
SC19: Aurora Supercomputer To Feature Intel First Exascale Xe GPGPU, 7nm Ponte Vecchio

Today, at its own Supercomputing 2019 satellite event, Intel is making some additional disclosures regarding its exascale supercomputer – Aurora, as well as its Xe GPU.
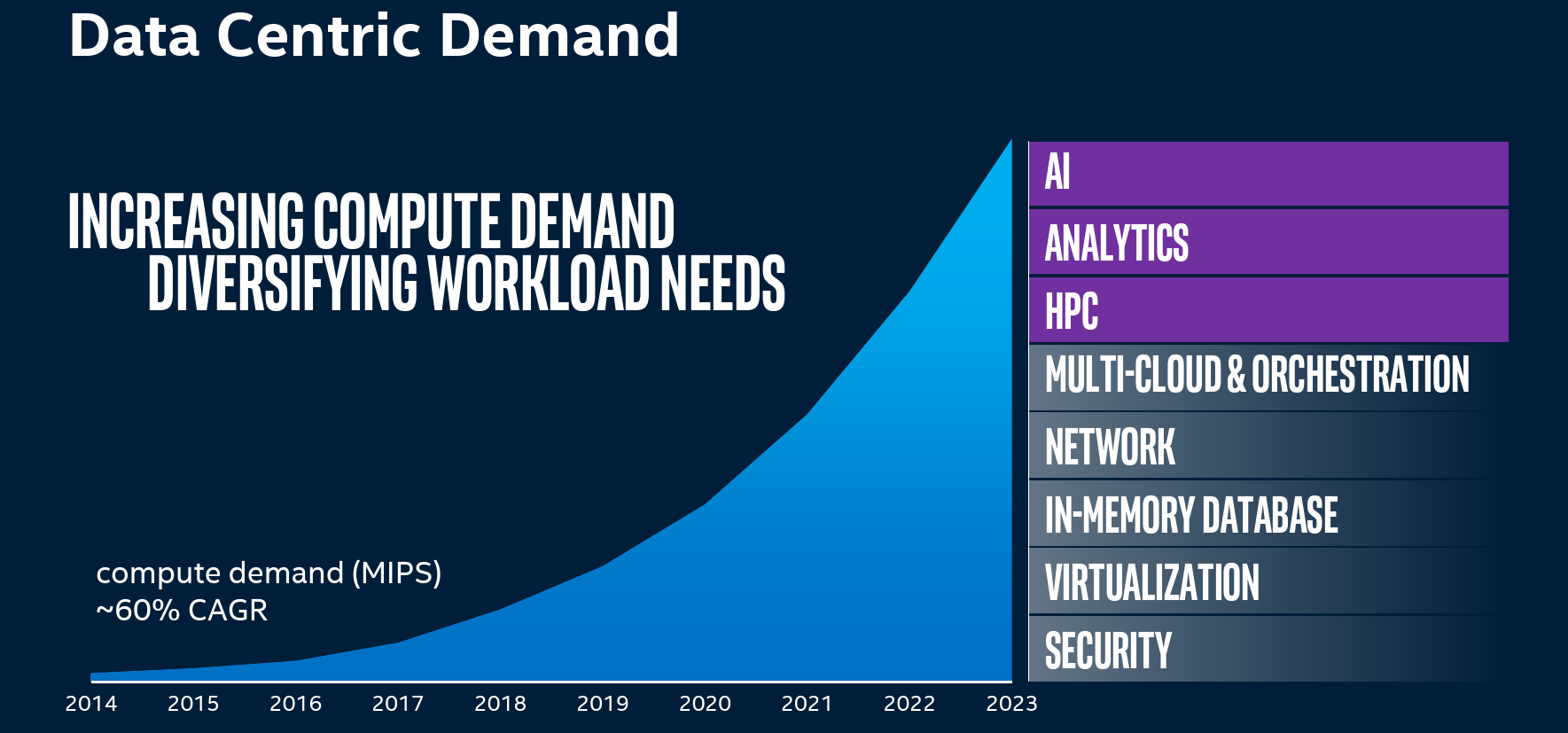
Intel has been talking about a number of new and growing general trends in HPC over the last couple of years. There is a transition in HPC from traditional closed-form equations to data-driven AI-based insights which is augmenting simulations and traditional system modeling. Going into the 2020s, Intel also sees significant tailwind in the area of heterogeneous computing. One size no longer fits all and new, more specialized hardware is needed in order to deliver higher performance and power efficiency in various workloads. To that end, it is predicting that going into 2025, compute demand (in MIPS) will be growing at a CAGR of 60%. This is in line with some of the other numbers we have seen by competitors. The workload itself is also diversifying with AI, analytics, and HPC being the fastest growing specialized workloads in addition to being the most demanding performance characteristics.
Xeon Remains Center Stage
With the ever-increasing diverse workload, the most flexible XPU is the company Xeon CPU. Intel is reaffirming that Xeon processors are clearly remaining the workhorse processor for the foreseeable future. Here Intel is also reiterating their roadmap for the next couple of years. Currently, the company is shipping its Cascade Lake-based Xeon processors which introduced both Optane DC persistent memory and AVX-512 VNNI designed for the acceleration of inference workloads. Next year, Intel will be launching Cooper Lake which is also on 14-nanometer and will be introducing BFloat16. Pushed a little further out, ramping in the second half of 2020, is the 10-nanometer Ice Lake server parts that incorporate the Sunny Cove cores. Intel says that its next big jump will be happening in 2021 with Sapphire Rapids. Though Intel isn’t disclosing any details just yet, it is saying it will be highly capable in terms of both scale-up and scale-out performance.

XPU
At his Keynote, Raja reiterated the heterogeneous system approach that Intel is going for with the XPU. While they will continue to develop their CPUs and it will remain the work component, the other XPUs such as the GPU, FPGAs will play a bigger role in their future platform.

Xe Architecture: One Architecture, Many Flavors
![]()
Intel first unveiled the Xe name back at its 2018 Architecture Day. At the time, Raja Koduri explained that the company saw a need for a unified architecture that could be derived into a number of different workloads and markets. This is essentially what Xe is. Xe is a uniformed GPU architecture intended to scale from traditional lightweight gaming on mobile PCs to demanding games in the gaming market, and all the way up to exascale and HPC applications which require vastly different capabilities. “It was very fundamental for us that it must be one architecture. We wanted only one architecture because we wanted to think about the developers which need one common framework, “ said Ari Rauch VP and GM of Intel Visual Technologies Team and Graphics Business.

It’s important highlighting the fact that Xe is the architecture. Based on Xe, Intel will be designing a number of separate microarchitectures depending on the target market design point. In its recent earnings call, Intel CEO Bob Swan announced that the company achieved power-on of its first discrete GPU. Consumer-based products based on the Xe architecture will make it to market in 2020. Today, Intel is only talking about the specific microarchitectures designed for HPC and AI. The kind of optimizations designed for intense gaming workloads will look quite different.
For the HPC and AI market, Intel Xe still uses the same common programming model. The optimizations here are around intensive data-parallel vector and matrix operations. The details here are still high level but they can still give us a good idea of what’s going on. The first thing Intel was highlighting is the cores that were designed to be highly flexible in accelerating data-parallel work. The work revolves around high double-precision floating-point precision along with high floating-point throughput. There was a lot of emphasis on memory bandwidth capabilities. Again, a lot of high-level details here but we can sort of get a picture of what they are going for.

Ponte Vecchio
All of this leads us to Ponte Vecchio. Ponte Vecchio is Intel’s first Xe GPGPU for exascale supercomputers. It implements the Xe architecture in the flavor suitable for HP and AI workloads as we described earlier. Ponte Vecchio will be fabricated on Intel’s next-generation 7-nanometer process technology. The GPU will also be leveraging the company’s 3D Foveros packaging technology. “This is really enabling us to put in a single package, multiple tiles of the same engine and then scaling up the performance in an efficient way, leveraging the memory and bandwidth that we are also building into it,†said Rauch. Rauch’s statement strongly implied the chip will consist of both EMIB (laterally) and Foveros (vertically), though when asked, Intel opted to not disclose whether that’s the case at this time. Ponte Vecchio will also be utilizing CXL and PCIe Gen 5, enabling unified memory across multiple Ponte Vecchio GPUs.

Aurora
All of the above leads us to Aurora. This supercomputer is intended to be the United States’ first exascale supercomputer in collaboration with the DoE and Cray. The computer will be delivered in 2021. Today, Intel is revealing a number of new details about its supercomputer – the node architecture.
Aurora is a very large system – more than 200 racks based on Cray’s Shasta supercomputer architecture with more than 230 PB of storage and more than 10 PB of memory. Each node comprises two CPUs and six GPUs. Nodes are interconnected using Cray’s upcoming Slingshot interconnect. Within a node, the two CPUs in each node are Intel Xeon Scalable CPUs based on the Sapphire Rapids microarchitecture which means it will most likely be incorporating the Willow Cove core. The six GPUs HPC Xe GPUs based on Ponte Vecchio. The entire node uses a unified memory architecture interconnected using the Compute Express Link.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–