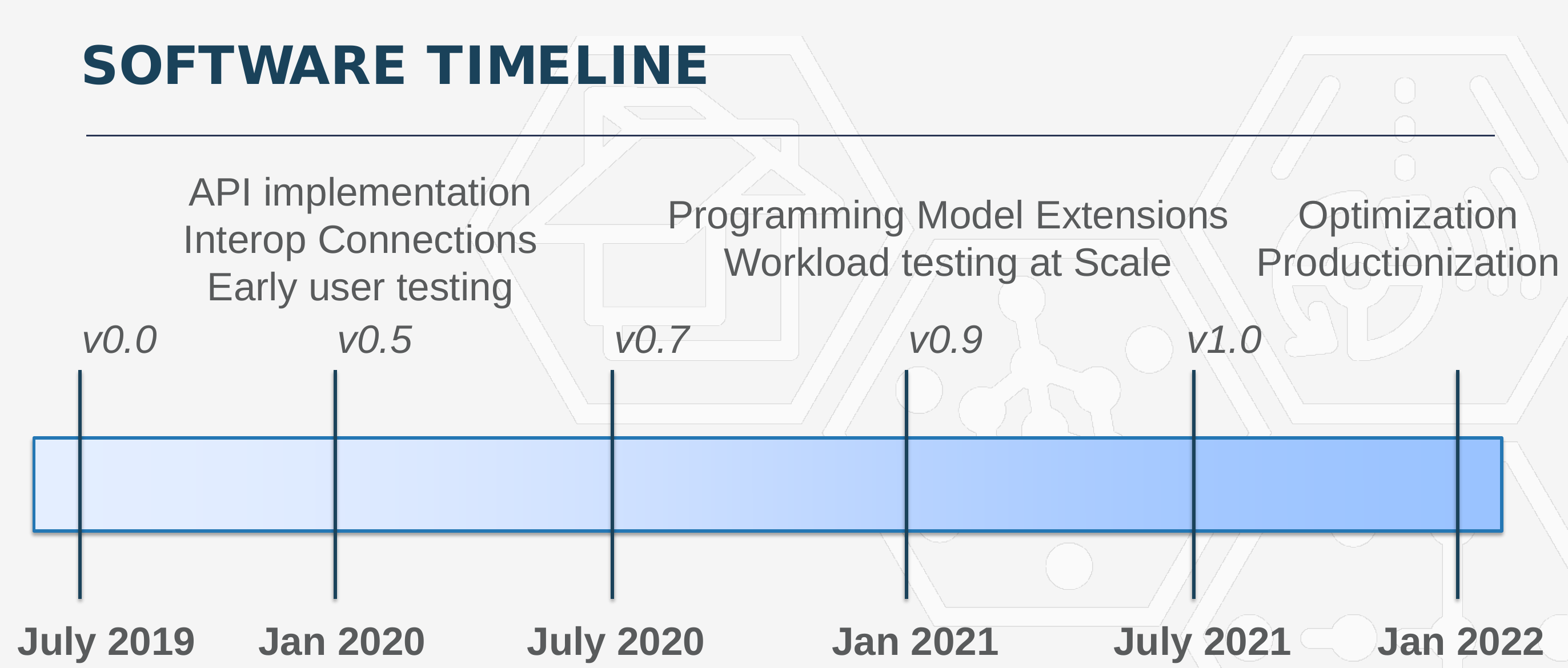
According to Wang, starting next year, users can expect to see the initial source code which will be open source.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–