
Arm Unveils 2024 Compute Platform: 3nm, Cortex-X925, Cortex-A725, Immortalis-G925
Every year, around the May or June timeframe, Arm unveils its new platform of mobile compute as part of its yearly cadence. Today, Arm is unveiling its 2024 Client Compute Subsystem (2024 CSS), a comprehensive set of IPs covering general and graphics compute as well as the means of combining them together into a complete system.
This article is part of a series of articles from Arm’s Client Tech Day:
- Arm Unveils 2024 Compute Platform: 3nm, Cortex-X925, Cortex-A725, Immortalis-G925
- Arm Launches Next-Gen Cortex-X925
- Arm Launches Next-Gen Big-Core: Cortex-A725
2024 Compute Platform
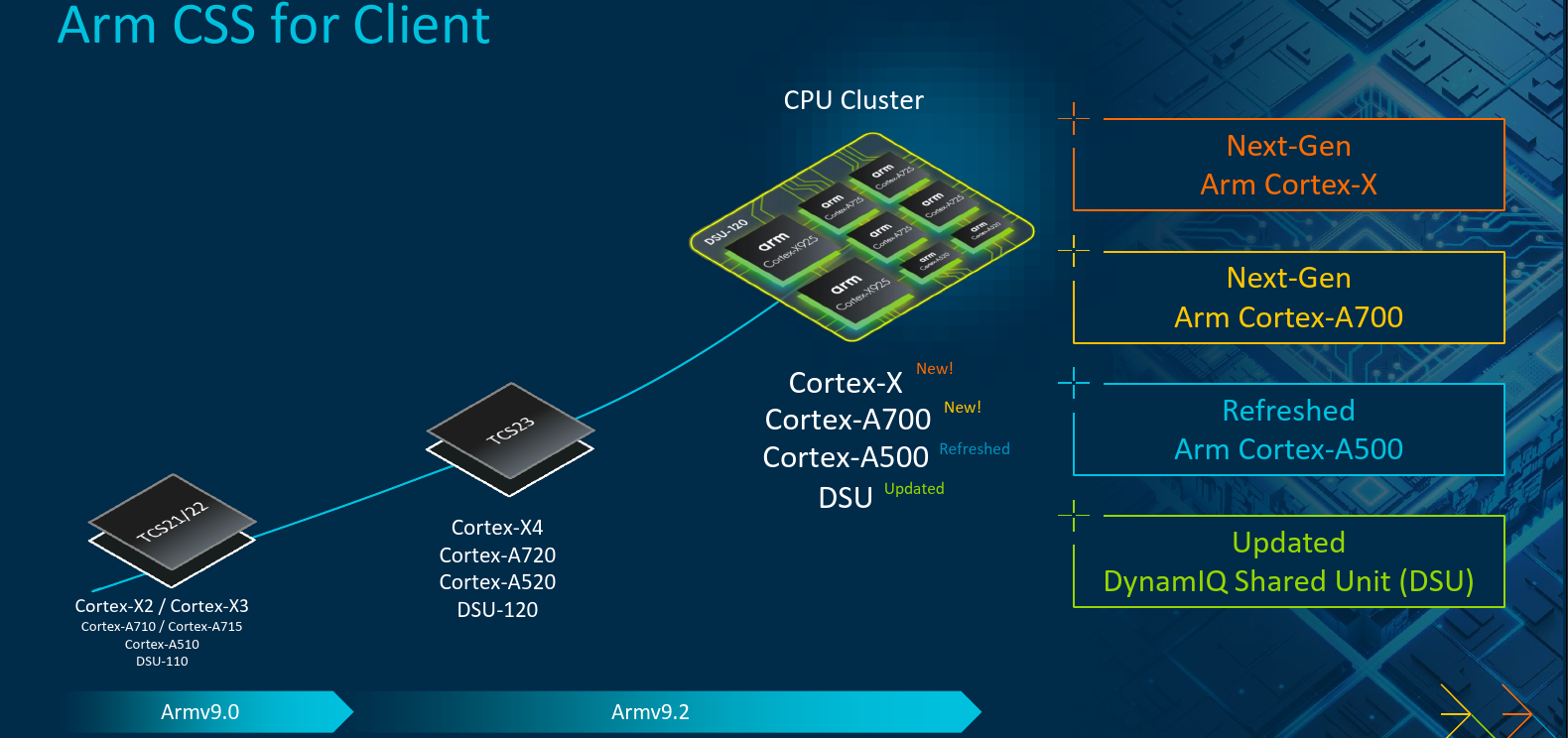
Today’s launch includes the complete client compute platform, the 2024 Client Compute Subsystem (2024 CSS). This includes the previously-launched DynamIQ Shared Unit 120 (DSU-120) which provides the shared L3 cache as well as the necessary infrastructure for interconnecting multiple instances of Arm’s Cortex CPU IPs. Along with the DSU, the company is introducing a new flagship CPU core – the Cortex-X925, a new high-performance big core, the Cortex-A725, and a refreshed version of the Cortex-A520. All three cores are second-generation Armv9.2-compliant cores which include SME (SVE2) support, offering higher vector performance, which among other applications enhances AI-related workloads that are able to utilize these instructions. While the Cortex-A725 targets balanced high-performance with higher power-efficiency for longer battery life, the new Cortex-X925 targets highest single-thread performance.
With the DSU-120, system integrators are able to instantiate up to 14 cores of any flavor in a single unit. There are no restrictions of constraints as to how many or what types of cores can be configured other than the overall device and package power and thermal limits. Additionally, the new CSS is introducing 5th-generation Arm GPUs, including the new flagship Immortalis-G925.
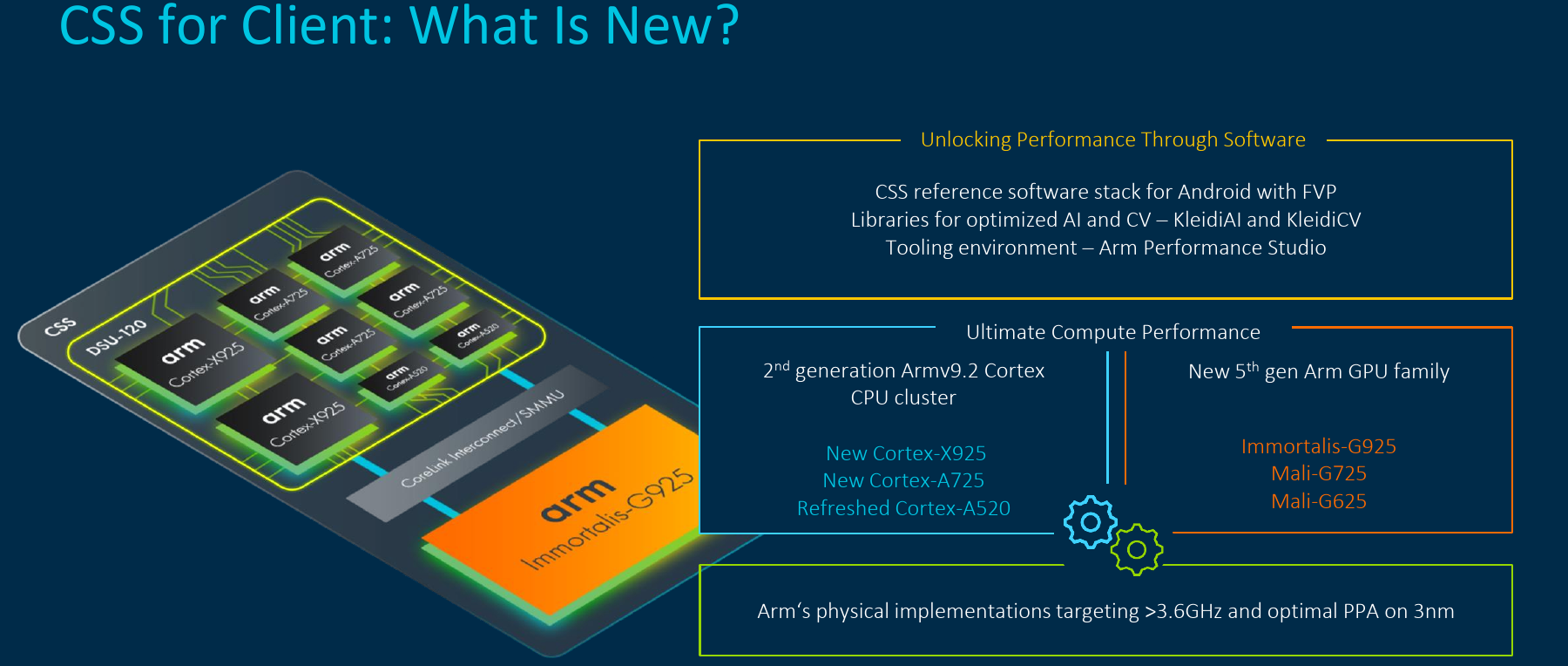
The new compute subsystem has the reference design shown below which is important as its used for their bench-marking results later on. Here Arm opted to replace one of the high-performance A7x cores with the company’s highest-performance Cortex-X core, doubling its highest-core performance. Additionally, the new reference platform utilizes a 16 MiB shared LLC, double the prior generation. Perhaps one of the biggest differences is the utilization of TSMC’s newest 3-nanometer process node which has a significant impact on power and performance.

One of the major areas that Arm has been placing a lot of effort on is the speed-up of integration and reducing costs. The new 2024 CSS addresses this at its core. Arm has been offering POP IP designs for a long time now. Those are complete silicon implementations that have been designed by Arm and have been highly-optimized for a specific process. Those IPs reduce overhead engineering costs by offering robust IPs that have been tested and certified to overcome most process implementation challenges. In doing so, they also significantly accelerate the time-to-market. With the new CSS platform, Arm is essentially taking their proven POP IP and extending it to the entire system – offering a complete system.

With this year’s launch, there is a large emphasis on TSMC’s 3-nanometer process. The last few platforms took advantage of the 4-nanometer node which offered a significantly smaller process improvement jump when compared to the company’s new 3-nanometers. This year, Arm is going all in on 3-nanometers with the entire CSS platform stack from the CPUs to the GPUs, and all related IPs optimized specifically for the 3-nanometer process. Arms says there are already successful partner physical silicon implementations.

By combining the latest 2024 Arm IPs, along with the new optimized process-specific implementations, caches, and other IPs. Arm is touting CPU implementations capable of exceeding 3.8 GHz in frequency.

Performance
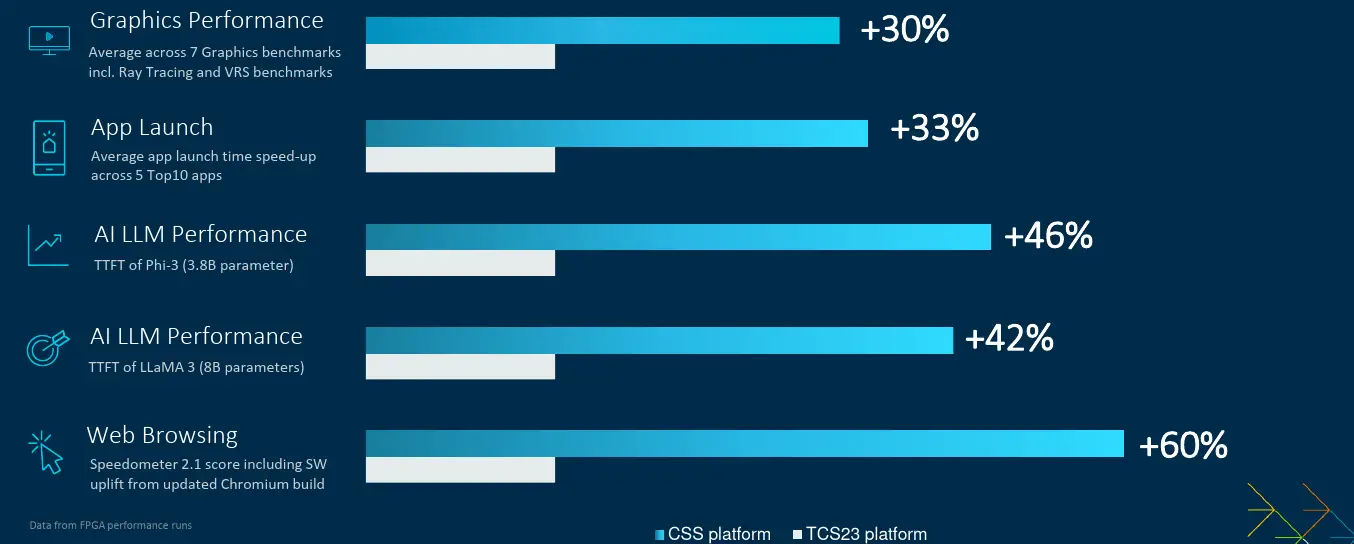
Across a wide range of AI workloads (Arm says 17 popular AI networks for int8 and fp16), Arm claims that the new Cortex-X925 delivers up to nearly 60% faster AI inference performance on a thermally-unconstrained benchmark. With the reference design for this year containing two X925 instances, Arm says the results are up to 170% higher performance. Likewise, the the new Immortalis-G925 which offers 2 additional cores when compared to last year’s TCS23 Immortalis-G720 reference, Arm says the G925 offers up to 36% higher performance.

On more general workloads which compares this year’s 2024 CSS for Client targeting 3-nanometers at 3.6GHz vs last year’s TCS23 at 3.3GHz reference. Both references utilize unthrottled FPGA implementations. Here Arm is claiming up to as much as 40-60% higher performance in general application responsiveness and general performance.
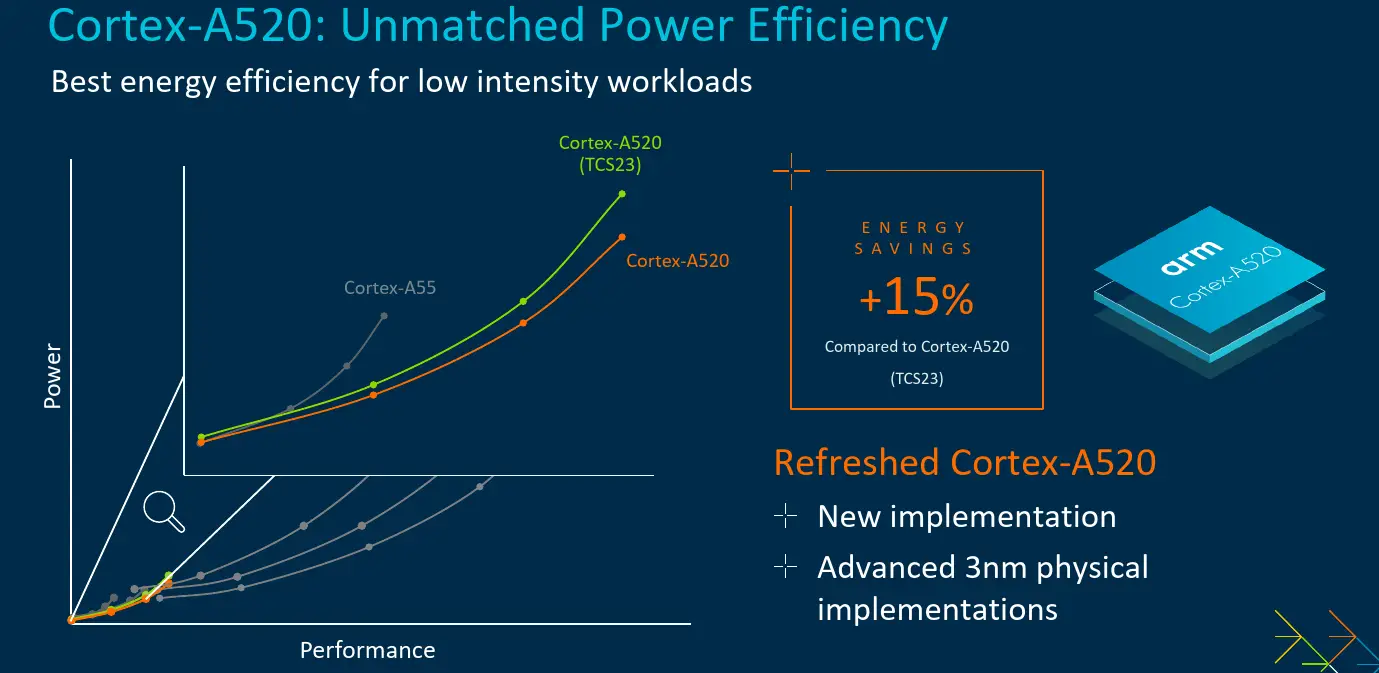
Refreshed Cortex-A520
As part of the new 2024 CSS platform, Arm is introducing a refreshed Cortex-A520. While the overall architecture has not seen significant changes, the implementation itself has. Here the new core has been specifically optimized to take advantage of the new 3-nanometers process power and area improvements. To that end, Arm says the Cortex-A520 with a 3-nanometer optimized implementation delivers 15% higher power-efficiency versus the Cortex-A520 on a 4-nanometers node at ISO-configuration.
DSU-120 Improvements
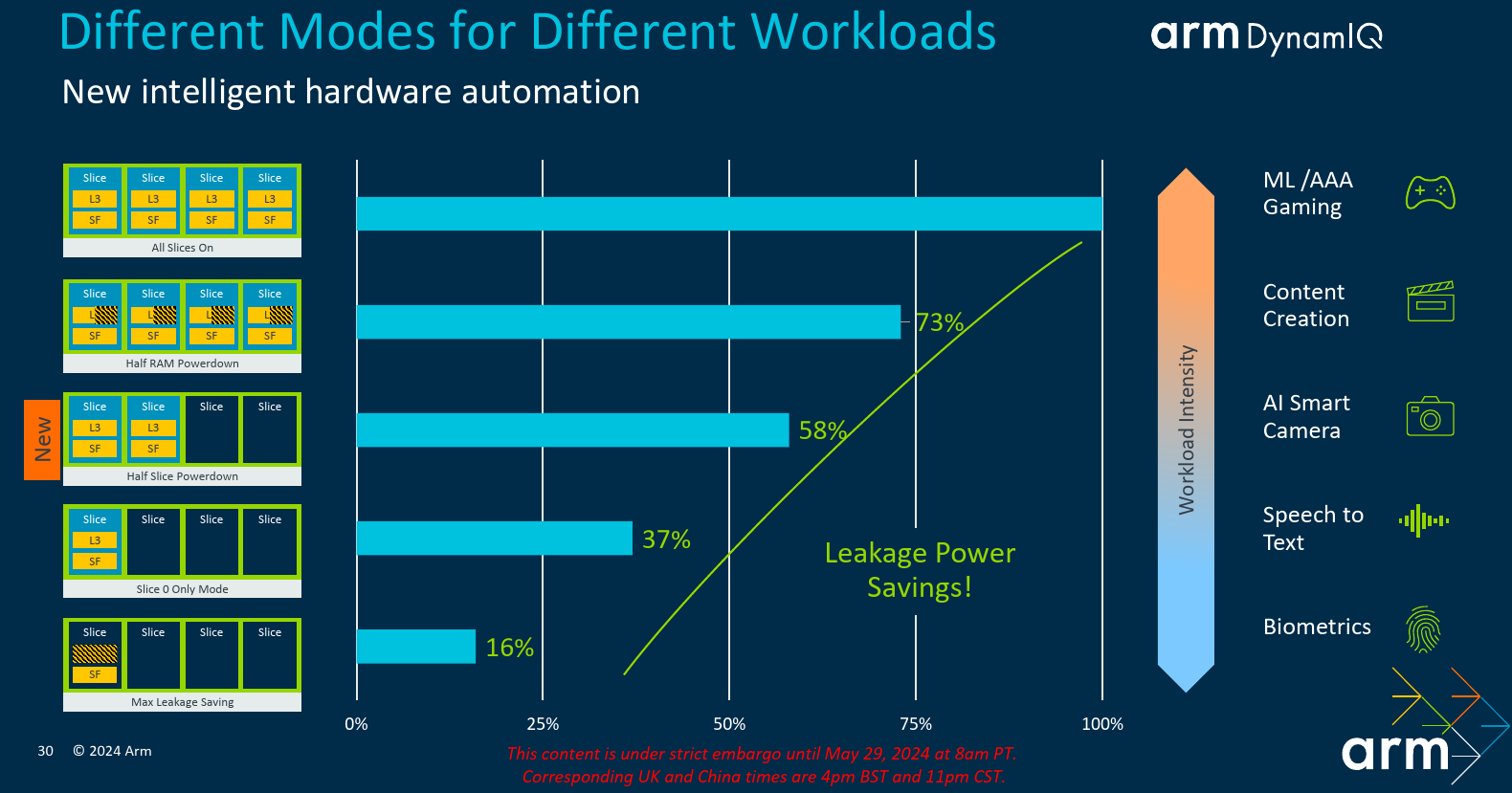
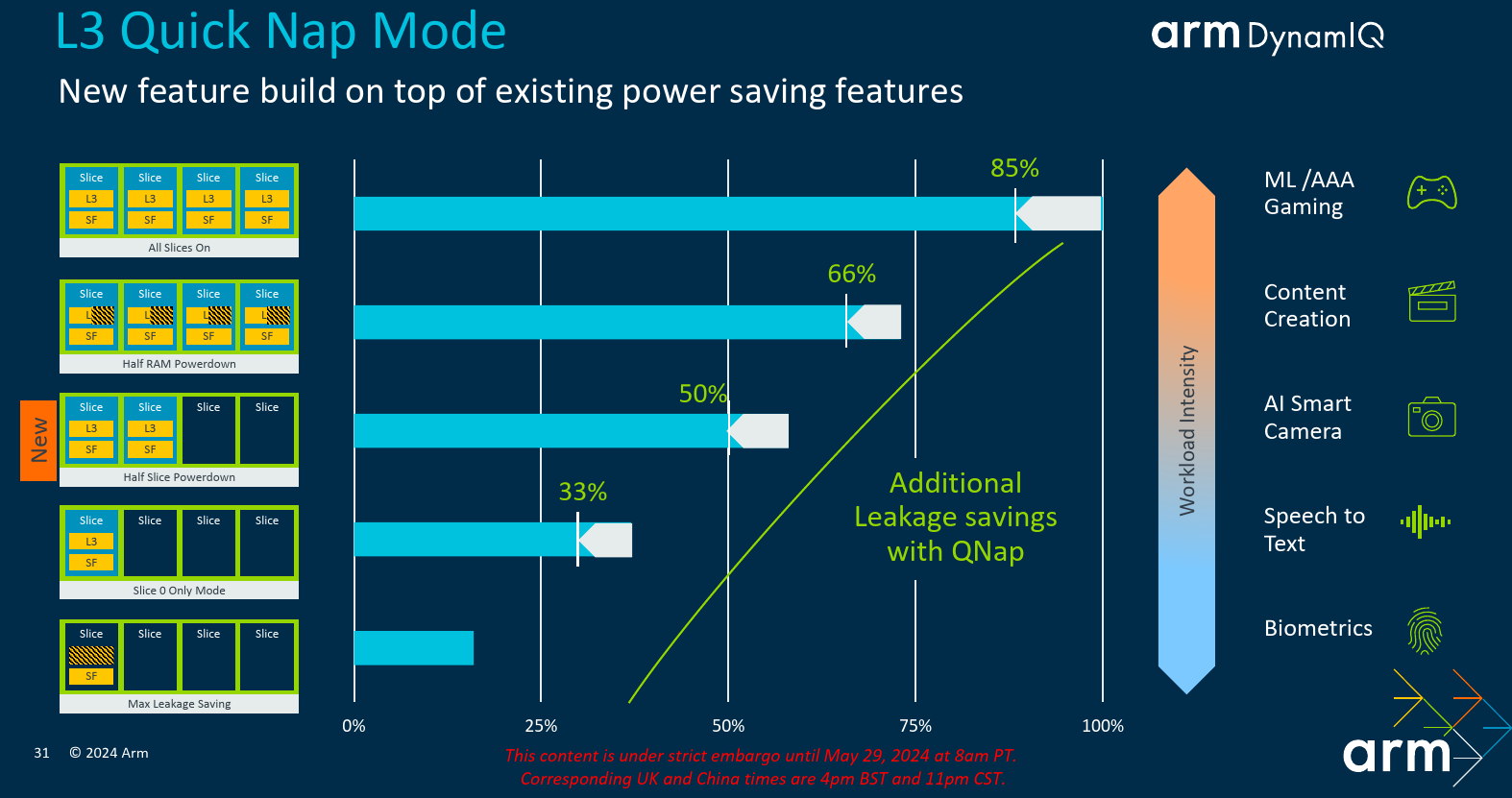
Although the DSU-120 was introduced last year, this year a set of new features and power optimizations mode were introduced. Taking advantage of the new 3-nanometer process, along with various architectural improvements, Arm says it has reduced the DSU-120 area at both iso-process and iso-confg (5nm vs 3nm). Additionally, a number of new dynamic power management features were added to improve efficiency.

One of the new DSU features introduces is the ability to very quickly turn on and off caches slices as the workload demands. In aggressive performance workloads, everything is turned on. With lesser demanding applications, leakage power can be reduced by shutting down some of those cache slices. What’s being introduced with the new DSU-120 is the ability to very quickly (without causing stalls) power down some or even all the cache slices depending on the workload in order to maximize the reduction in powerleakage.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–