
Arm Launches Next-Gen Flagship Cortex-X925

Today, Arm is launching its 5th-Generation Cortex-X flagship performance core, formerly known as Blackhawk. The new core – which will be going by the name Cortex-X925 – brings a series of yearly architectural changes that are said to improve both the power efficiency and performance.
This article is part of a series of articles from Arm’s Client Tech Day:
- Arm Unveils 2024 Compute Platform: 3nm, Cortex-X925, Cortex-A725, Immortalis-G925
- Arm Launches Next-Gen Cortex-X925
- Arm Launches Next-Gen Big-Core: Cortex-A725
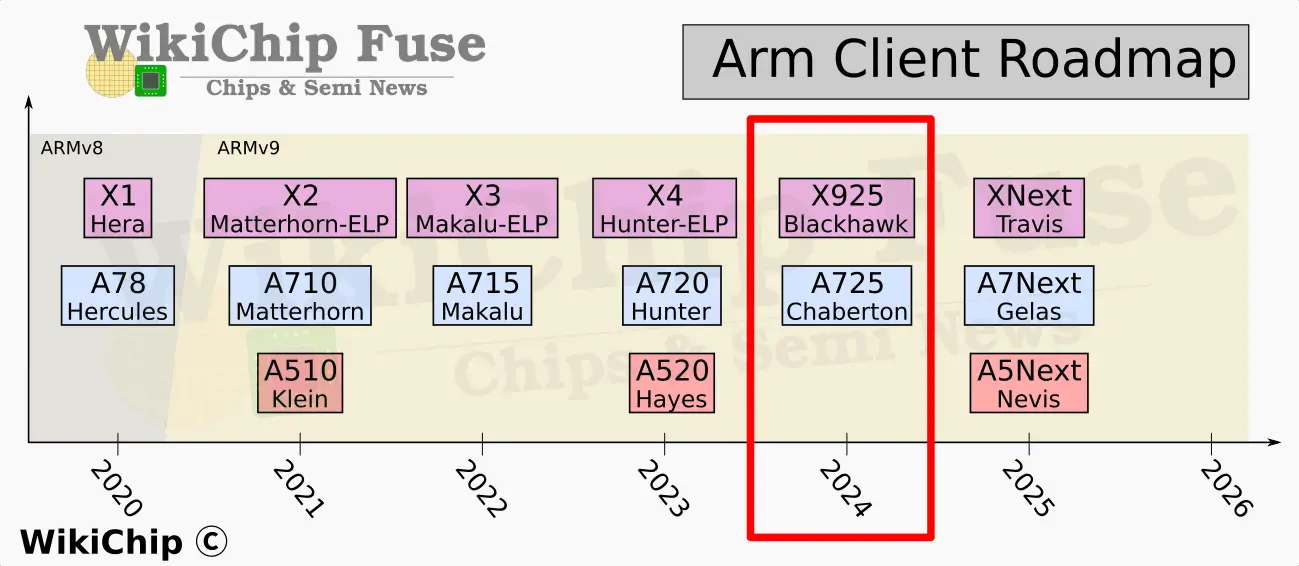
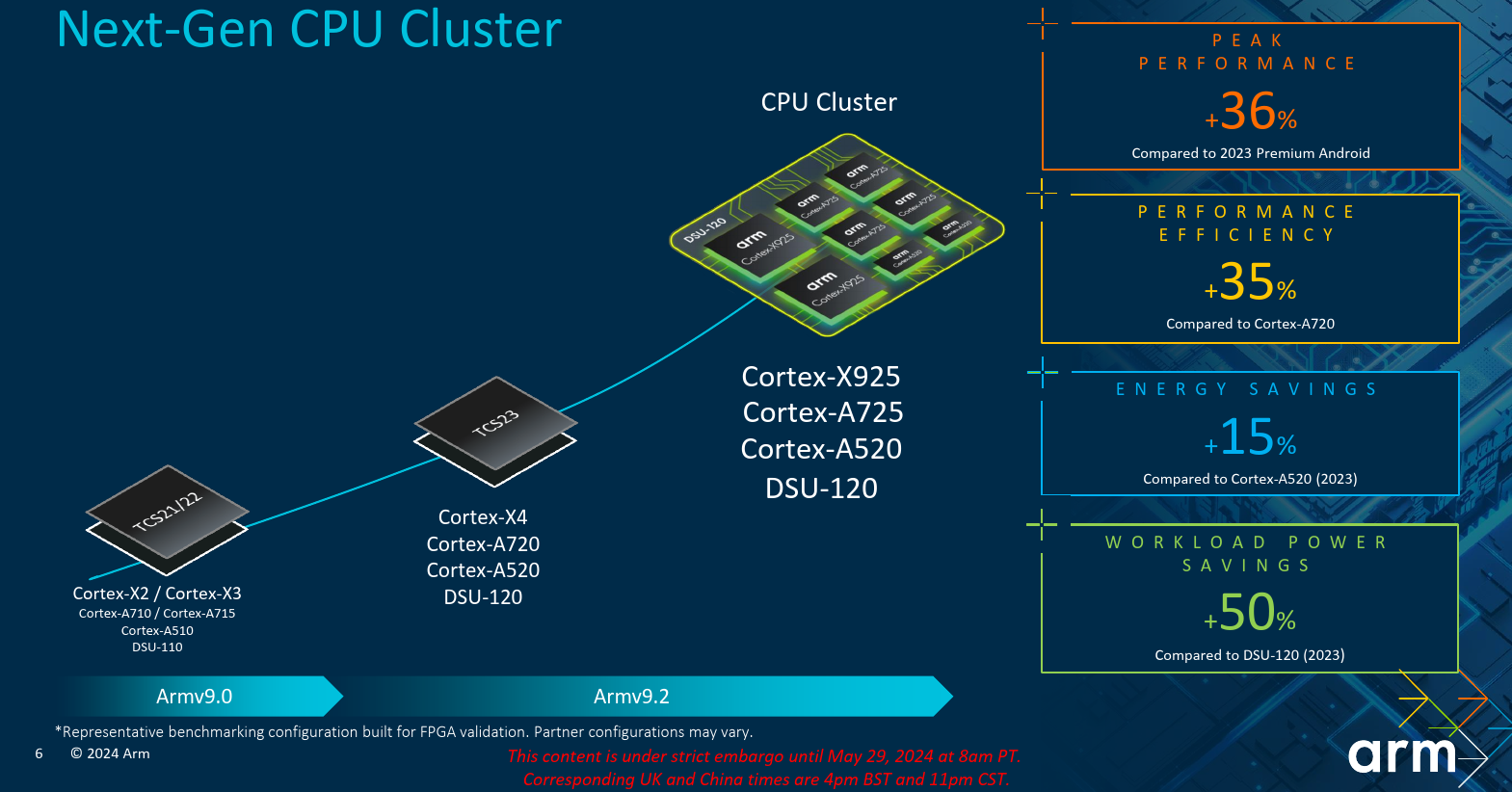
The new Cortex-X925 is part of the 2024 Client Compute Subsystems (2024 CSS) which comprises the DSU-120, the interconnect subsystem, and the Immortalis GPU. The Arm compute power is housed in the DSU-120. This includes the Cortex-A520, and the new Cortex-A725, and the Cortex-X925 itself. All three are second-generation Armv9.2 CPUs. Armv9.1 brought GEMM and BFloat16 support while Armv9.2 brought SME (SVE2) support. The DSU-120 has no restrictions as to the core type/count configuration other than having a maximum instance count of 14 (e.g., up to fourteen Cortex-X925 instances are possible), although realistic device power envelop restrictions will likely put a much lower practical configuration restriction.
The Cortex-X925 along with the rest of the Cortex-X series are a little bit more interesting than the standard big and little Arm cores due to their nonconformity nature. Here Arm allows a more relaxed performance-power-area trade-offs that lean more favorably towards performance over area and power.
Architectural Improvements
On the architectural side, Arm has made a number of fairly significant changes.
Memory Improvement
A large swath of the improvements in the new Cortex-X925 deals with memory (both directly and indirectly). As with prior generations, the Cortex-X925 has a run-ahead branch predictor that goes beyond the the instruction fetch in order to figure our the right instruction stream long before it gets used. On the Cortex-X925, Arm says it has doubled the instruction window size of the branch predictor as well as increased the conditional branch bandwidth. There is also the usual generational improvement in accuracy. At ISO-configuration, at Cortex-X925 is said to deliver lower missed predictions per kilo-instructions (MPKI).

Feeding the core itself was improved significantly. To that end, the Cortex-X925 doubled both the L1 I$ and D$ available bandwidths versus the prior generation. Arm says this is specifically refers to additional banking of the caches which, in theory, allow for higher effective bandwidth delivery. This increase goes in tandem with the increase in the number of vector pipelines in the backend which is discussed later on. It is also worth pointing out that the X925 now offers up to 3 MiB of private L2 cache capacity or 1.5x higher capacity than the prior generation.
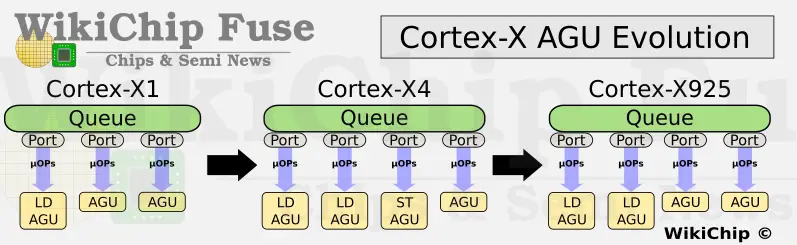
On the execution side, Arm added another load execution unit for a total of four.
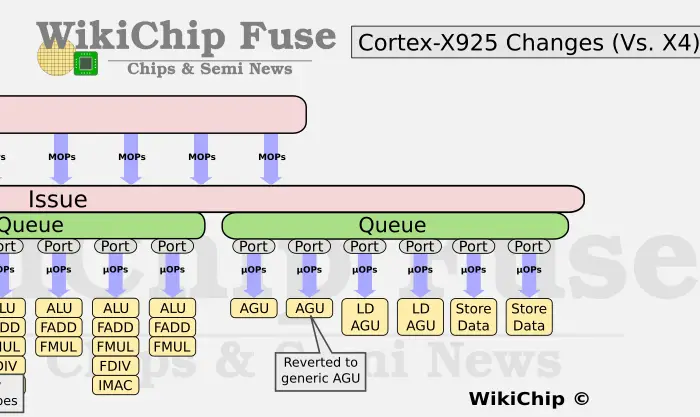
This is an interesting one because over the last few generations the memory subsystem underwent several re-balancing attempts with the number of general AGUs being reduced in favor of load AGUs. We now see this being reshuffled back to some earlier configuration. It’s a bit of a reminder that balancing complex pipelines for all existing workloads is a very hard job. In total, the new Cortex-X925 now supports up to 64B/cycle (at 4x16B rate). Beyond that, Arm says the Cortex-X925 has additional architectural enhancements to the LSU such as some improvements to the store-to-load forwarding.
Back-End
The Cortex-X925 out-of-order window is massive – double the prior generation. In other words, the Cortex-X925 has a bookkeeping capacity of 768 instructions in-flight (or 1,536 fused ops). Arm says that although the core pipeline width is largely the same, the X925 will exhibit higher effective usage due to the elimination of various constraints found in prior generation. In other words, although the theoretical peak instruction stream throughput is the same as the X4, the effective peak instruction stream on the new X925 is said to be higher due to the pipeline architectural changes.
| Reorder Buffer | |||||
|---|---|---|---|---|---|
| uArch | Cortex-X1 | Cortex-X2 | Cortex-X3 | Cortex-X4 | Cortex-X925 |
| Dispatch | 8/cycle | 8/cycle | 8/cycle | 10/cycle | 10/cycle |
| Max In-flight | 224 | 288 | 320 | 384 | 768 |
Directly targeting AI and vector applications, the X925 added two new advanced SIMD pipes for a total of six 128b pipes. Additionally, the integer ALU pipes are now capable of more complex two-cycle operations.

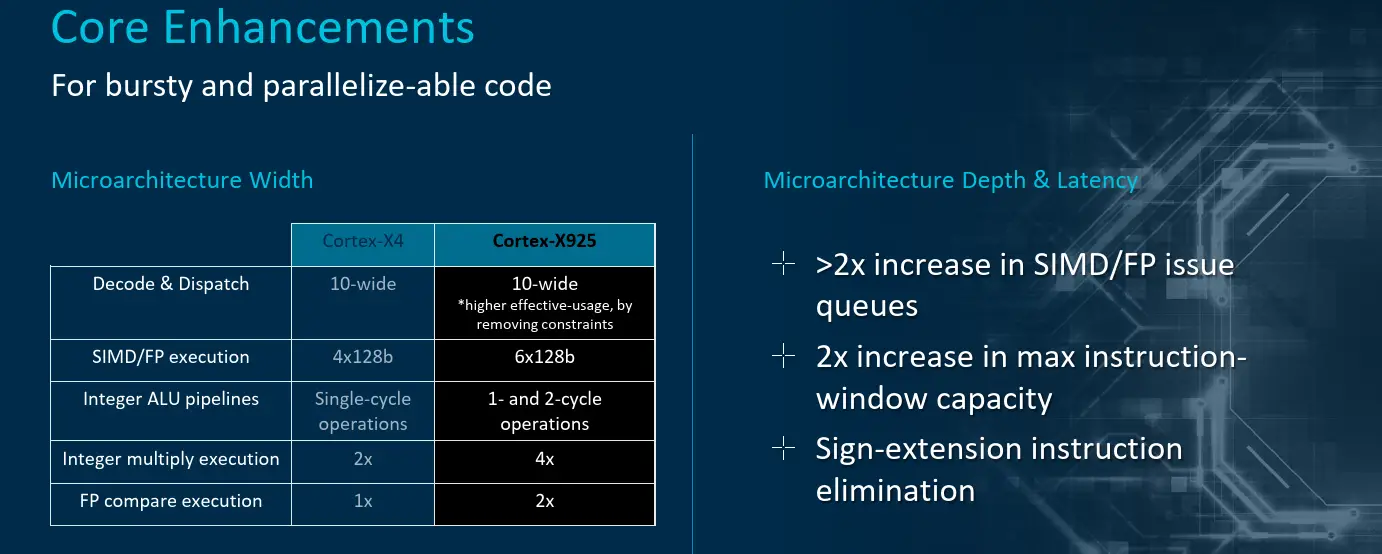
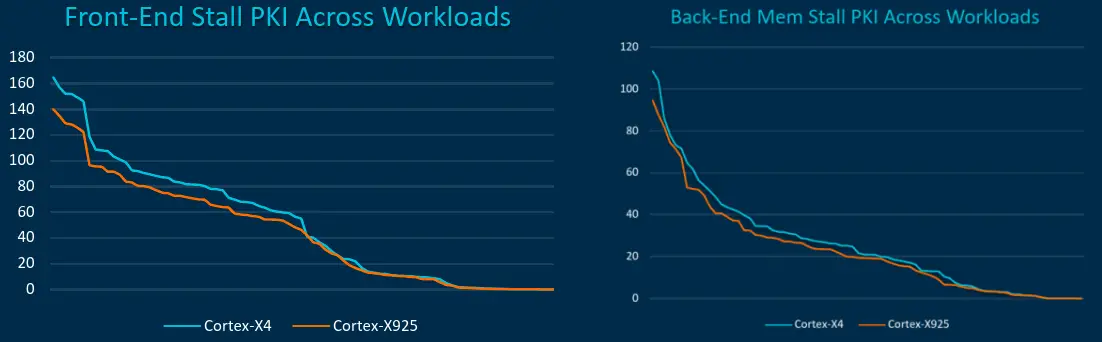
Overall, much of the back-end buffers were said to have grown between 25% and 40% across the board. All in all, Arm says that both front-end fetch stalls per kilo-instruction as well as back-end memory stalls have been improved across a variety of applications.
Performance
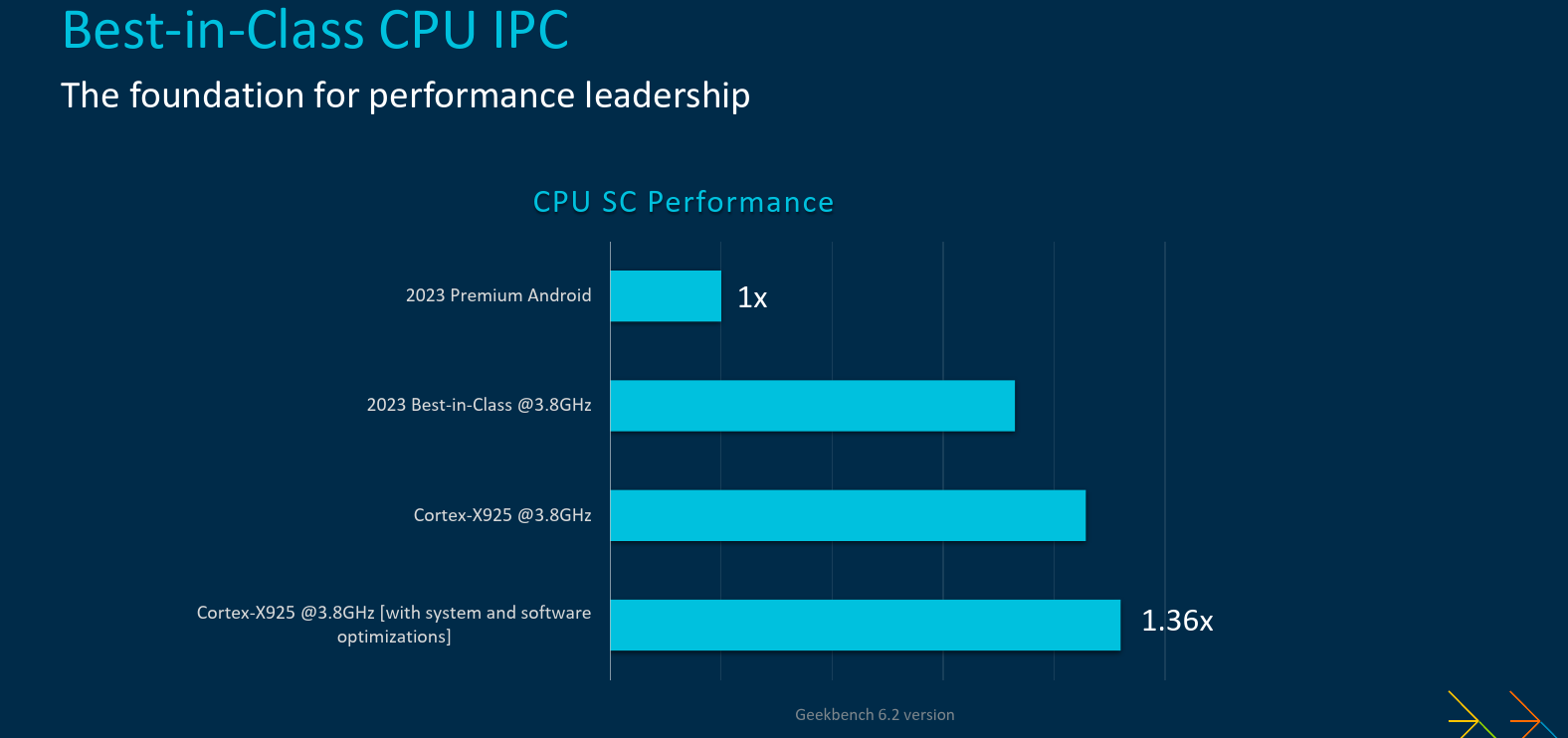
Putting it all together, Arm is touting some big improvements. The company says the new Cortex-X925 brings the highest performance uplift in the history of the Cortex-X series. One of the graphs Arm presented regarding IPC is shown below. Although the chart is unnecessarily cumbersome and confusing, the numbers are actually pretty solid. Compared to a standard Premium class 2023 Android device, a best-in-class core clocked at 3.8 GHz yields around 3.6x performance improvement. At ISO-frequency, the new Cortex-X925 is said to deliver around 17% higher IPC. With a fully optimized system and software stack and under best case scenario, this number appears to increase to around 25%.
Across a number of mobile industry benchmarks such as Speedometer2 and Geekbench 6, at ISO-frequency and ISO-memory, Arm is claiming the new Cortex-X925 will deliver around the 15% IPC improvement compared to the previous Cortex-X4. Thanks to the various architectural improvements including the additional vector execution units, AI speed improvements are considerably higher.
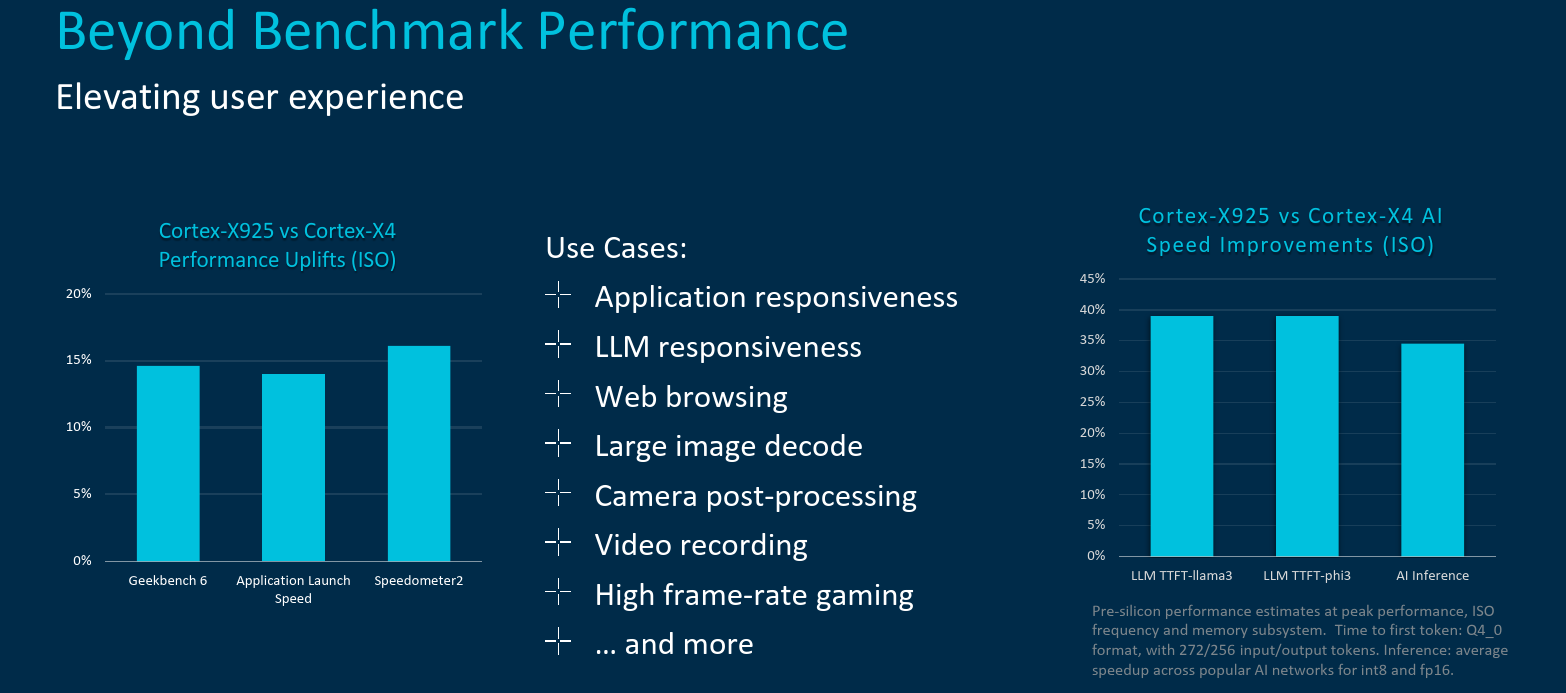
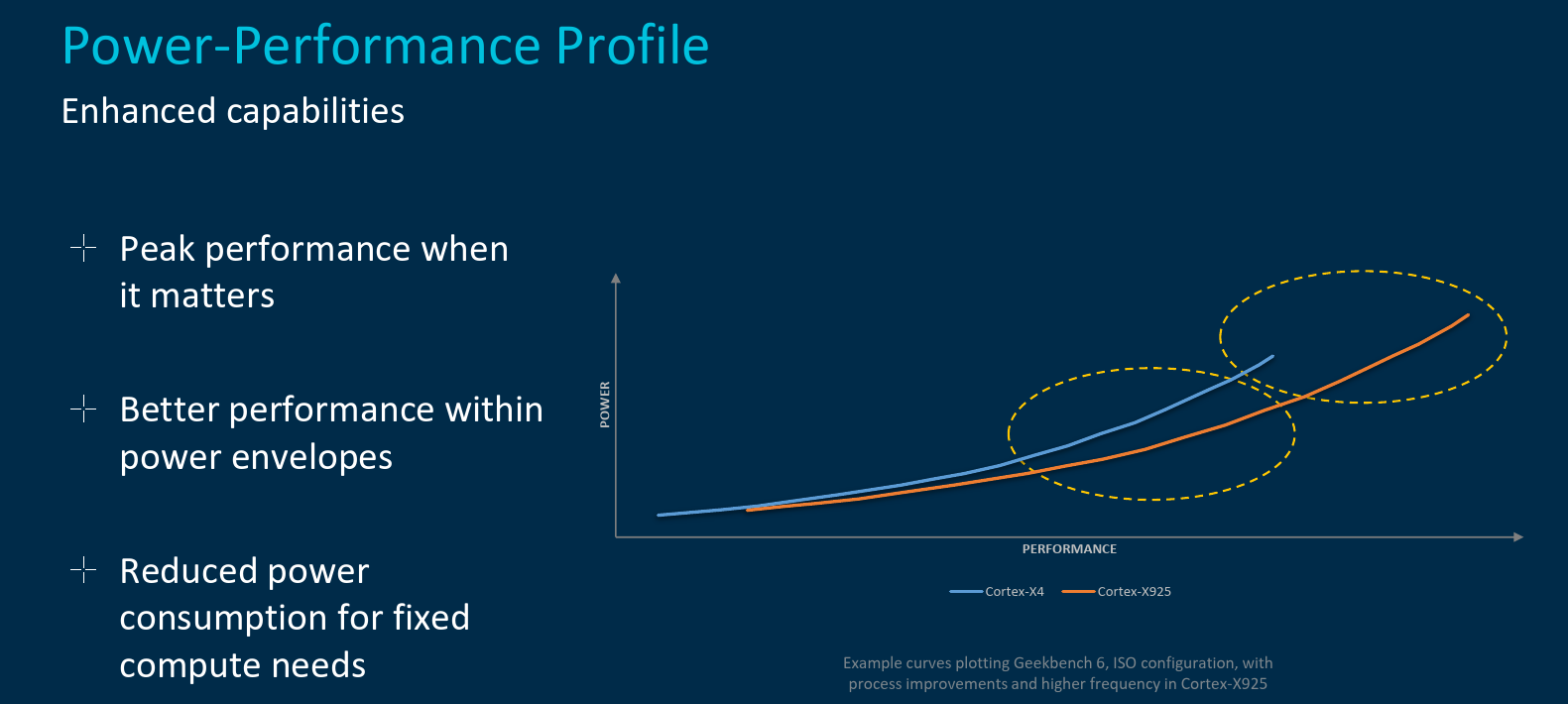
Because the Cortex-X925 targets the 3-nanometers process node and has been optimized for that node, Arm claims that at ISO-performance, the new Cortex-X925 operates at much higher efficiency (i.e., lower power). Or alternatively, at similar or slightly higher power, the new Cortex-X925 (thanks in part to higher frequency) the new core can deliver significantly higher performance.
The new Arm Cortex-X925 is expected to find its way to leading premium mobile products by the end of this year.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–