
Arm Launches New Neoverse N1 and E1 Server Cores
Neoverse N1
Corename Ares, the Neoverse N1 CPU is designed for performance. Last year, Arm talked about 30% CAGR performance from the Cosmos platform to Ares to Zeus and onward.
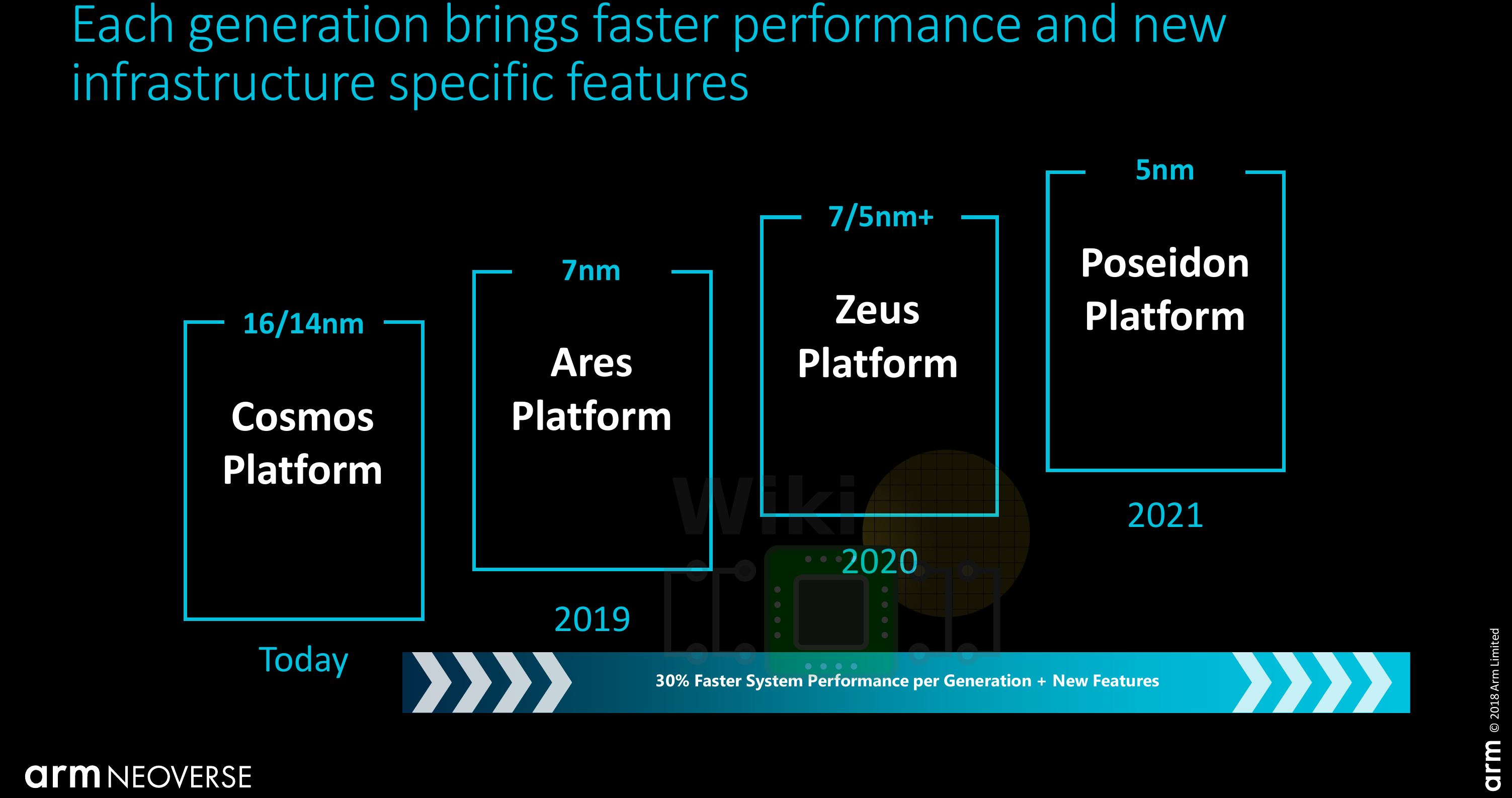
With the launch of the N1 today, Arm has updated their performance estimates, claiming a 60% performance uplift over the Cosmos platform. This number is based on the SPEC CPU2017 integer base (presumably SPECspeed2017_int_base) estimate so we do expect a serious single-thread uplift over prior generations. Arm mentioned a few additional performance benchmarks. Compared to the Cosmos platform (Cortex-A72), Arm is reporting 2.5x the performance for Memcached, 2.5x for NGINX, and 1.7x for Java. Given we prefer an independent third-party review of the product, we won’t dwell on those numbers any more than we have to.
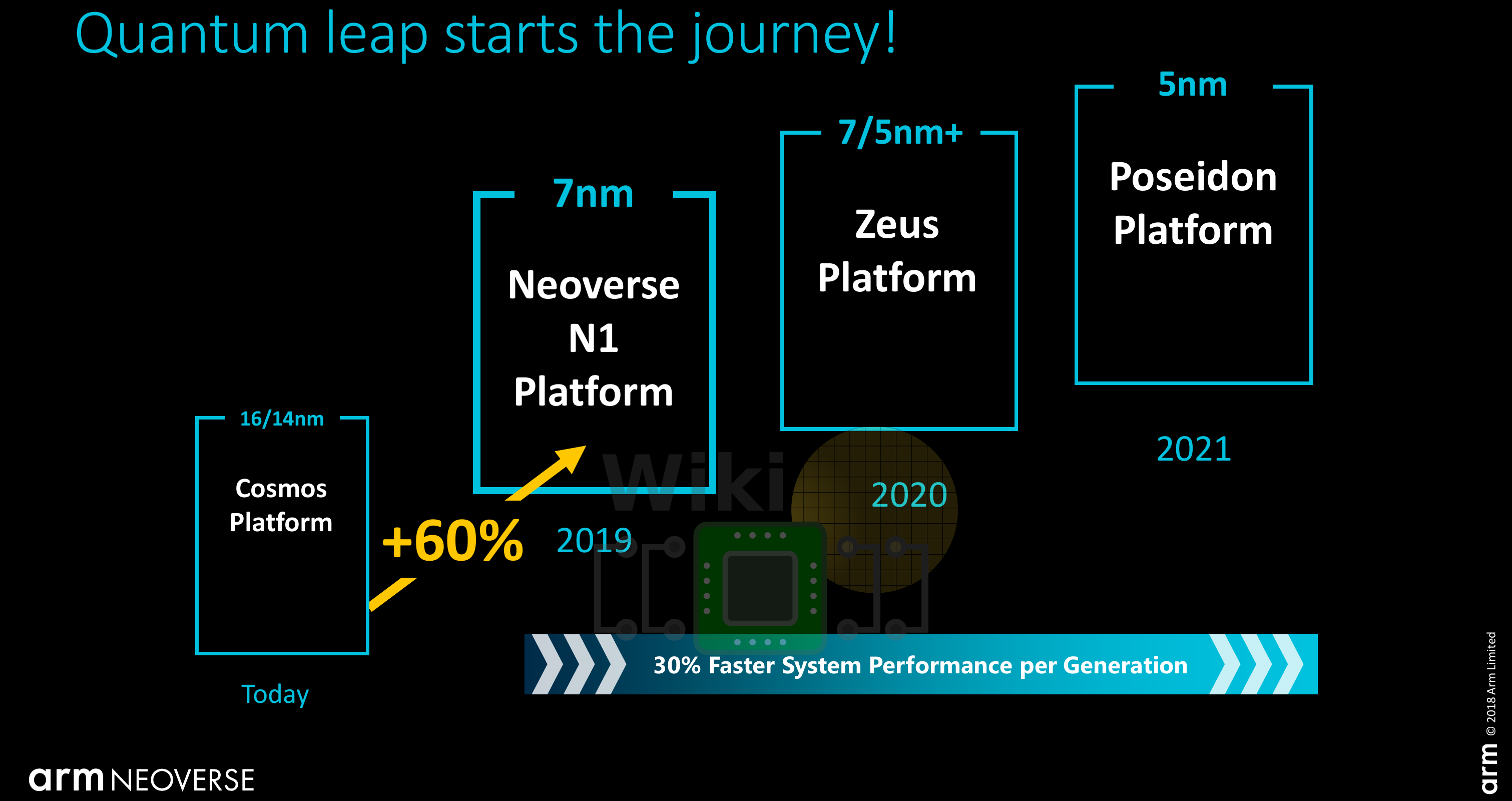
Interestingly, Arm also disclosed some actual SPEC CPU2006 numbers. Based on a 64-core N1 hyperscale reference design, Arm is reporting a throughput (SPECint_rate2006) score of 1310 and an integer latency (SPECint2006) score of 37. This reference design has a TDP of 105 W. It’s a little unfortunate they decided to go with a deprecated SPEC2006 test and not the current SPEC2017 score (which is what their “60%” performance uplift is actually based on). Given there is no itemized breakdown of this score, a true apples-to-apples comparison is rather hard to make but it’s a very respectable score within a 105 W TDP power envelope. In terms of single-thread performance, this is considerably better than the Cosmos platform. Nonetheless, this is a very solid first-generation core in the server space.

As expected from a server-based design, the Ares design goals are different from that of the client core (Cortex-based designs). Ares is a new from-scratch design intended to serve as the foundation for a new family of infrastructure-focused cores. High-performance is a priority while delivering a balanced power and area efficiency. To that end, full-frequency sustained performance and peak performance was one of the important design vectors.
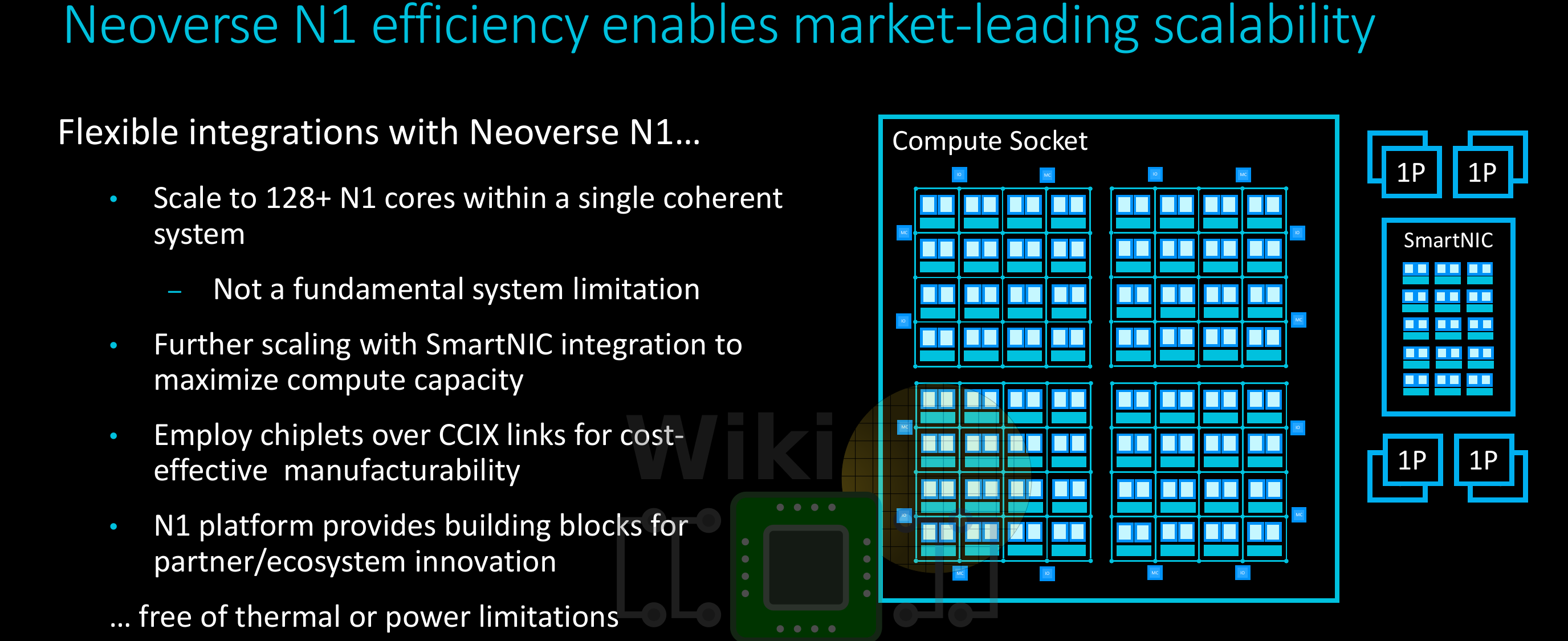
Ares is scalable. Taking advantage of Arm’s Coherent Mesh Network 600 (CMN-600) mesh architecture, a full Ares SoC is designed to scale from as little as 4 cores to as much as 128 cores. On the low side, for networking and storage, the N1 targets 8 to 32-core designs with a TDP in the range of 25 to 65 W. On the edge other similar endpoints (e.g., 5G base stations), 16-64 core designs targeting TDPs in the range 35 W to 105 W. At the other side of the scale, for hyperscale data centers, the N1 targets designs with 64 to as much as 128 cores with 150 W and above.

Scaling the number of core takes advantage of the CMN-600 design.
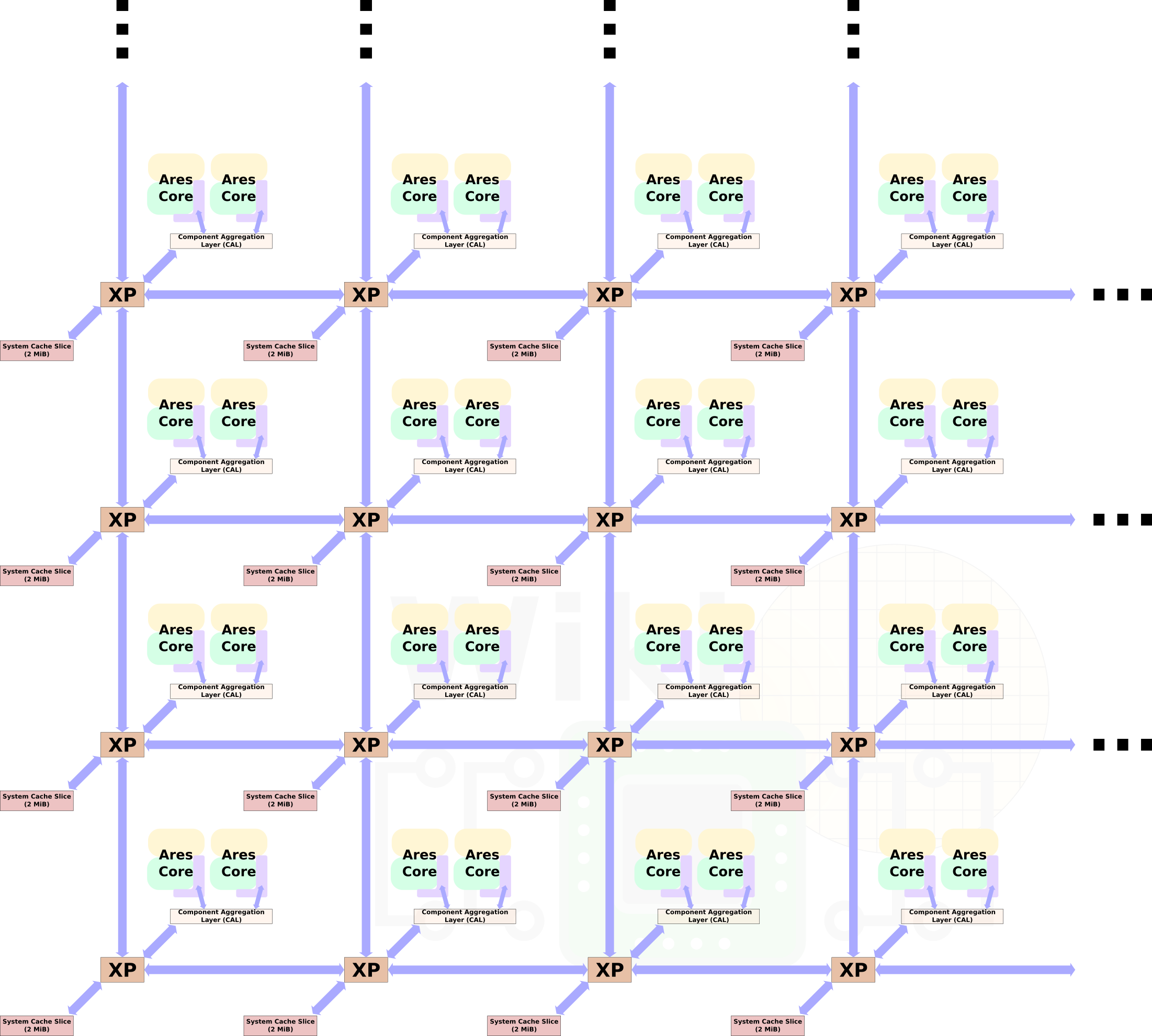
There are two Neoverse N1 cores per node sitting on the same crosspoint (XP) via the component aggregation layer which allows for two identical devices to sit on the same XP port. Ares features 1 MiB of shared system level cache (SLC) per core. Since the N1 is partitioned as duplexes, there is a 2 MiB bank per duplex. Thus a 32-core design (such as the one showed in the diagram above) features 16 SLC banks for a total of 32 MiB of cache. The largest design with 128 cores will have 64 banks for a total of 128 MiB system-level cache. In Arm’s reference design with 64 cores and 32 banks (64 MiB), there is a 22 ns latency load-to-use. The SLC has a bandwidth of over 1 TB/s and prefetching, DRAM-targeted prefetching, and direct memory-controller-to-CPU data transfers all in an attempt to reduce latency and improve the system bandwidth.
For large integrations, there are a number of enhancements and features that are coming together to make things easier. Arm introduced a number of additional enhancements. Ares provides instruction cache coherency designed to reduce traffic. Supporting ARMv8.1 means support for atomic instructions extension which benefits large multi-core systems. The extension includes instructions such as compare and swap, swap, and atomic memory operations (LD[OP]/ST[OP]) enabling the reading and writing of memory values, performing an operation on those values, and writing the result back to memory. A few other features listed were direct-connect interconnect (note this only applies when there is one core per node), direct peer-to-peer transactions, and system-level cache stashing to preload CPU caches.
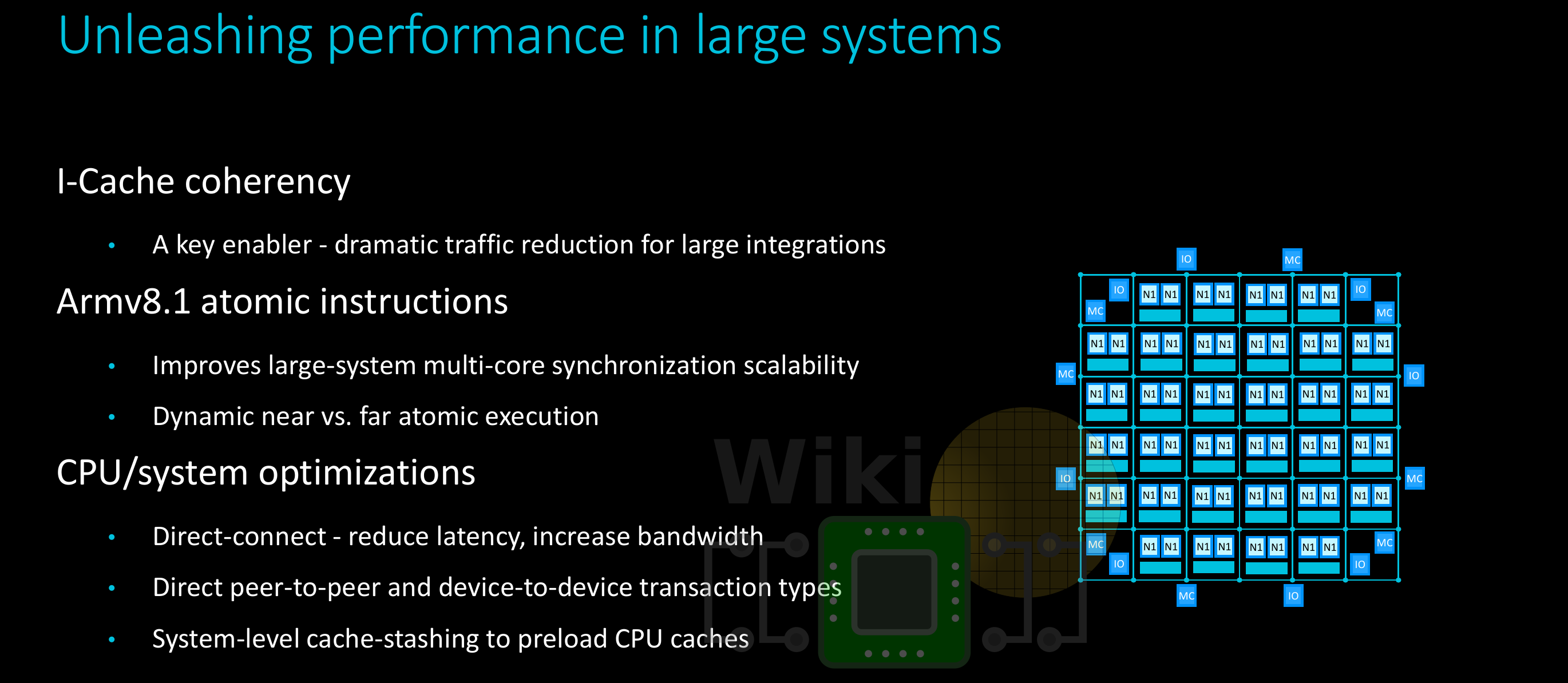
Scaling to as much as 128 cores and more does introduce a number of manufacturing challenges. Arm is touting a couple of ways to deal with this. One such option leveraging CCIX links in order break down a single die into smaller more manufacturable chiplets. A large mesh of cores can then be split up smaller dies, improving yield and scalability. Arm is also pushing the idea of scaling using SmartNIC integrations.
At a high level, the Ares core is almost identical to the Cortex-A76. This isn’t a big surprise given they were both designed by the Arm Austin team. There are, however, a number of subtle differences between the two designs. Ares features an 11-stage integer pipeline with a 4-wide front-end and an 8-wide back-end.
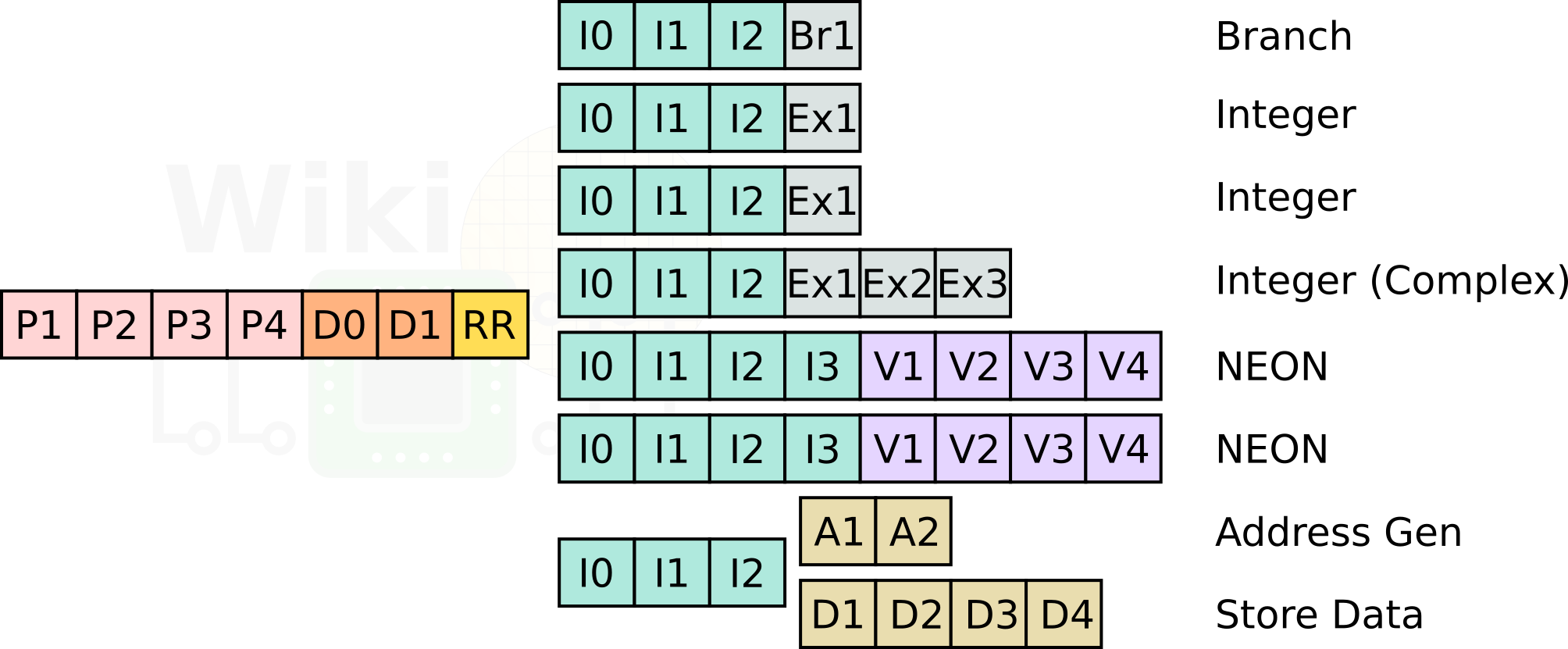
Like the A76, the back end has two simple ALU pipes, a complex ALU pipe, and a dedicated branch pipe. Likewise, there are also two 128-bit wide NEON pipes. One of the more major differences here is in the memory subsystem. The LD/ST pipeline features a decoupled address generation unit and a store data unit.
As far as the memory subsystem goes, Ares is identical to the A76. Like the A76, Ares has a 64 KiB L1I$ and a 64 KiB L1D$. This is the first Arm implementation to feature an instruction cache coherency which is meant to accelerate VM and other virtualized environment setup/teardown time and reduce traffic for large integrations. The private L2 cache is doubled on Ares (either 512 KiB or 1 MiB). The TLBs on Ares are identical to that of the A76 (48 entries ITLB/DTLB and a 1280-entry STLB). Both cores support 68 in-flight loads and 72 in-flight stores.
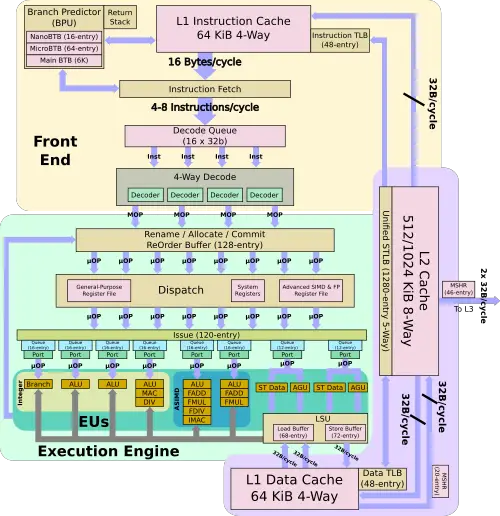
Ares is fully ARMv8.2 compliant. Coupled with the doubling of the vector pipeline bandwidth compared to the Cosmos (A72) platform, Ares introduces significant vector performance improvement over the prior platform. It’s worth noting that along with ARMv8.2 comes the added support for dot product and half-precision floating-point support which can deliver an additional improvement for various machine learning algorithms that take advantage of those instructions.

Designed to take advantage of a leading-edge 7nm fabrication process, Ares uses between 1.2 and 1.4 mm² for the core and the private L2 cache (0.5-1 MiB). The power target is 1.0 to 1.8 W per core + L2, targetting a frequency of 2.6 and 3.1 GHz. It’s worth pointing out that customers aiming for the high end of the frequency range will see a pretty significant increase (>50%) in power for a modest 20% increase in frequency.

Ares features all the bells and whistles RAS features you might expect including SECDED ECC protection for the caches, full-system data poisoning on double-word granularity, and error logging. Additionally, it has support for the Virtualization Host Extensions (VHE) which was introduced in ARMv8.1, enabling running existing hypervisor OS kernels in EL2 through the addition of new EL2 registers and new debug and timer registers.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–