
Intel Rolls Out Next-Gen Data Center Portfolio; 100 Gigabit Ethernet, Optane DC, Hewitt Lake, and Cascade Lake With Up to 56 Cores
Cascade Lake
At a high level, Cascade Lake is very similar to Skylake. The maximum number of cores on a die is 28. Each die incorporates 30 tiles, two of which are used or the integrated memory controller.

Side-Channel Mitigation
One of the major changes to Cascade Lake is addressing the various security vulnerabilities. Cascade Lake brings hardware mitigations against Variant 2, 3, 3a, 4, and L1TF.
| Cascade Lake Side-Channel Mitigation | ||
|---|---|---|
| Variant | Side-Channel Method | Mitigation |
| Variant 1 | Bounds Check Bypass | OS/VMM |
| Variant 2 | Branch Target Injection | Hardware Branch Prediction Hardening + OS/VMM Support (Enhanced IBRS) |
| Variant 3 | Rogue Data Cache Load | Hardware Hardening for Memory Faulting |
| Variant 3a | Rogue System Register Read | Hardware |
| Variant 4 | Speculative Store Bypass | Hardware + OS/VMM or runtime |
| L1TF | L1 Terminal Fault | Variant 3 Hardware Hardening |
One of the points that Intel tried to emphasize is that as they continue to research side-channel vulnerabilities, they harden the hardware further which helps mitigate other potential attacks. One of those examples is L1TF. As they migrated variant 3 and hardened memory faulting, L1TF was naturally fixed.
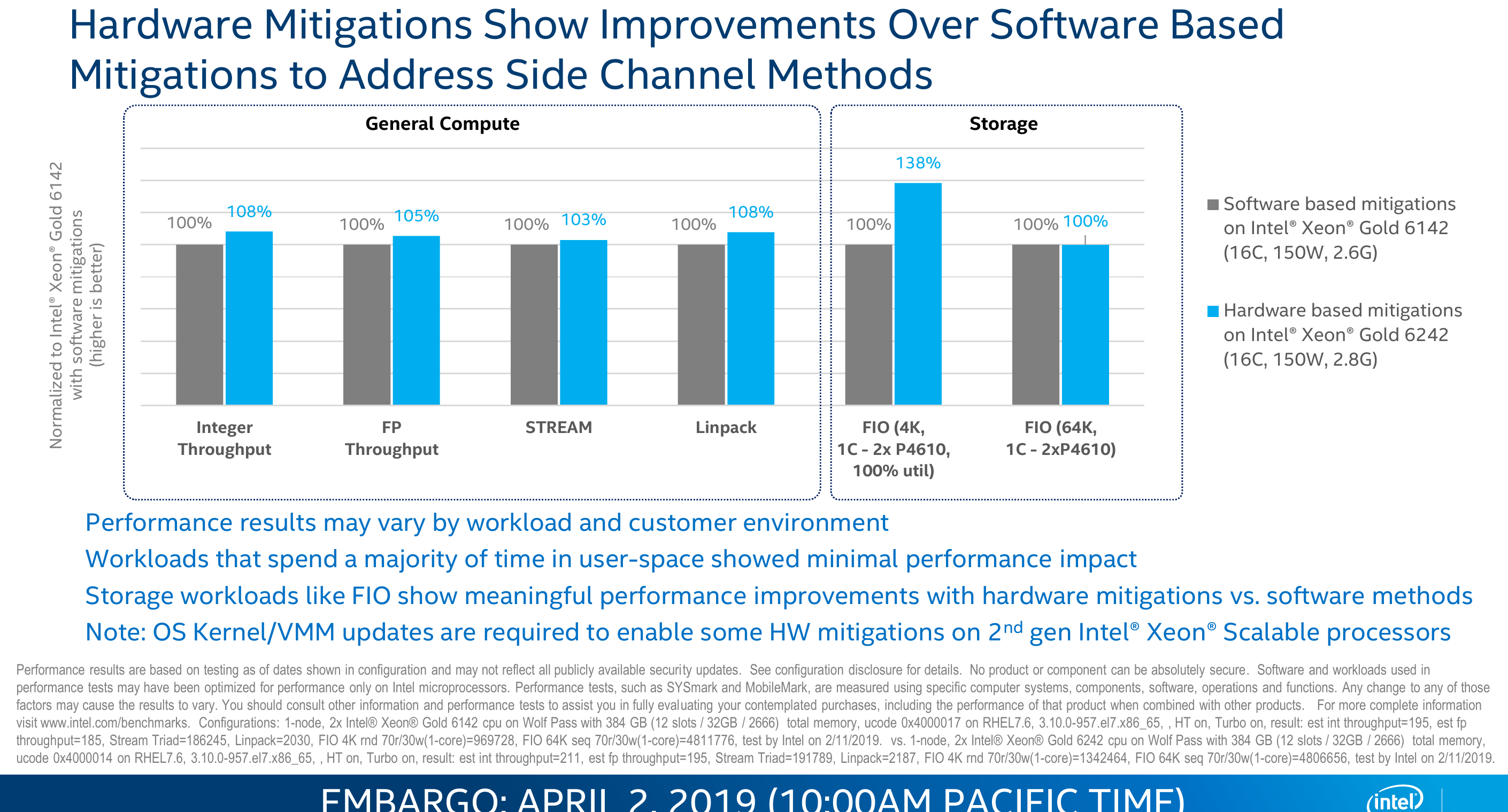
Compared to software-based mitigations, Intel is claiming that the hardware mitigations in Cascade Lake deliver a modest performance improvement as well.
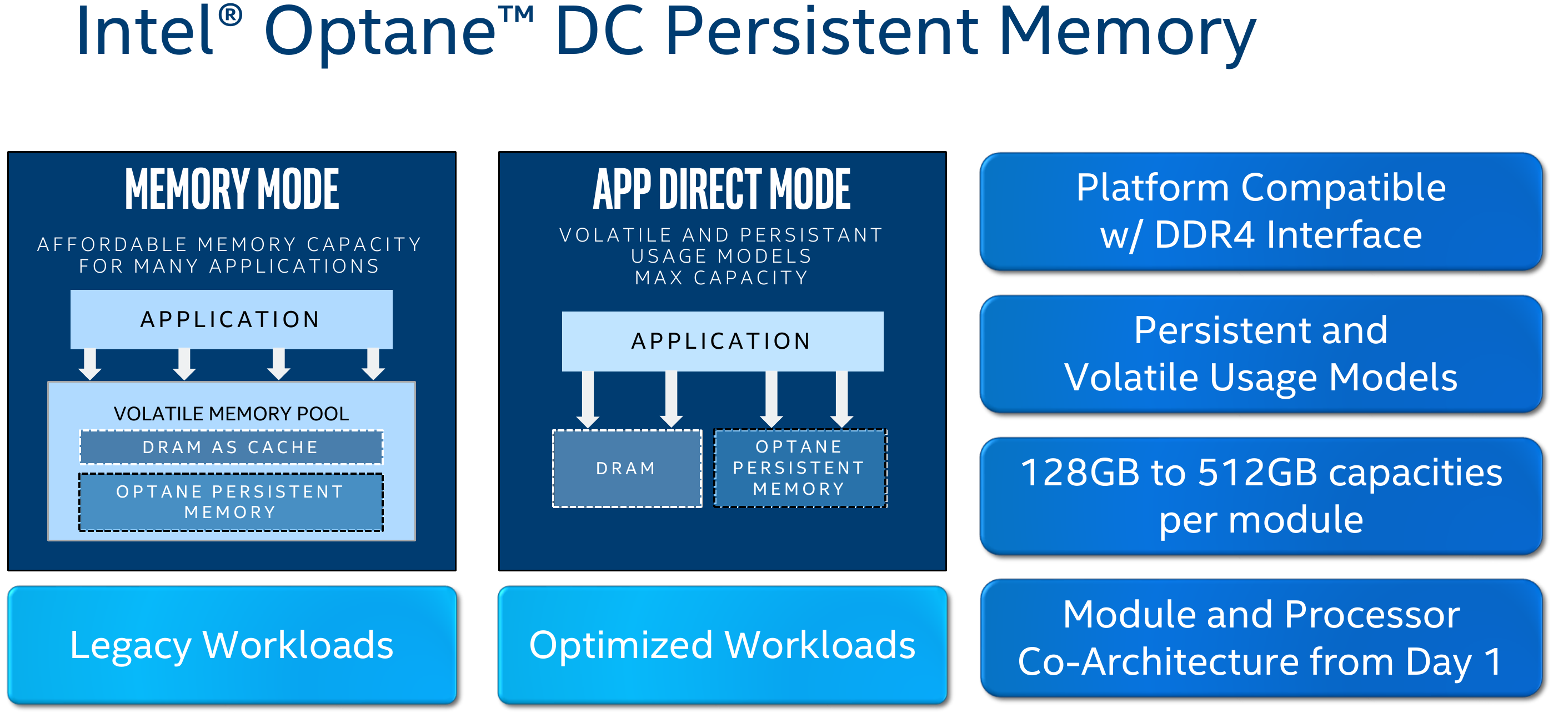
Higher Memory and Optane DC Persistent Memory
Compared to Skylake, Cascade Lake increases the DDR4 data rate supported to 2933 MT/s. This brings the peak theoretical bandwidth up from 128 GB/s to 140.8 GB/s, a 10% improvement. Cascade Lake also introduces support for Optane DC Persistent Memory with capacities from 128 GiB to 512 GiB per module. We have covered the concept of a persistent domain in detail here.
Deep Learning Boost (DL Boost)
With Cascade Lake, Intel is introducing a new AVX-512 extension called Vector Neural Network Instructions (AVX512VNNI) which also goes by the marketing name DL Boost. It’s worth noting that in Cooper Lake, DL Boost is extended to also support the brain floating point format.
VNNI introduces two new instructions.
- VPDPBUSD[S] – Multiply bytes (8-bit), add horizontal pair of neighbors
- VPDPWSSD[S] – Multiply words (16-bit), add horizontal pair of neighbors
Both instructions are designed to improve the performance of inner convolutional loops by fusing what is currently two or three individual AVX-512 instructions. Currently, multiplying two pairs of 16-bit values and accumulating the result to 32-bits value requires 2 instructions. This is done by performing an VPMADDWD operation on a set of 16-bit values followed by a VPADD to add the 32-bit result to an accumulate.
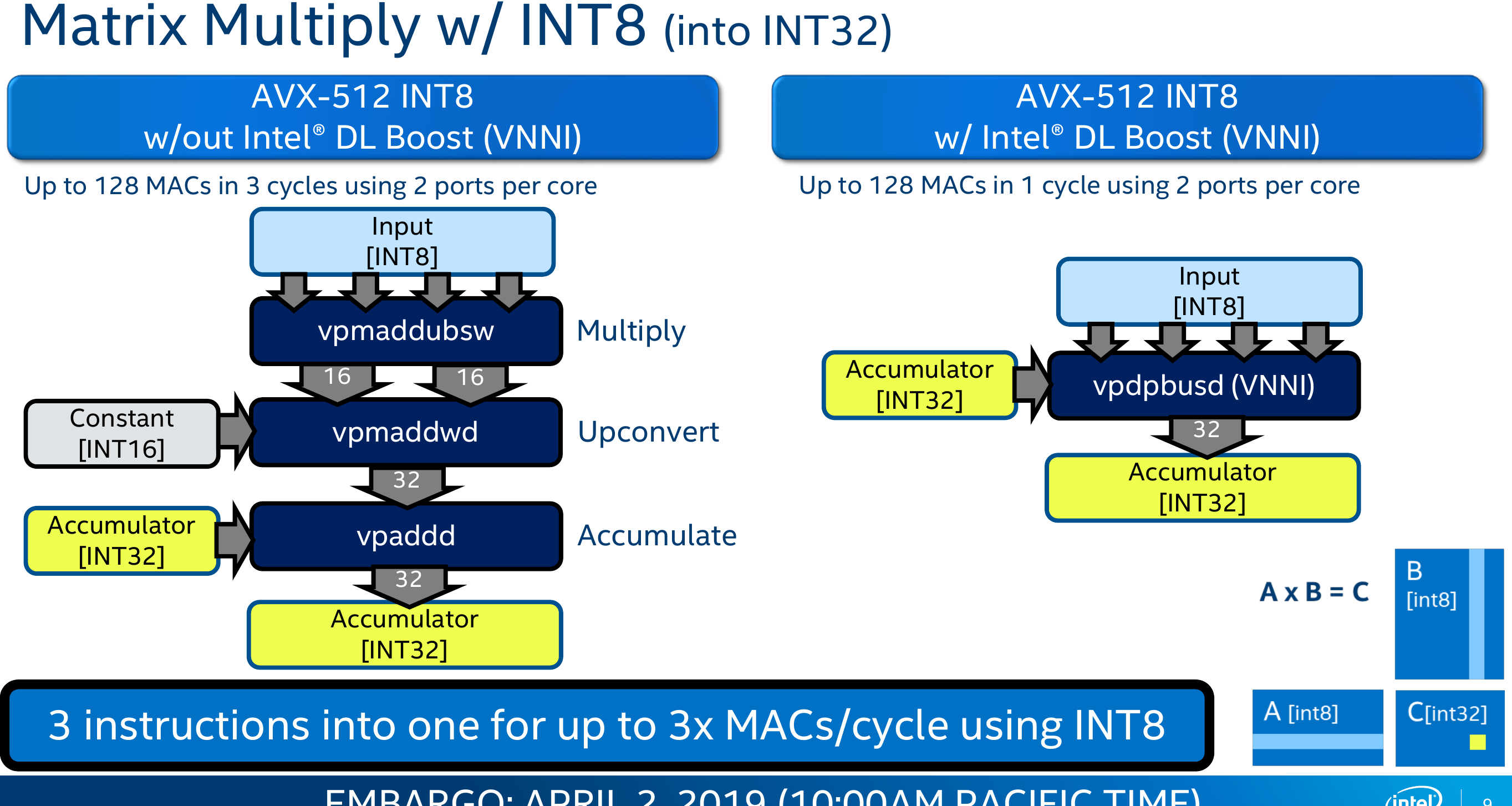
The new extension provides up to 8x the peak MACs per cycle, however in real-world applications, even double the throughput is a considerable win in performance.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–