
Samsung-Esperanto Concept AI-SSD Prototype

Earlier this year we’ve detailed Esperanto’s first neural processor, the ET-SoC-1. The company’s approach for accelerating AI workloads involved integrating a large number of tiny RISC-V cores capable of performing vector and tensor operations. Recently, the company announced that their 7-nanometer ET-SoC-1 chip has returned from the fab, allowing the company to run real code on those chips and experiment with new applications.
While Esperanto is currently working on a number of use cases and applications with customers, at the recent Samsung Foundry event, the company disclosed their ‘AI-SSD’ concept prototype. At the heart of many large-scale consumer-interfacing systems are recommendation engines. The movies you scroll through on Amazon Videos, Netflix, and Hulu, the houses you are shown on Airbnb and Zillow, the posts you see on Twitter and Facebook, and the products you are shown on Home Depot, Walmart, and Amazon are all powered by those recommendation engines. The accuracy of those results can have a significant impact on our daily life.
A typical recommendation engine recommends ‘items’ such as newsfeeds posts based on the user preference as well as historical interactions. In large-scale production data centers (e.g., Google, Facebook, and Amazon), recommendation engines make up upwards of 80% of all the AI workloads being executed. Additionally, despite processing hundreds of different models, the vast majority of them – up to 80% – are dominated by some flavor of embedding-table lookup operations. One such example is shown below.
Earlier this year, at the 2021 ASPLOS conference (see ASPLOS 2021 Wilkening, et al.), Facebook proposed a near data processing solution using an SSD called RecSSD. Below is the recommendation model architecture from their paper. Deep learning-based recommendation models like this comprise both fully connected (FC) layers and embedding tables of various sizes. Those models rely on extremely large data center inputs in order to capture a wide range of user behaviors and preferences in order to deliver more accurate outputs. Continuous inputs are things such as time of day, location, or temperature. Unique to recommendation engines are categorical inputs which include things such as movie titles, product names, users, and brands. While continuous inputs are generally processed as-is in the Bottom Fully Connected (FC) DNN, the categorical features are processed by indexing large embedding tables. As explained in the paper, “Embedding tables are organized such that each row is a unique embedding vector typically comprising 16, 32, or 64 learned features (i.e., number of columns for the table). For each inference, a set of embedding vectors, specified by a list of IDs (e.g., multi-hot encoded categorical inputs) is gathered and aggregated together.” In the example shown below by Facebook, the summation is used to aggregate the embedding vectors but many other operations are also common including averaging, concatenating, and matrix multiplication.
Finally, the output from the Bottom FC and the embedding tables are concatenated and processed through the Top FC to produce the recommendation output. It’s worth noting that inference requests are often batched together to amortize control overhead and save on computational resources.
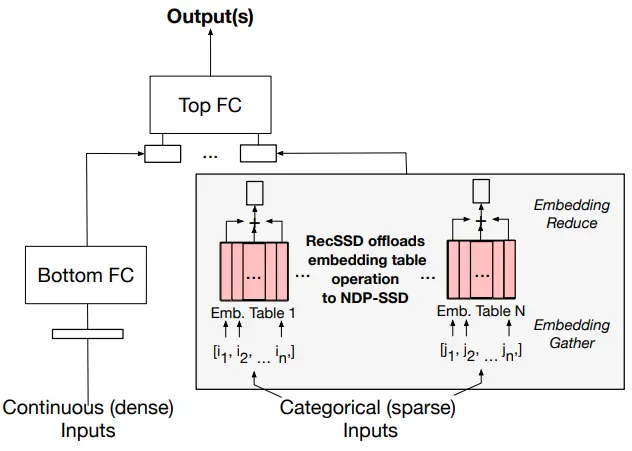
The problem today lies with modern production-scale data center design. Embedding tables are often stored in DRAM while the CPU performs the embedding table operations. According to Facebook, those tables are absolutely massive, often requiring 10s of GBs of storage capacity. “In fact, publications from industry illustrate that the aggregate capacity of all embedding tables in a neural recommendation model can require TBs of storage,” according to the paper. To worsen the problem, categorical input features are generally sparse, producing highly irregular accesses. Because of this, large amounts of the embedding table data are often not resident in memory and have to be requested from the SSD on demand by the CPU.
Esperanto, in collaboration with Samsung, developed a concept AI-SSD prototype in order to investigate the net effect of moving all the embedding tables processing onto the SSD itself, thereby eliminating both the CPU and DRAM from that part of the recommendation model. At the recent Samsung Foundry event, Dr. Jin Kim, Chief Data Scientist and VP of Software presented the AI-SSD concept which utilized a Samsung SSD along with Esperanto’s ET-SoC-1 chip. “The results show that using only a small number of processing elements from our chip, significant end-to-end performance improvements were achieved.”
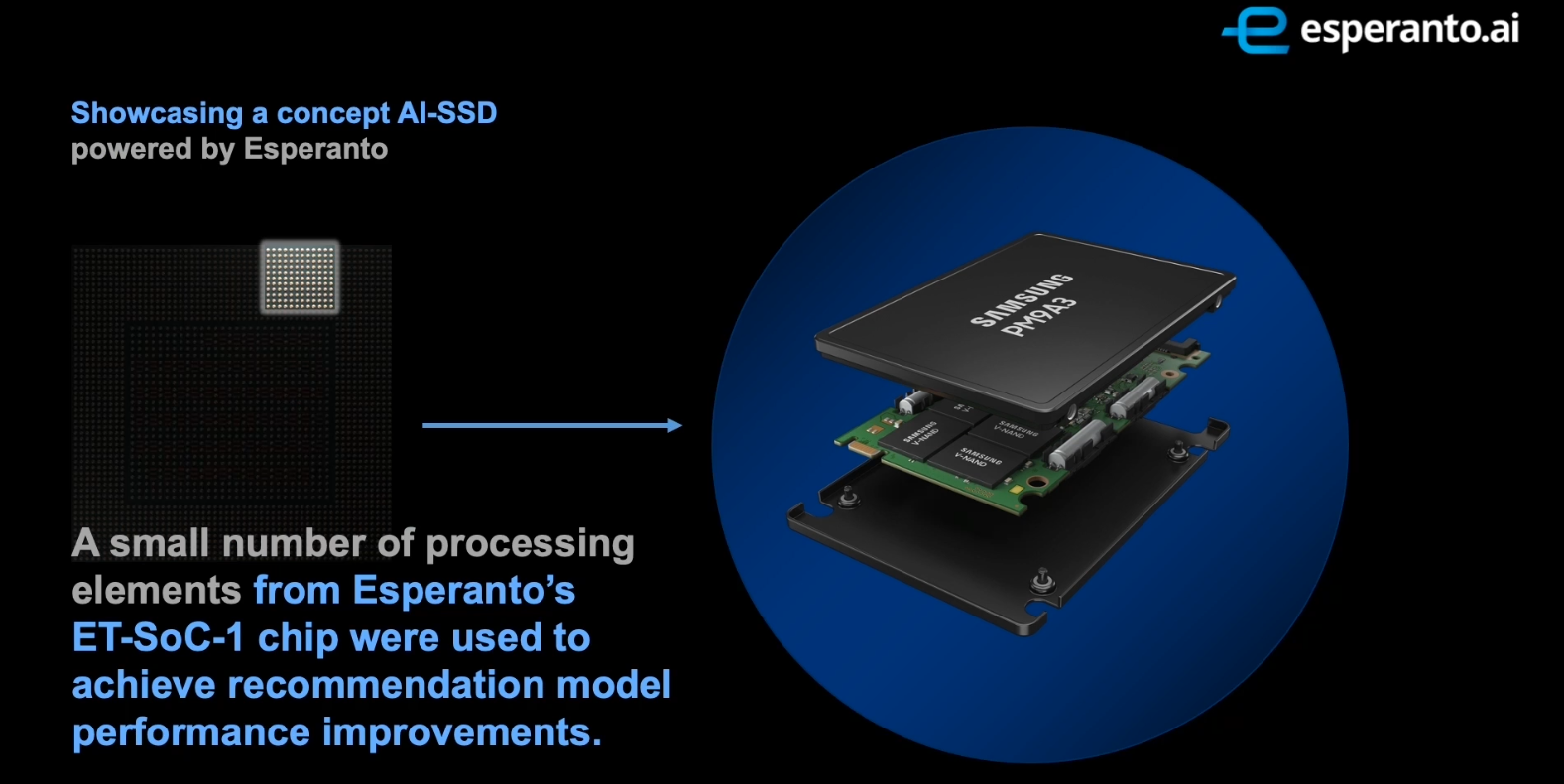
With the AI-SSD, upon a recommendation query arrival, the categorical inputs are immediately sent to the AI-SSD. Instead of storing the embedding tables partially in DRAM and the rest in the SSD, here, everything is stored on the SSD exclusively. While the CPU is processing the continuous inputs and its DNN, the embedded Esperanto chip performs the necessary table lookups, associated feature pulling, and computes the necessary tables interactions. Additionally, the processing within the AI-SSD hides the longer read-write latency by overlapping computations from other layers. With the data remaining on the SSD, minimal data transfers take place across the PCIe link. The final processed categorical data is returned to the CPU to be concatenated with the continuous data which is then processed together to produce the recommendation results.
For their experiments, Esperanto utilized various test configurations from Facebook’s DLRM DL recommendation models. The software was configured such that all the embedding tables operations were on the AI-SSD side while running the computation for all the fully connected layers for the models on the CPU side. When comparing embedding operational latency versus baseline systems, the AI-SSD enables anywhere from 10x to 100x improvement in CPU-SSD bandwidth depending on the model configuration. With the reduced amount of data transferred from the AI-SSD to the CPU, a significant end-to-end latency was also observed.
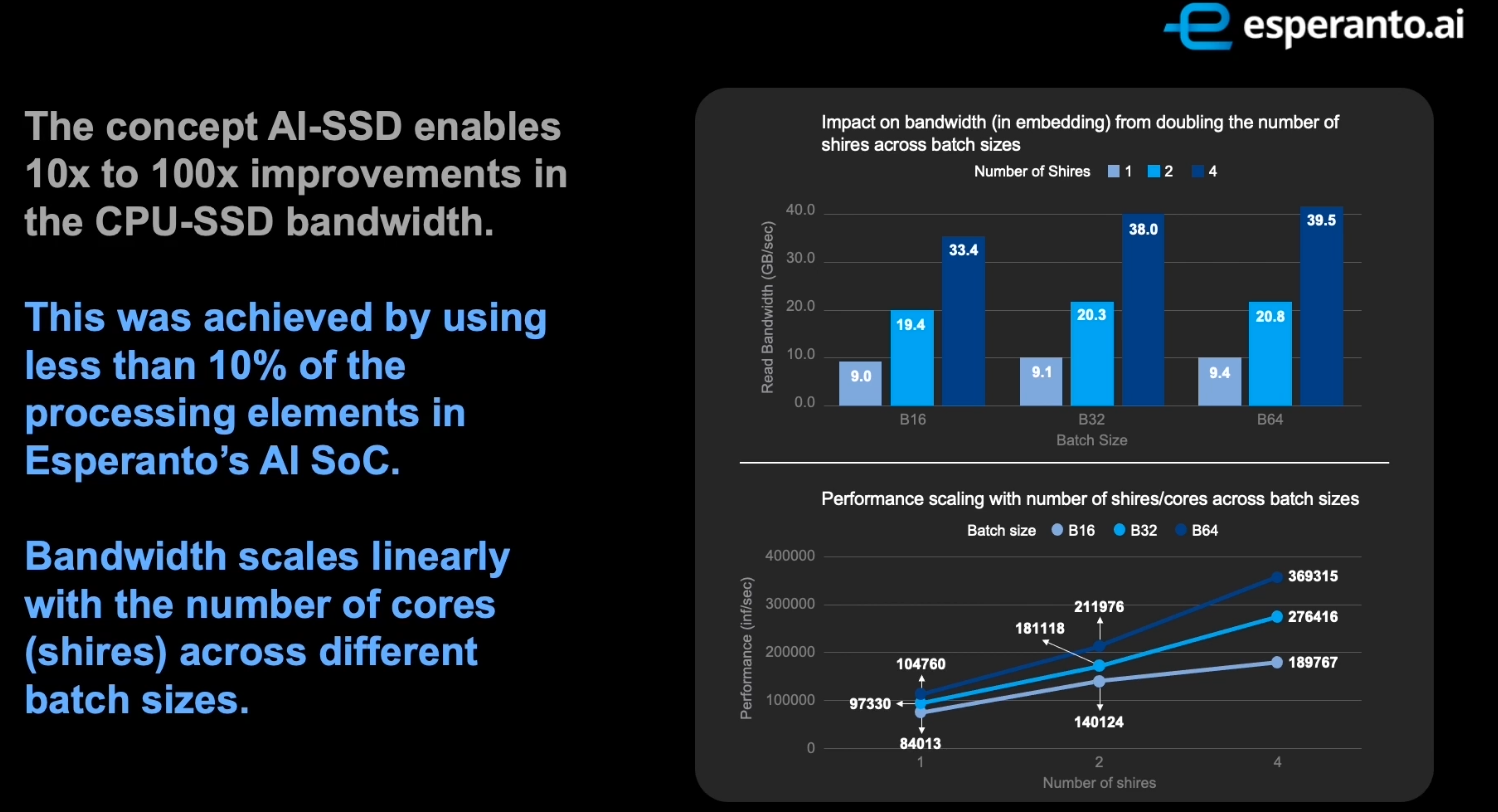
One aspect to note about this experiment is that it was done entirely using up to 4 minion shires. According to Esperanto, the bandwidth scales almost linearly with the number of shires regardless of the batch size. Since each minion shire has 32 cores, this AI-SSD utilized just 32-128 cores out of the 1,088 cores (34 shires in total) available. The ET-SoC-1 is a very large chip and Esperanto’s architecture allows the chip design to just as easily scale further up and further down. With the AI-SSD, it can be seen that a significantly scaled-down version would be a great fit for such applications.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–