
Arm Cortex-X1: The First From The Cortex-X Custom Program
All the way back in 2016, Arm introduced a new customer license called “Built on Cortex”. That license extends the Cortex license in the custom direction. Built-on-Cortex licensees are able to request certain modifications to the standard cortex IP from Arm, and Arm, in-turn, provides that customer with a modified version of the core for their own use only. That license relied on the standard Cortex core as the base template with modifications that include slightly larger buffers or buffers that are altered (shrunk or otherwise) in order to suit particular workloads more optimally. Qualcomm has been a notable licensee of the Built-on-Cortex program.
Today, Arm is making two related announcements. The first is the introduction of the Cortex-X Custom Program, an evolution of the Built-on-Cortex license. Along with that announcement, Arm is also launching the first Cortex-X core in the new series – the Cortex-X1. This core is a much beefier version of the Cortex-A78 which was also announced today, pushing the peak performance even higher.
‣ Arm Unveils the Cortex-A78: When Less Is More
‣ Arm Cortex-X1: The First From The Cortex-X Custom Program
Cortex-X Custom Program
The Cortex-X Custom (CXC) Program is essentially an evolution of the Built-on-Cortex program. At a high level the licenses are very similar, but the end result is quite a bit different. CXC License partners are involved in the Cortex design process much earlier. Arm collects this input from partners and comes up with certain design goal targets that would suit their partners. The CXC program is a performance-first design that builds on top of the latest Cortex-A ‘base template’. In other words, the design that comes out of the CXC program is allowed to relax the traditional power-performance-area (PPA) constraints that confined the Cortex-A in order to yield higher performance, exceeding Arm’s standard Cortex roadmap.
The CXC program is primarily performance-oriented and go well beyond the kind of changes that could be made in the Built-on-Cortex program. In fact, changes are so large that the new core goes by its own new name. When the proposed modifications are implemented and delivered by Arm, they will be announced under the new Cortex-X banner. Changes may be made to the buffers (e.g., wider OoO windows or larger file), they may be made to the execution units (e.g., more execution units), and they may be to the cache subsystem (e.g., larger caches, higher bandwidth, etc).

Introducing The Cortex-X1
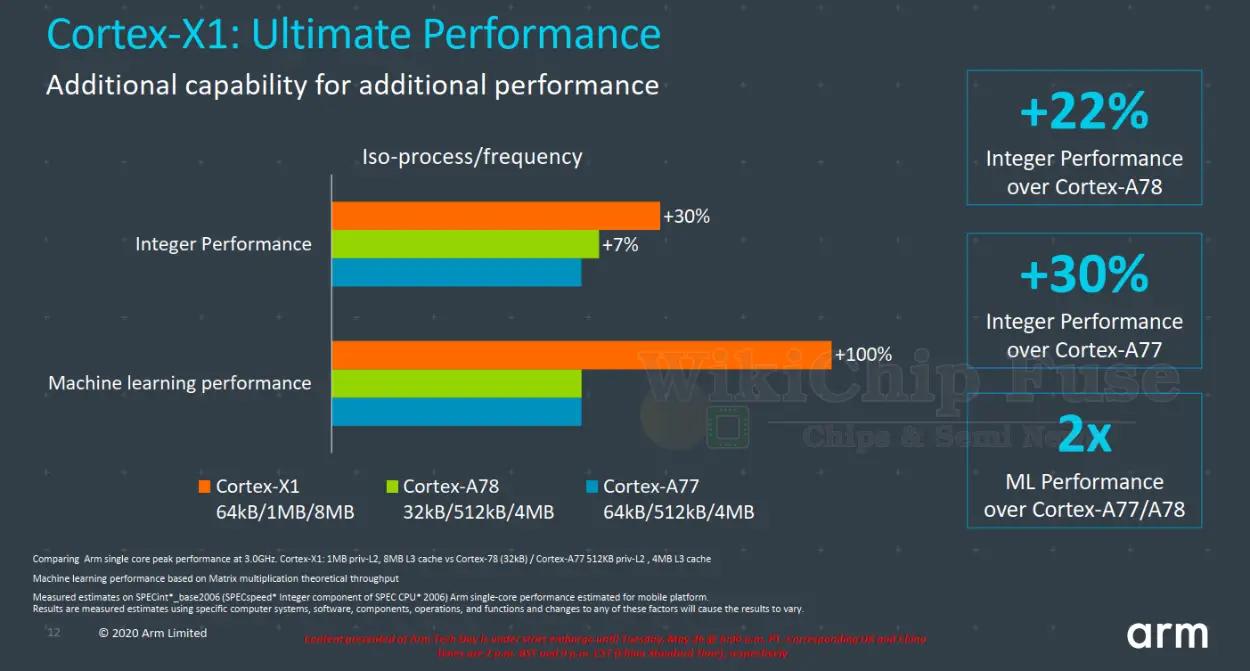
The first core in the new Cortex-X series is appropriately named the Cortex-X1. This is the one and only Cortex-X core. At least for now, all CXC partners get the same core, but there might be further customization per customer in future iterations. The X1 is built on top of the Cortex-A78 which was also announced today. If you haven’t already done so, we recommend you check out the changes in the A78 first. With the custom architectural enhancements that were made in the Cortex-X1, Arm claims the peak performance is about 30% over the Cortex-A77, or roughly 10% beyond what the A78 is able to deliver although in terms of IPC, the X1 pulls significantly ahead of anything Arm introduced before.

Diving a bit deeper into the performance numbers of the new microarchitecture, we can see that architectural changes contributed far more to the X1 than the A78. Whereas at ISO-process and ISO-frequency (3 GHz), the A78 achieves roughly 7% improvement in SPECint 2006 performance over the Cortex-A77, the X1 pushes that improvement by another 23% to 30%. In machine learning performance, the performance the X1 double the peak throughput due to the additional execution units it offers.
As with Arm’s standard Cortex-A cores, the new Cortex-X1 is also designed to be integrated into a DynamIQ cluster in a big.LITTLE – or more appropriately in bigger-big-little configuration. Compared to a quad-core Cortex-A77 cluster fabricated on a 7-nanometer node, a quad-core Cortex-A78 cluster fabricated on a 5-nanometer node will deliver 20% additional sustained performance while using 15% less silicon area. In order to differentiate, a CXC licensee could potentially substitute one of those Cortex-A78 cores for a Cortex-X1 core. Doing so will offer the cluster a 30% peak performance improvement over the Cortex-A77 cluster mentioned earlier. The substitution of the A78 with an X1 does incur substantial area cost. The new cluster is said to be roughly 15% additional silicon area (over the prior A77 cluster). For SoC vendors that want to differentiate themselves with an extra performance boost, the tradeoffs are likely worth it.

High-level differences
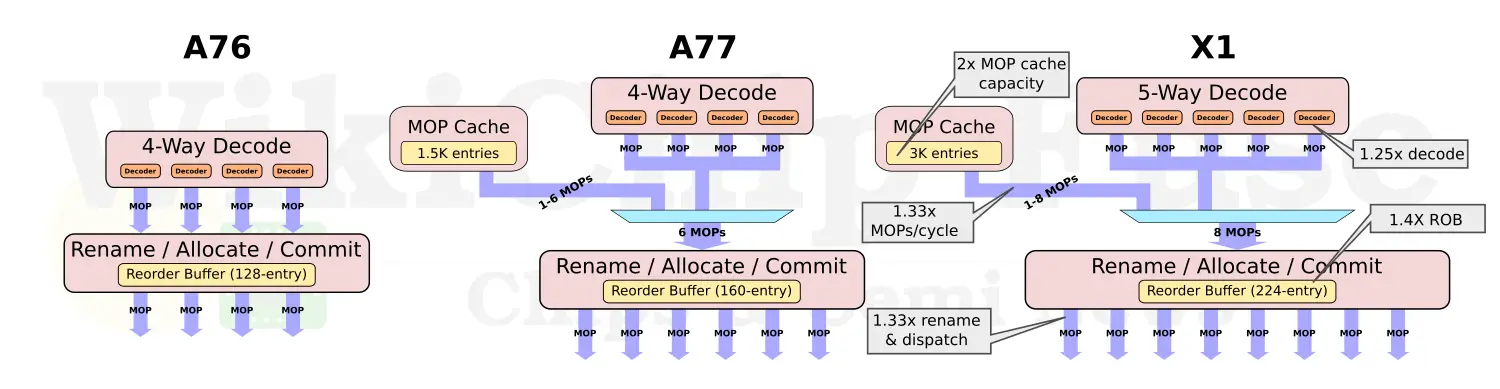
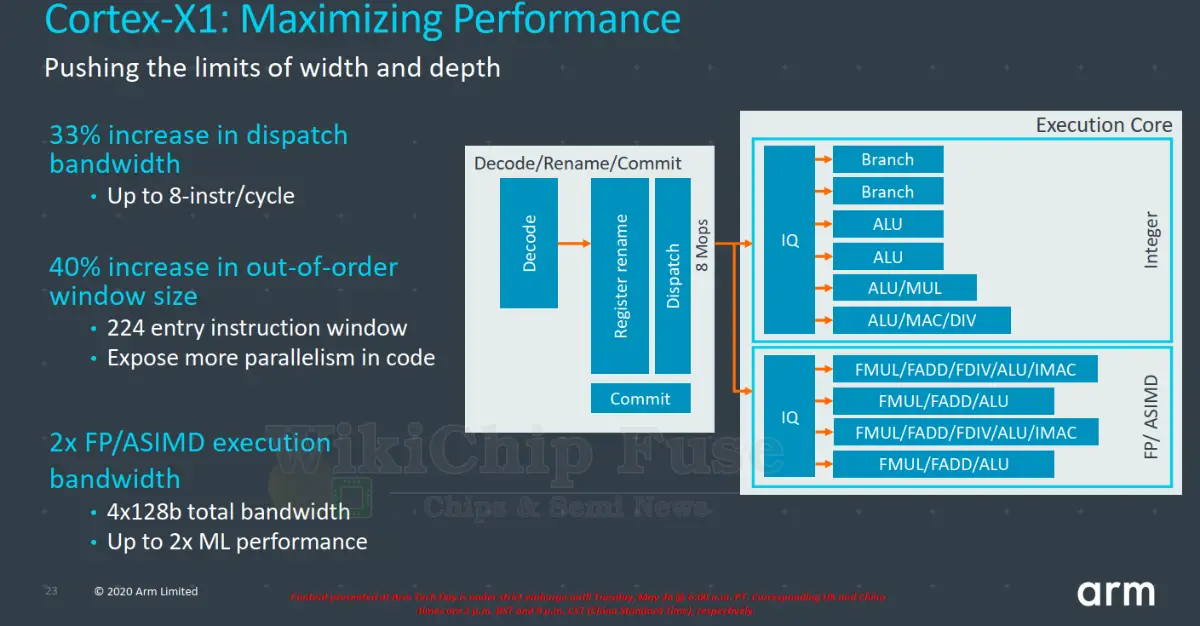
The performance improvements in the X1 versus the A78 comes from a much bigger out-of-order core. The table below highlights the major architectural changes. Compared to the A78, the front-end is vastly wider, capable of decoding up to 5 instructions or stream up to eight pre-decoded MOPs from the MOP cache directly. On the execution side of things, the X1 doubles the number of NEON units which is where the 2x in machine learning performance comes from. Finally, to keep the large buffers fed, the out-of-order window was made much larger along with much bigger caches. We’ll touch on those changes in more detail later.
| Cortex-A78 vs Cortex-X1 | ||
|---|---|---|
| Core | Cortex-A78 | Cortex-X1 |
| Roadmap Core | Custom Core | |
| L1I$ | 32-64 KiB | 64 KiB |
| Decode | 4 inst/cycle | 5 inst/cycle |
| MOP Cache B/W | 6 inst/cycle | 8 inst/cycle |
| L1D$ | 32-64 KiB | 64 KiB |
| L2$ | 128 – 512 KiB | 256 KiB – 1 MiB |
| L3$ | 0 – 4 MiB | 0 – 8 MiB |
Front-End
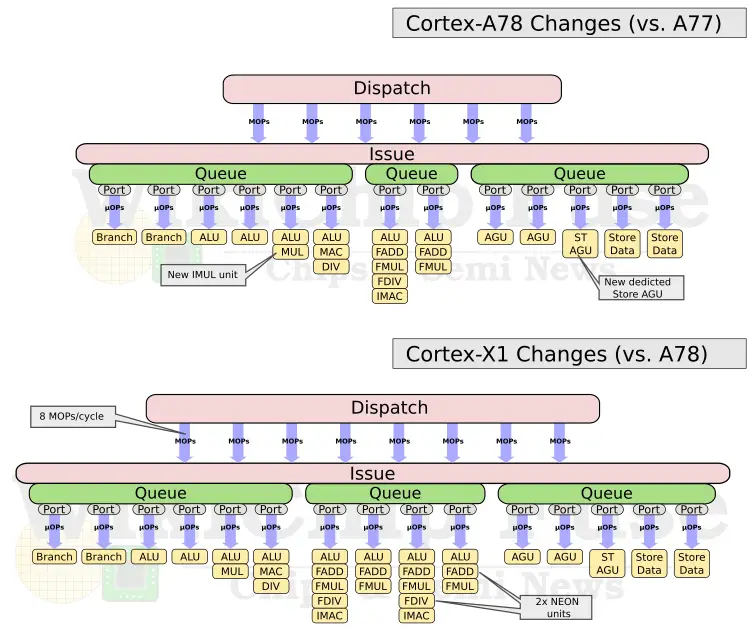
Whereas the Cortex-A78 optimized for efficiency, Arm went all out on what’s possible (within limits) in the front-end of the Cortex-X1. In the BPU, Arm increased the L0 BTB by 50% (from 64-entries to 96). The biggest changes were done to the instruction fetch and decode. The A78, much like the A77 and A76, the pipeline is 4-wide when fetching out of the instruction cache. The A77 introduced a new MOP cache which has a much greater bandwidth capacity of 6 MOPs/cycle. For the Cortex-A78, Arm increased the decode bandwidth by 1.25x to 5 instructions per cycle from the instruction cache and by 1.33x to eight MOPs per cycle when fetching from the MOP cache. Likewise, the pipeline is capable of renaming and retiring up to eight instructions per cycle (for a theoretical maximize IPC of 8). In addition to the bandwidth increase, the capacity of the MOP cache is also doubled to 3K-entries. A 3K-entry MOP cache is really massive, to put it into prospective, it’s larger than Intel Sunny Cove (2.25K) and slightly smaller than AMD Zen 2 (4K).
Back-End
On the execution engine side of the machine, the dispatch bandwidth was also increased by 1.33x to match the bandwidth of the MOP cache – allowing for up to eight MOPs/cycle to be dispatched. In order to accommodate more instructions in-flight and expose more parallelism, the reorder buffer was made larger. Compared to the A77 which had a ROB size of 160 entries, the X1 ROB size is 1.4x larger or 224-entry deep. A ROB size of 224 is coincidentally a recurring theme in recent years – identical in size to both Zen 2 and Skylake.
| Reorder Buffer | |||||
|---|---|---|---|---|---|
| Company | Arm | AMD | Intel | ||
| µarch | Cortex-X1 | Zen | Zen 2 | Coffee Lake | Sunny Cove |
| Renaming | 8/cycle | 6/cycle | 6/cycle | 4/cycle | 5/cycle |
| Max In-flight | 224 | 192 | 224 | 224 | 352 |
More EUs, More FLOPs
On the ASIMD/FP cluster, Arm doubled the execution bandwidth of the NEON units. There are now four 128-bit units capable of a peak performance of 16 FLOPs/cycle or 48 gigaFLOPS at 3 GHz. This is the same peak FLOPs performance as Zen 2 or Coffee Lake. The doubling of the number of NEON execution units is the reason the X1 provides up to twice the ML performance Arm reported.
Memory subsystem
The Cortex-A78 already improved the load and load-data bandwidth therefore there was no need for X1 to adjust this further. Arm did note that the number of in-flight memory operations (i.e. load/store buffers) were increased by 1.33x. The capacity of almost all other memory-related buffers were also increased. The available bandwidth from both the L1 data cache and L2 cache is said to have been doubled compared to the A78. Additionally, in order to assist workloads with large instruction size or data size, the L2 on the X1 supports configurations that can go all the way up to 1 MiB. Likewise, the second-level TLB capacity was increased by 66% to 2K-entries.

Putting it all together
Arm introduced today two major cores – the Cortex-A78 and the Cortex-X1. The A78 went back to the basics and optimized for efficiency. The X1 is using the A78 as an optimized starting point template, but significantly enhances it in order to extract higher single-thread performance by exploiting instruction parallelism. Core design is about making the right compromises. The A78 and X1 is Arm’s attempt at providing their customers with different trade-offs so they could build SoCs that better suit their desired goals.
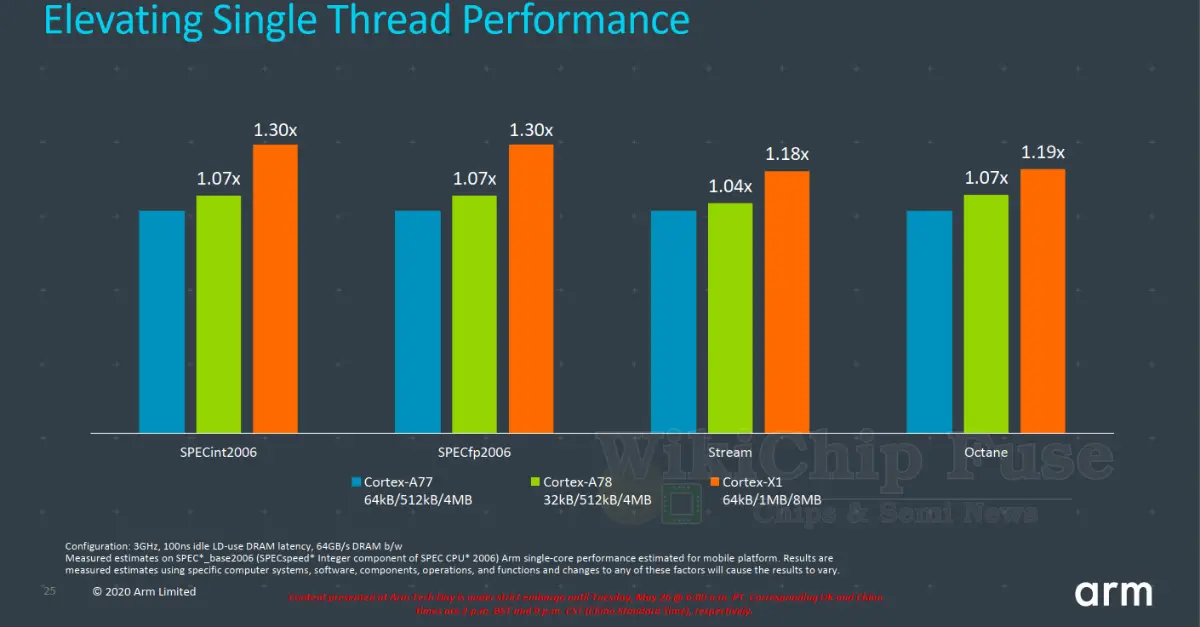
The chart below shows Arm’s reported single-thread performance for the A77, the A78, and the X1. The three representative benchmarks are the SPECint 2006, 1 MiB stream micro benchmark, and the Octane JavaScript Benchmark. The benchmark shows pure IPC gains at ISO-frequency and ISO-memory. Whereas the A78 provides a relatively small IPC improvement of 4-7% (albeit at much higher power-efficiency), the architectural changes in the X1 deliver a 30% improvement on SPEC 2006 and about 18-19% IPC gain in Stream and Octane.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–