
Intel Labs Builds A Neuromorphic System With 64 To 768 Loihi Chips: 8 Million To 100 Million Neurons
One of the major features of Loihi is that it integrates neuromorphic cores on a low-overhead scalable NoC fabric. This fabric exposes a parallel I/O interface on the east, west, north, and south sides of the chip in order to allow glueless connection the chip to its neighbor Loihi chips, enabling the formation of larger systems with dozens and even hundreds of chips.
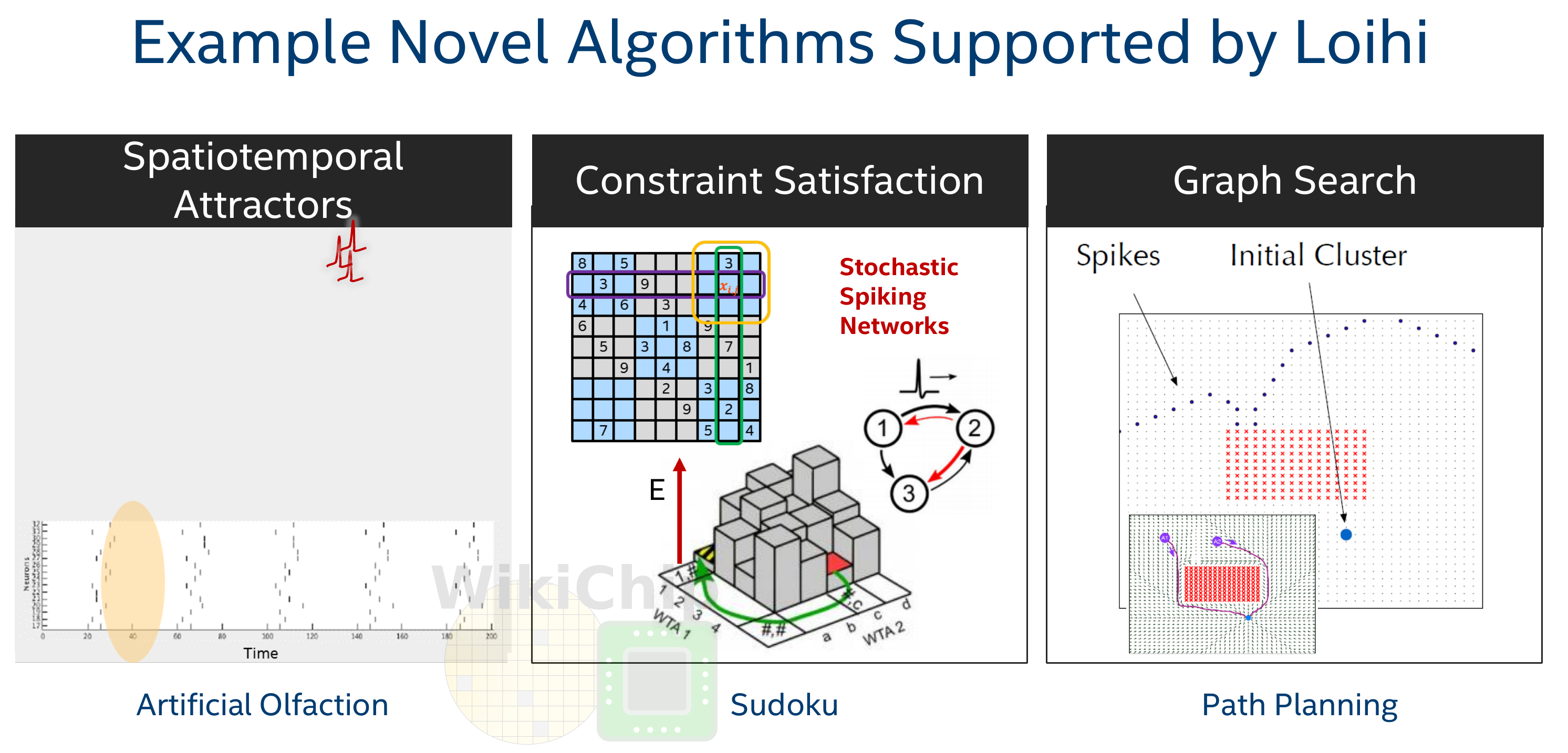
Large-Scale Novel Neural-Inspired Algorithms
The ability to scale the mesh to multiple chips is a fundamental design choice made by Intel Labs in order to build large systems and experiment with new neural-inspired algorithms that were not possible or were rather difficult on a relatively small number of neurons. Mike Davies, Intel’s neuromorphic computing program leader talked about graph search as one of those interesting algorithms they were experimenting with. With graph search, it’s possible to explorers all the different permutations of the spikes propagating through a network. By following the effects of Spike-Timing-Dependent-Plasticity (STDP), it’s possible to discover the shortest gradient path to a destination. This allows you to trace all paths from a source to a destination. Graph search on a neuromorphic chip tends to scale much better than conventional systems. Other algorithms include spatiotemporal attractors which rely on attractions being associated with certain temporal spikes. This is done through iterative cycles from rhythmic synchronization generally in the gamma frequency range (30 iterations per second etc…) which results in very distinct spiking firing patterns. Lastly, various they are also exploring algorithms that deal with stochastic-spiking neuronal networks intended for solving constraint satisfaction/Markov chain Monte Carlo (MCMC) related problems.
When Loihi was first introduced in 2017, they made it available to researchers through Wolf Mountain. Wolf Mountain is a board with 4 Loihi chips. This gave researchers access to a system with roughly 500K neurons and 500M synapses.

Late last year Intel followed up with Nahuku. Nahuku is an Arria10 FPGA expansion board with up to 32 Loihi chips. At its biggest configuration, the board has 16 chips on each side organized in a mesh of 4×4.

With 32 chips on each Nahuku board, you are now looking at close to 4.2 million neurons and 4.2 billion synapses. Intel designed the Nahuku board as the foundation for constructing larger systems.
| Loihi-Boards | |||
|---|---|---|---|
| Board | Kapoho Bay | Wolf Mountain | Nahuku |
| Configuration | 2 x Loihi | 4 x Loihi | 8-32 x Loihi |
| Neuromorphic Cores | 256 | 512 | 1,024 – 4,096 |
| Neurons | 262K | 524K | 1 – 4.2 Million |
| Synapses | 260 Million | 520 Million | 1 – 4.16 Billion |
Introducing Pohoiki Beach And Springs

Pohoiki Beach And Pohoiki Springs are the next two evolutionary steps. Pohoiki Beach is a system the comprises two Nahuku board, doubling chips to 64 with more than eight million neurons. Intel says that the boards are now available to the broader research community. Pohoiki Springs is one step further. This a system with 24 cards organized in 8 rows and 3 slots per row. This means a fully populated system will incorporate 768 Loihi chips. Pohoiki Springs will be made available later this year.
| Nahuku-Board Systems | |||
|---|---|---|---|
| System | Nahuku | Pohoiki Beach | Pohoiki Springs |
| Configuration | Base | 2 x Nahuku | 3 x 8 x Nahuku |
| Loihi Chips | 32 | 64 | 768 |
| Neuromorphic Cores | 4,096 | 8,192 | 98,304 |
| Neurons | 4.2 Million | 8.4 Million | 100.7 Million |
| Synapses | 4.16 Billion | 8.32 Billion | 99.84 Billion |
Neuromorphic Landscape
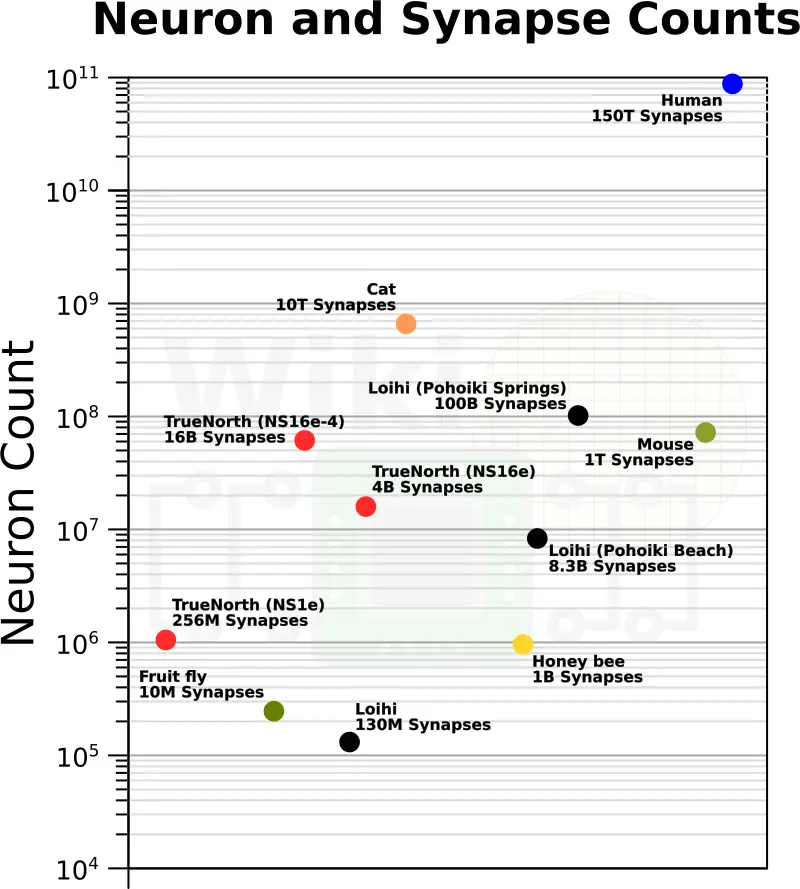
When launched, Pohoiki Springs will be one of the largest neuromorphic systems available to researchers but it’s not the only system. There are currently a number of other interesting research systems being studied. Perhaps the most notable one is IBM’s TrueNorth. Like Intel, in 2016 IBM developed the NS16e board which featured 16 TrueNorth chips and, in theory, could scale up to multiple of such boards. In mid-2017, Air Force Research Lab (AFRL) in collaboration with IBM announced the largest system, the NS16e-4, which incorporated 64 chips for a total of 64 million neurons and 16 billion synapses. One of the strengths of IBM TrueNorth was its high neuron density. Unfortunately, this comes with the disadvantage of no in situ learning, requiring networks to be trained offline. More recently, in the last year, a second-generation, SpiNNaker 2, was announced which is planned for GlobalFoundries 22FDX and will feature 144 processing elements made of Cortex-M4F cores which emulate neurons along with communication hardware and the SpiNNaker spiking network-on-chip handling.
| Recent Neuromorphic Chips | |||
|---|---|---|---|
| System | TrueNorth | Loihi | SpiNNaker 2 |
| Process | 28 nm | 14 nm | 22 nm (FDX) |
| Transistors | 5.4 Billion | 2.07 Billion | |
| Neuromorphic Cores | 4,096 | 128 | 144 |
| Neurons | 1 Million | 131 Thousand | |
| Synapses | 256 Million | 130 Million | |
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–