
Arm Unveils Next-Gen Flagship Core: Cortex-X3

Today arm is introducing its new next-generation flagship core, the Cortex-X3. The Cortex-X3 CPU is a third-generation core as part of the Cortex-X custom core program designed to bring higher performance through slightly different PPA tradeoffs versus the mainstream performance big core.
This article is part of a series of articles covering Arm’s Client Tech Day 2022.
- Arm Refreshes The Cortex-A510, Squeezes Higher Efficiency
- Arm Introduces The Cortex-A715
- Arm Unveils Next-Gen Flagship Core: Cortex-X3
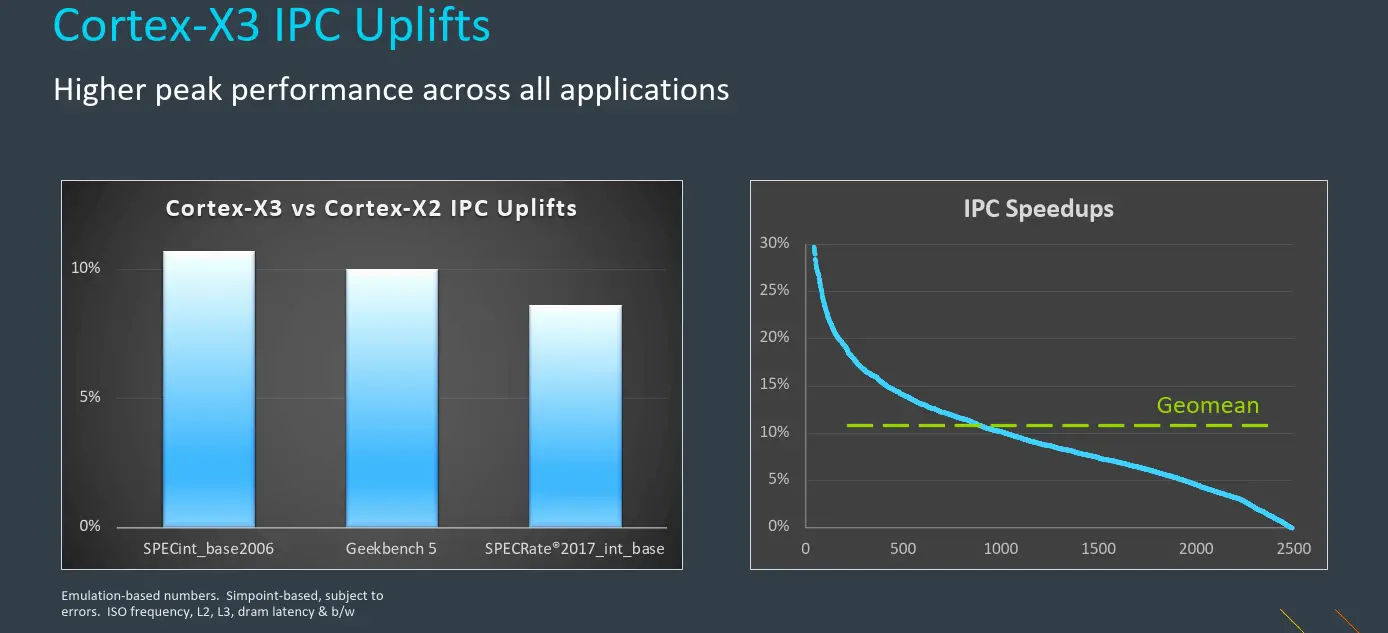
In terms of performance, the Cortex-X3 is said to deliver an 11% IPC uplift which Arm says marks the third consecutive year of double-digit IPC gain on the Cortex-X series. On the system level, coupled with all other changes, in real applications Arm says the new core can deliver as much as 22% higher performance.
Microarchitectural Changes
According to Chris Abernathy, the core’s chief architect. The process of eliminating 32-bit and optimizing for the 64-bit ISA exclusively has been a 2-step process. With the Cortex-X2, the underlying circuitry used for handling 32-bit architectural-related elements was removed, saving on transistors and simplifying some structures. With the new Cortex-X3, the design team took the time to start optimizing specifically for AArch64. In particular, many optimizations to fetch and decode took place taking advantage of the more predictable and regular nature of the AArch64 ISA.
To that end, the majority of design changes took place to the Cortex-X3 front-end which made targeted improvements to the branching mechanism and optimized for large applications with larger instruction footprints
The Cortex-X3, like its predecessors, features a decoupled front end. For Arm, this means that the branch predictors operate at a much large bandwidth than the instruction fetch and can run considerably ahead of fetch. This allows the branch predictors to double up as instruction prefetchers. This gives them a number of advantages. For one, they are able to absorb much of the latency by making the instruction stream fetch requests into the L2 and L3 far ahead. This helps absorb pipeline-taken branch bubbles. It also means the effective L1 caches can be kept small, saving on power and far more importantly saving on silicon area. As we have seen in more recent advanced nodes, SRAM bitcells are no longer shrinking nearly as much as they used to. Keeping those structures small is now more important than before.
In the X3, Arm increased the run-ahead window depth, allowing the core to fetch instruction much further out in time. From the X2 to the X3, the branch target buffers are said to grow significantly in capacity to store more targets (over 50% growth in the L1 and L2 BTBs). It’s worth noting that due to the increase in capacity, the X3 actually introduces an L2 BTB to break down the larger single structure with more incremental latency. There are now effectively three levels – L0, L1, and L2 – each with increased latency over the lower level. The quick, single-cycle, turnaround L0 BTB is now 10x larger in capacity which is pretty significant growth.

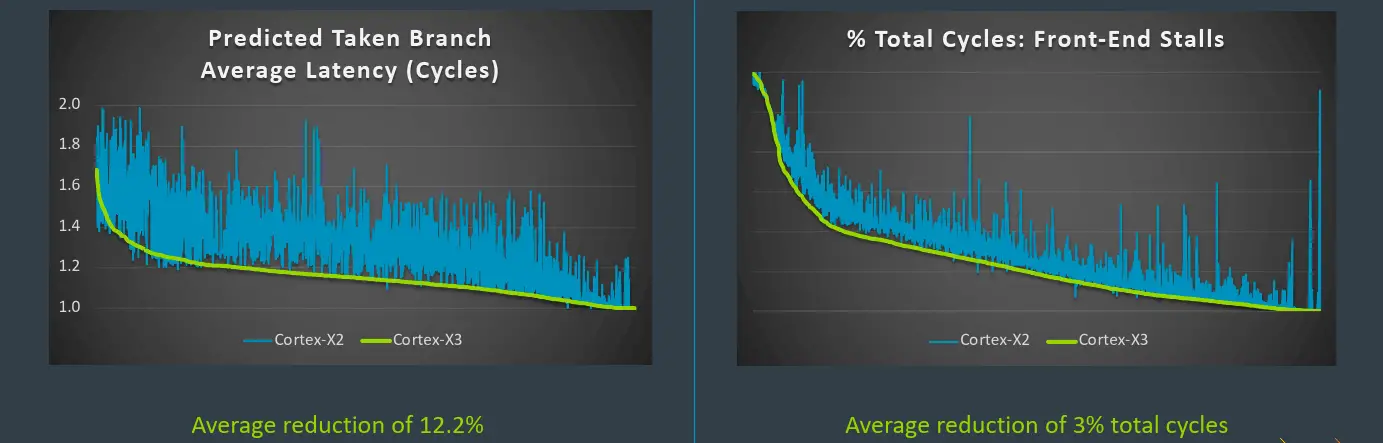
Plotting the predicted taken branch on the Cortex-X2 vs the Cortex-X3, Arm says they see an average of 12.2% reduction in cycles due to better branch taken prediction across various real-world workloads. Overall, they also demonstrated around a 3% reduction in total cycles as resulting from front-end stalls such as a branch taken bubble or branch misses.
Another big improvement in the Cortex-X3 was dealing with indirect branches. Indirect branch prediction was said to be given a first-class treatment in the new Cortex-X3. What this entails is a brand new small, but dedicated indirect branch predictor designed to improve accuracy and enable lower latency. The TAGE predictor used for conditional branches also received some incremental improvement. Overall, the X3 is said to deliver an average reduction of 6.1% in branch mispredict over the X2.

Instruction Fetch
On the instruction fetch side of the code, the MOP cache also had various improvements. Arm modified the fill algorithms in order to minimize the thrashing and pollution. This change is said to allow them to reduce its size by half without hurting its performance. Previously, the MOP cache had 3K-entry capacity. This has been reduced back to 1.5K which is actually the same size as the original A77 was when the MOP was first introduced. It is worth noting that despite the reduced capacity, Arm is maintaining the 8 MOPs/cycle bandwidth as with the prior generation. On the performance side of things, partially due to its size reduction, the MOP cache on the Cortex-X3 is now a single pipe stage shorter – going from ten to nine now.
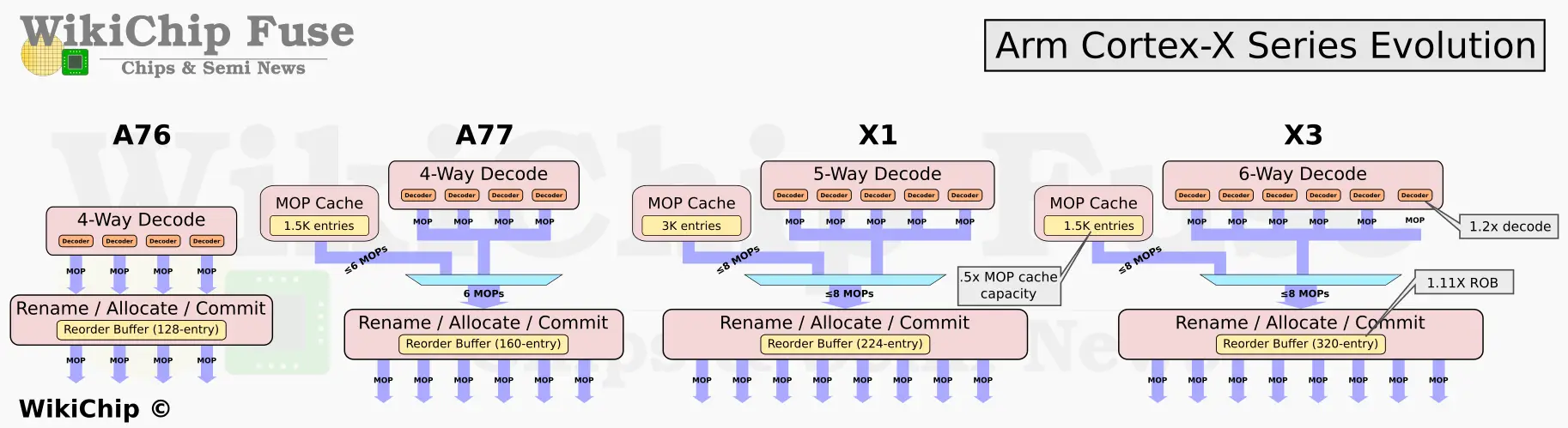
The MOP cache is designed for small, tight, repeatedly executing code. For larger applications that do not fit in the MOP cache, the X2 could still easily be bottlenecked by the narrower instruction cache. On the X3, Arm increased the fetch and decode bandwidth. It’s now possible to decode up to six instructions per cycle, a 1.2x increase in bandwidth for higher sustained IPC.

OoO and Execution
The new core has a larger OoO window – up to 320 entries which can translate to up to 640 instructions in flight in a best-case scenario. Due to a large number of in-flight instructions, following a flush, rebuilding the rename tables needed further optimizations. Here Arm redesigned the renaming-rebuild mechanics to better handle a large number of instructions in-flight.

Memory Subsystem
There were other smaller memory subsystem changes. The integer load bandwidth has increased from 24B/cycle to 32B/cycle. There are no specific dedicated load and store queues per se on the Cortex-X3, but collectively those structures grew by 25%. As with every generation, Arm continued to improve its data access pattern predictors. In the X3, Arm added two additional data prefetchers. The first one is to handle spatial patterns. The other is a pointer/indirect prefetch that deals with pointer chasing sequences.

Performance
All in all, the Cortex-X3 is said to deliver a geomean IPC improvement of around 11% on a set of real-world applications.
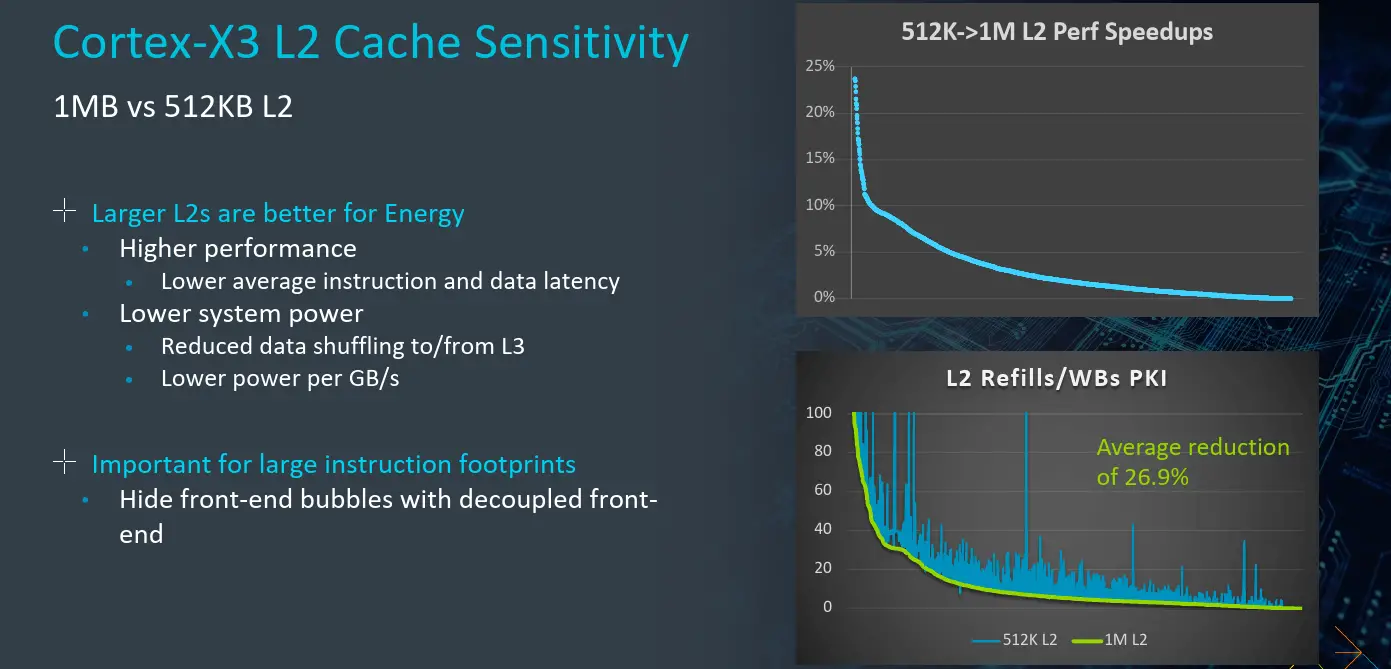
Cache Sensitivity
One interesting aspect of the Cortext-X3 is the choice of L2 cache size. This can be 1 MiB or 512 KiB. The choice between the two boils down to area versus performance tradeoff. With the larger 1 MiB L2 cache, the core benefits from both higher performance and lower system-level power due to less L3 thrashing. Overall the larger cache can see up to a 26.9% reduction in refill/writebacks requests.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–