
The x86 Advanced Matrix Extension (AMX) Brings Matrix Operations; To Debut with Sapphire Rapids

Intel recently published the details of the Advanced Matrix Extension (AMX), a new x86 extension designed for operating on matrices with the goal of accelerating machine learning workloads. AMX is the third in a series of AI-specific extensions marketed by Intel under the DL Boost technology brand. The first extension, AVX512_VNNI, was introduced with Cascade Lake. VNNI was designed for speeding up CNNs kernels (specifically 8-bit and 16-bit values) by combining the multiplication and addition of value pairs with the accumulation writeback operation. Cooper Lake followed-up with the next extension – AVX512_BF16. AVX512_BF16 brings a number of instructions for converting single-precision floating-point values to bfloat16 as well as for performing dot-product on bfloat16 pairs and accumulating the result. AMX will be the third DL Boost technology which Intel says will be introduced with 4th-generation Xeon Scalable based on the Sapphire Rapids microarchitecture in 2021.
| Intel DL Boost Technologies | |||
|---|---|---|---|
| Microarchitecture | AVX512_VNNI | AVX512_BF16 | AMX |
| Client | |||
| Ice Lake (Client) | ✓ | ✗ | ✗ |
| Server | |||
| Cascade Lake | ✓ | ✗ | ✗ |
| Cooper Lake | ✓ | ✓ | ✗ |
| Ice Lake (Server) | ✓ | ✗ | ✗ |
| Sapphire Rapids | ✓ | ✓ | ✓ |
Advanced Matrix Extension (AMX)
The Advanced Matrix Extension or AMX is a new x86 extension. From a complexity point of view, it’s quite a bit more involved than the other two DL Boost extensions. Whereas the _VNNI and _BF16 built on top of the AVX512 foundation, AMX is a standalone extension with its own storage and operations. AMX introduces a new matrix register file with eight rank-2 tensor (matrix) registers called “tiles”. It also introduces the concept of accelerators that are capable of operating on those tiles. The extension is implemented in a similar manner to how AVX/2 and AVX512 were added without requiring any special changes to the overall architecture. AMX instructions are synchronous in the instruction stream with memory load/store operations by tiles being coherent with the host’s memory accesses. Like the other extensions, AMX may be interleaved with other x86 code as well as other extensions such as AVX512.
The matrix register file comprises eight tiles (named TMM0…TMM7), each having a maximum size of 16 rows by 64-byte columns for a total size of 1 KiB/register and 8 KiB for the entire register file. Through a tile control register (TILECFG), a programmer is able to configure the size of those tiles (in terms of rows and bytes_per_row). Depending on the algorithm being implemented, the size of the tile can be changed to more naturally represent that algorithm.
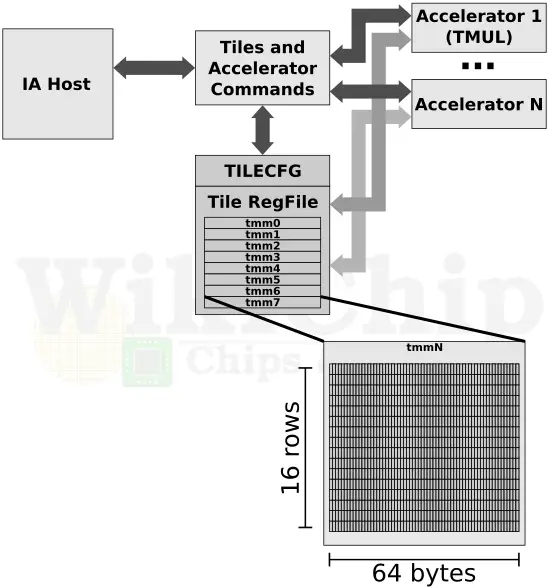
AMX currently consists of just twelve instructions. They can be loosely grouped into three categories: configuration instructions, tile handling (e.g., load, store, zero), and tile operations (i.e, dot product). The basic flow is you’d set up the configuration of how you’re going to operate on the tiles. This is done just once. You’d load up a tile representing a small section from a larger image in memory, operate on that tile, and repeat with the next tile representing the next portion of the image. When done, you’d store back the resultant tile to memory. Algorithms would likely use AVX-512 for post-processing following the matrix multiplication.
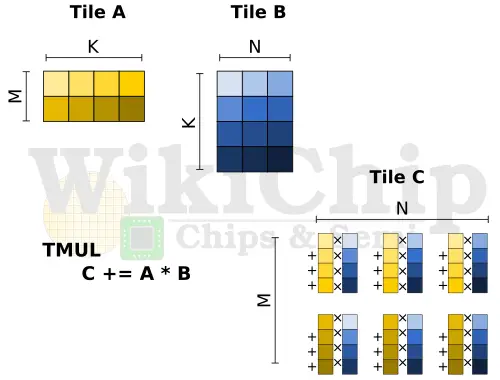
The current specs define just one accelerator – the Tile Matrix Multiply (TMUL) unit comprising a grid of fused multiply-add units capable of operating on tiles. The TMUL unit performs just one operation TileC[M][N] += TileA[M][K] * TileB[K][N] with the size of those matrices being preconfigured in TILECFG by the programmer.
The way AMX is defined is similar to AVX512 with various sub-extensions. There is the base tile architecture and accompanying instructions. Intel calls it AMX-TILE. AMX-TILE encompasses all the necessary instructions for configuring the tile register file (i.e., load/store TILECFG) as well as instructions for handling the tiles (i.e., load/store tile, zero/reset tile). The TMUL unit is actually part of AMX-INT8 and AMX-BF16. There doesn’t seem to be any requirement for the hardware on which is needed to be supported and there it doesn’t preclude the possibility of hardware supporting just the INT8 or just the BF16 sub-extensions. In fact, the current ISA Extensions Reference Manual leaves Sapphire Rapids support ambiguous, saying it supports AMX but doesn’t actually disclose the level of support. The AMX-BF16 sub-extension adds a bfloat16 dot-product tile operation support while the AMX-INT8 sub-extension adds byte dot-product tile operation support. There are four instructions within AMX-INT8 due to its support of all four permutation of signed/unsigned byte operation.
| AMX Extensions | ||
|---|---|---|
| Feature Set | Description | Instructions |
| AMX-TILE | The base matrix tile architecture support. | 7 instructions |
| AMX-INT8 | Dot-product of Int8 tiles. | 4 instructions |
| AMX-BF16 | Dot-product of BF16 tiles. | 1 instruction |
Intel recently reported that the Sapphire Rapids silicon was powered on. More details about the chip and its new features will likely arrive as the company gets closer to launch. Between the recently-launched Cooper Lake Xeon processors and Sapphire Rapids which is planned for next year, late this year Intel is also expected to launch Ice Lake Xeon processors.
The full Advanced Matrix Extension (AMX) specification can be found in chapter 3 of the Intel® Architecture Instruction Set Extensions Programming Reference (June 2020, 319433-040). AMX-related patches for glibc started showing up over the weekend.
Update: Intel confirmed that Sapphire Rapids will, in fact, support everything that was currently disclosed with the AMX specs, including BF16 and Int8. A future revision of the ISA programming reference will clarify this.
| AMX Support | |||
|---|---|---|---|
| Microarchitecture | AMX-TILE | AMX-INT8 | AMX-BF16 |
| Sapphire Rapids | ✓ | ✓ | ✓ |
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–