
A Look At The AMD Zen 2 Core
Back End
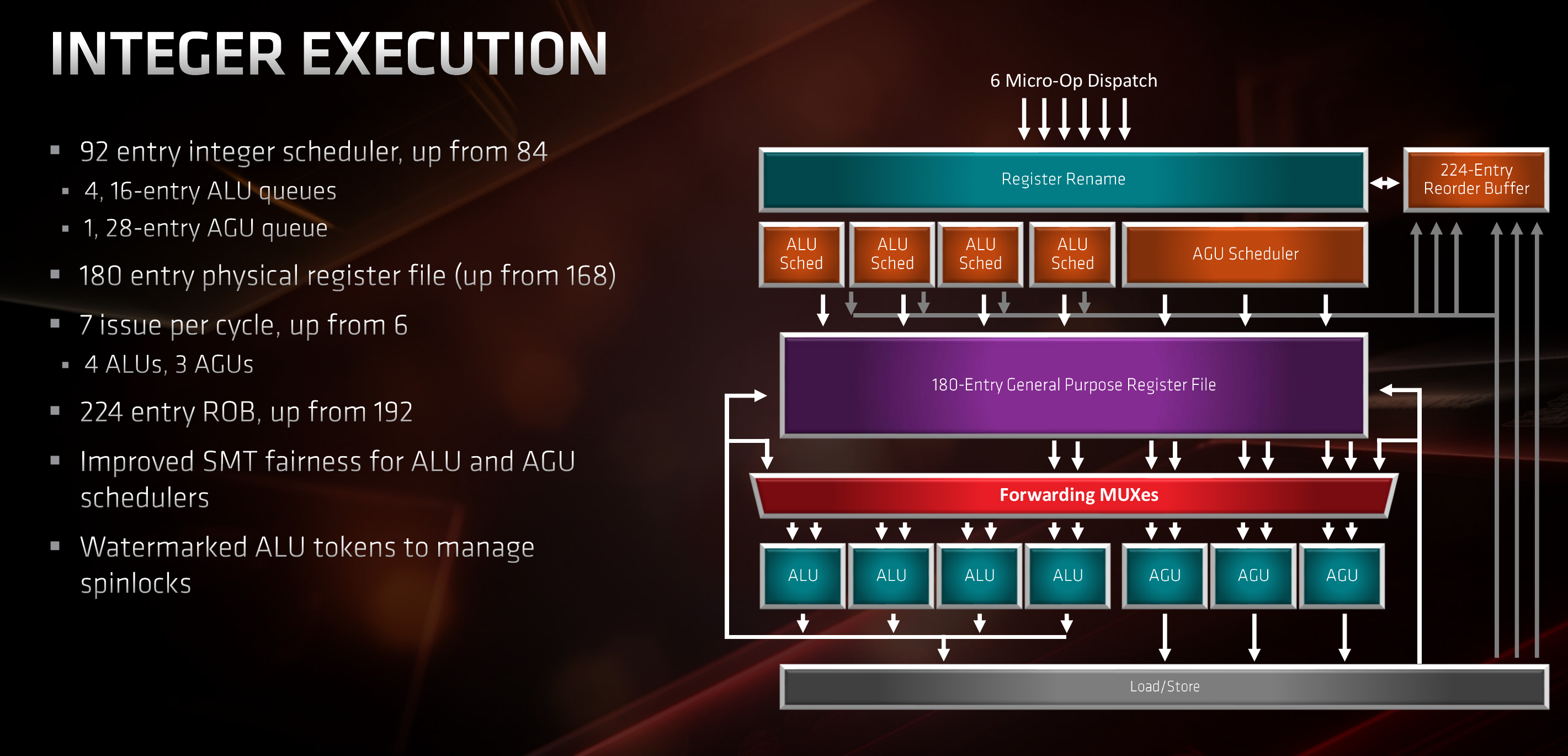
From the dispatch, macro-operations are sent to either the integer cluster or the floating point unit. The retire control unit (RCU; also known as a ROB in other designs) is responsible for tracking all outstanding operations. In both Zen and Zen 2, the RCU operates on complete macro-operations and is capable of renaming up to 6 MOPs per cycle and retiring up to 8 MOPs per cycle. The reorder buffer on Zen is capable of tracking 192 macro-operations in-flight. This has been increased by roughly 15% to 224 on Zen 2. This is the same size as reorder buffer on Skylake.
| Reorder Buffer | ||||
|---|---|---|---|---|
| Company | AMD | Intel | ||
| µarch | Zen | Zen 2 | Coffee Lake | Sunny Cove |
| Renaming | 6/cycle | 6/cycle | 4/cycle | 5/cycle |
| Max In-flight | 192 | 224 | 224 | 352 |
Like Bulldozer, both Zen and Zen 2 have three instruction classification types: FastPath Single, FastPath Double, and VectorPath (aka Microcode). FastPath Single means an instruction consists of one macro-op while FastPath Double means an instruction consists of two macro-ops. The VectorPath means more than two macro-ops (e.g., REP MOV). Macro-operations get cracked into micro-operations following renaming/mapping as they arrive at the schedulers. Generally speaking, since Zen, most instructions were made to translate into FastPath Single dense macro-ops. Looks like this is even truer now with the changes to AVX2.
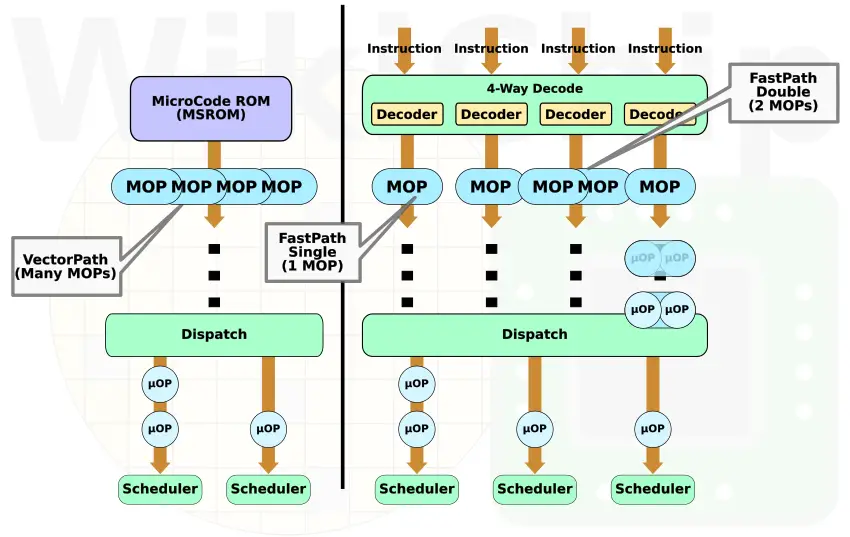
Author’s note: Since the introduction of Zen, AMD no longer makes any effort to disambiguate between x86 instructions, macro-operations, and micro-operations. That, along with a manual riddled with errors makes properly describing the pipeline exceedingly difficult. Nonetheless, WikiChip continues to adhere to describing a model of the implementation that is accurate as much as possible.
Integer
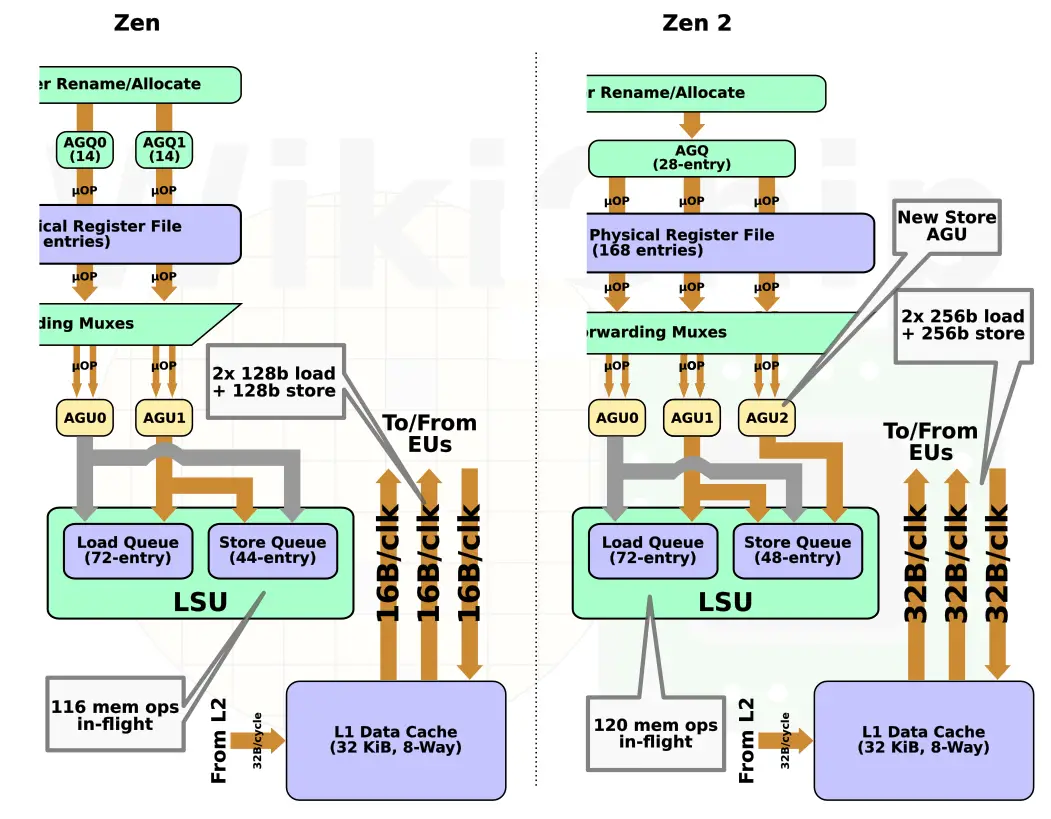
From dispatch, up to 6 MOPS can be dispatched to the integer execution cluster each cycle. Here the MOPs are broken down into their constituent micro-operations. For example, FastPath Single instructions such as add from memory (e.g., reg,[mem]) will get cracked into 2 micro-operations: load and add. Generally speaking, μops can be categorized as either ALU and Load/Store. μops will be sent to the appropriate scheduler depending on their category. Like Zen, Zen 2 has four ALU schedulers. Those schedulers are now two entries deeper, meaning they can queue slightly deeper into the out-of-order window. In theory, there might be some minor opportunity for extracting some extra parallelism from early operand availability. Load/Store μops will get queued at the AGU schedulers. In Zen, there were two AGU schedulers, each 14-entries deep. In Zen 2, those schedulers were merged together into a single large 28-entry scheduler. The total number of entries did not change despite the fact that, as you will see, they chose to add another AGU.
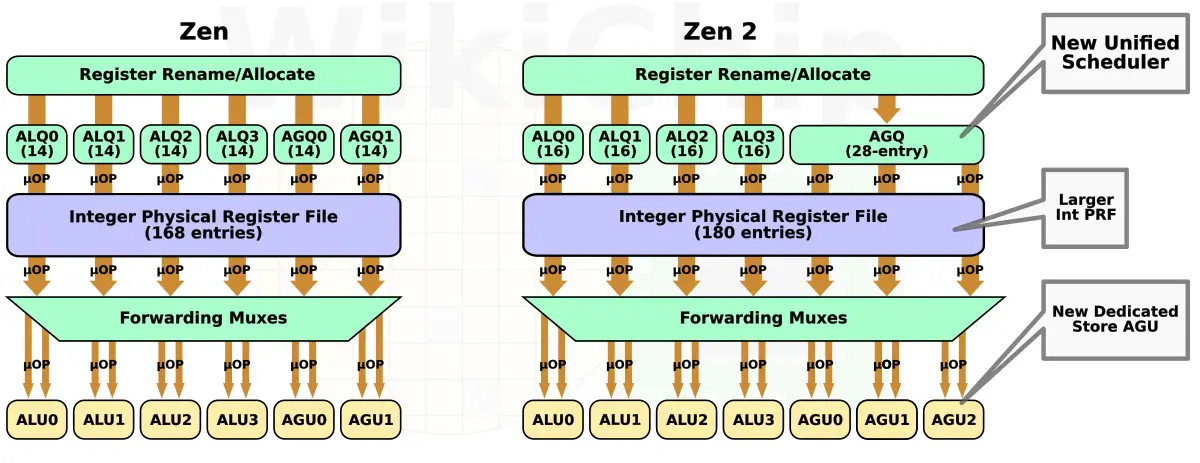
The schedulers queue μops while tracking dependencies and operand availability. Once ready, the μops are sent for execution. Each scheduler can send one μop per pipe per cycle. Like in Zen, there are four ALUs. Zen 2 introduced another AGU so there are now three. We will touch more on this in a section later on.
Floating Point
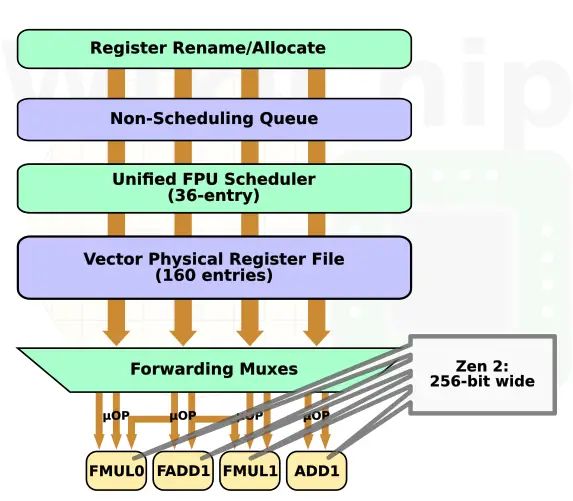
From dispatch, up to 4 MOPS can be dispatched to the floating point unit each cycle. Here the MOPs are broken down into their constituent micro-operations which gets queued at the non-scheduling wait buffer which can initiate memory requests ahead of time. Finally, μops get queued in the 36-entry scheduling queue where they await execution. Most of the floating-point cluster has not changed including the schedulers, their size, and the execution pipes. There are still four execution pipes as well.
The big change in Zen 2 are the widths of the pipes. Zen, Zen+, and Zen 2 all support FMA and AVX2. Prior to Zen 2, 256-bit instructions were decoded as FastPath Double, generating two MOPs, each eventually getting cracked into two μops. Not only did this consume extra resources, but it meant that throughput for 256-bit vectors was half of the throughput for 128-bit vectors. Zen 2 widened the entire FPU datapath. Each of the pipes is now 256-bit wide. Presumably, this means that all of those 256-bit instructions will decode as FastPath Single, generating a single MOP and improving the effective throughput throughout. People who are familiar with Intel AVX2 would know that for AVX2-heavy workloads, the AVX2 offsets will kick in when in turbo mode due to the higher power consumption. Zen 2 doesn’t have similar offsets per se, but you might notice a throttling as part of AMD Precision Boost 2 which governs the temperature and current and is in charge of ensuring that the platform power is not exceeded.

It is worth pointing out that now that the two FMA units are 256-bit wide, the total FLOPs for each Zen 2 core is 16 double-precision FLOPs/cycle. This means they have reached parity with Haswell, Broadwell, and all Intel mainstream client processors. Cascade Lake, however, is capable of 32 double-precision floating point operations per cycle.
| FLOPS | ||||
|---|---|---|---|---|
| Company | AMD | Intel | ||
| µarch | Zen | Zen 2 | Coffee Lake | Cascade Lake |
| Performance (DP) | 8 FLOPs/clk | 16 FLOPs/clk | 16 FLOPs/clk | 32 FLOPs/clk |
Note that currently, AMD does not support AVX512. However, AMD widening of the entire floating-point unit paves the way for conveniently supporting AVX512 as a FastPath Double just as they did with AVX2 originally. Though it’s not all a trivial addition, it’s also not unreasonable to expect the first implementation to be implemented using a narrower pipe (e.g., 256-bit) as in this implementation and run at half throughput just as AVX2 was implemented on Zen and Zen+.
Memory Subsystem
The memory subsystem has been enhanced on Zen 2. The L2 data TLB is now 512-entries bigger and there is new support for 1G pages through 2M page smashing. AMD says that they were able to shave a few cycles from L2 TLB accesses as well.
On the integer cluster side, AMD added a new AGU unit. Unlike the other two units, this one is dedicated to stores. In other words, load μops may be executed on AGU0 and AGU1 while stores can be sent to any of the three units.
More importantly, accommodating the widening of the FPU units, the memory bandwidth for the data cache has also doubled. Zen has a dual-port data cache. It is capable of performing either two reads or one read and one write each cycle. Previously, both ports were 128-bit. Zen 2 is now capable of performing full 256-bit stores and loads. Doubling the bandwidth to 64 bytes will have a positive impact on a class of workloads that relies heavily on AVX2 or copy/stream tasks. Note that the L2 bandwidth remains 32 B, as is the L3.
| Data Movement | |||||
|---|---|---|---|---|---|
| Company | AMD | Intel | |||
| µarch | Zen | Zen 2 | Coffee Lake | Cascade Lake | Sunny Cove |
| LSU | 2×16B Load 1×16B Store |
2×32B Load 1×32B Store |
2×32B Load 1×32B Store |
2×64B Load 1×64B Store |
2×64B Load 2×64B Store |
| L2 BW | 32B/cycle | 32B/cycle | 64B/cycle | 64B/cycle | 64B/cycle |

Heading slightly outside of the core is the level three cache. The L3 supports 32B/cycle of bandwidth to the L2 cache. This cache is a victim cache. It is filled from L2 victim lines from any of the four cores in the CCX with the L2 tags being duplicated over in the L3. With Zen 2, AMD doubled in size of the L3 to 16 MiB – 4 MiB cache slice per core. The impact of this is more noticeable for AMD due to their chiplet design (discussed in a future article).
| L3 Cache | |||||
|---|---|---|---|---|---|
| Company | AMD | Intel | |||
| µarch | Zen | Zen 2 | Coffee Lake | Cascade Lake | |
| L3 | 2 MiB/slice | 4 MiB/slice | 2 MiB/slice | 1.375 MiB/core | |
| Type | Victim | Victim | Miss | Victim | |
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–