
Arm Launches New Neoverse N1 and E1 Server Cores
Neoverse E1
The Neoverse E1 design targets high throughput. Arm says that compared to the Cortex-A53, the E1 offers 2.7x the throughput performance, 2.4x the throughput efficiency, and 2.1x the compute performance.

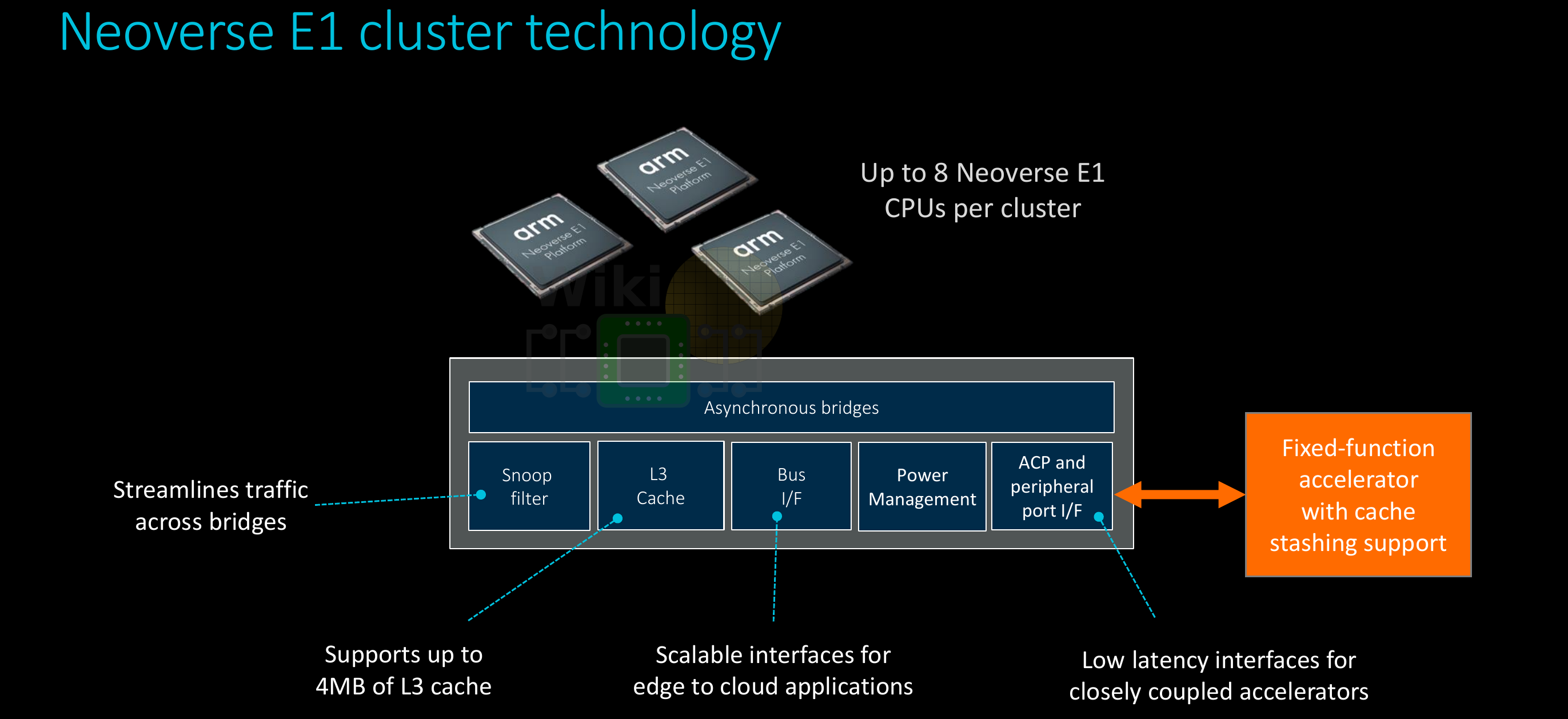
The E1 is organized very differently from the N1. Up to eight E1 cores are packed together in a single cluster. The clusters themselves are very similar if not identical to Arm’s existing DynamIQ clusters albeit they have not used that actual name to refer to them so they might be slightly tweaked for infrastructure workloads.
The Neoverse E1 features a 10-stage accordion integer pipeline that may stretch out to 13 stages. The E1, like most of Arm’s high-efficiency cores, is relatively small. However, there are a number of major differences that departs from the traditional cortex design. The E1 is two-way superscalar with a 3-issue OoO back-end.
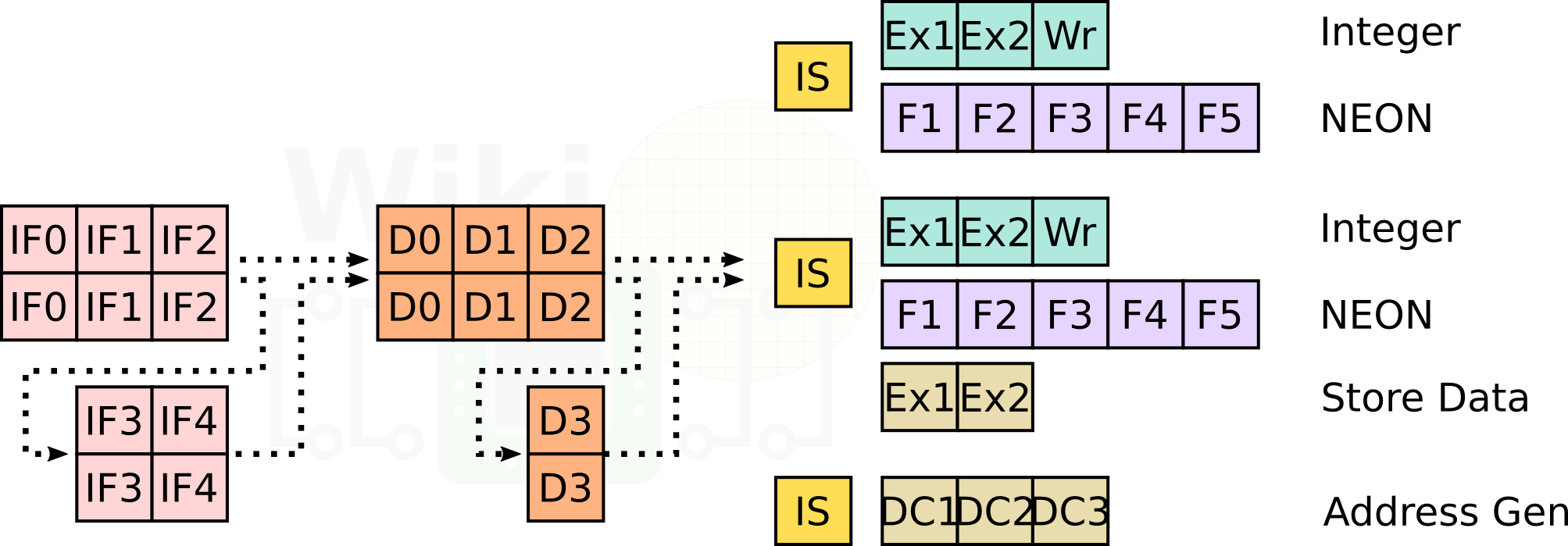
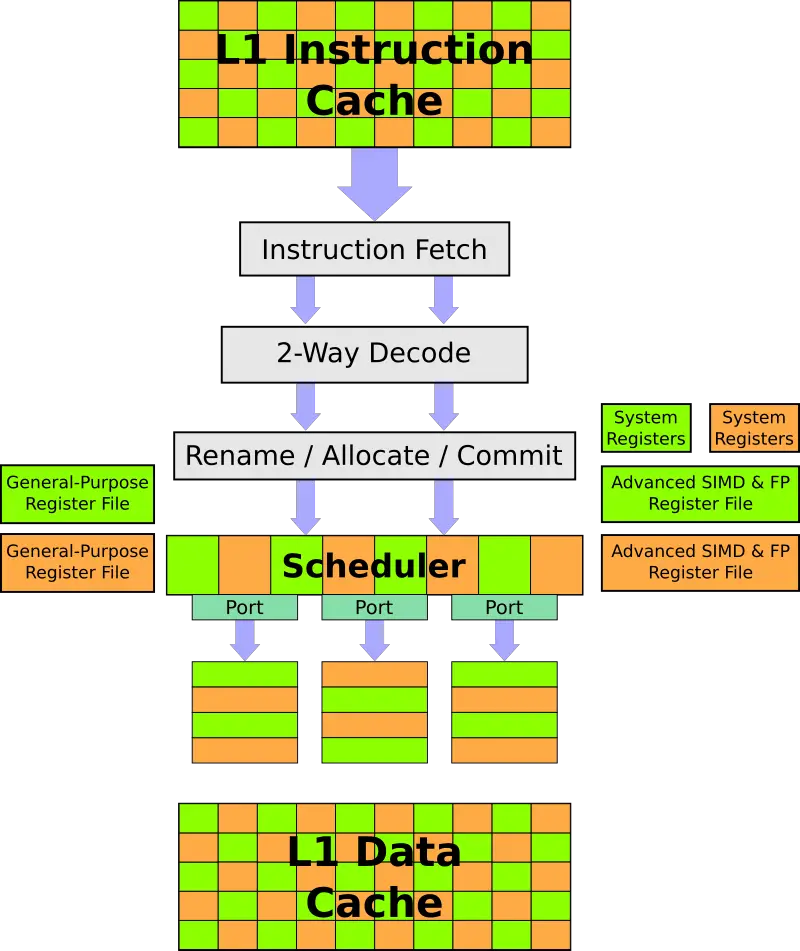
The E1 has a configurable 32 KiB or 64 KiB instruction and data caches. There is also an optional private L2 cache which can be configured between 64 KiB and 256 KiB. The caches have very low latencies – 2-cycle L1 and 6-cycle L2 for fastest load-to-use. Each cycle 8 bytes (2 instructions) are fetched and queued. The E2 can decode up to two instructions each cycle. Up to three instructions are issued each cycle to the execution units.
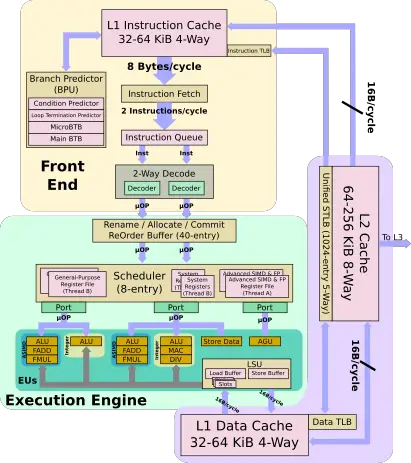
The E1 has three ports – a dedicated AGU port and two mixed execution ports. Both execution ports feature an integer pipeline and an advanced SIMD pipeline. One of the ports is also capable of complex integer operations. Note that all units are 64-bit wide, this applies to both the integer as well as the NEON EUs. Supporting ARMv8.2, this means up to eight 16-bit operations per cycle or up to four 32-bit to sixteen 8-bit operations with the dot product instructions.

Compared to the N1, the E1 is extremely power and energy efficient. On a leading-edge 7 nm process, the E1 takes up just 0.46 mm² for the E1 core with 32 KiB L1 and a 128 KiB L2. The target design point for the E1 is around 2.5 GHz at 183 mW.
Multithreading
The Neoverse E1 uses simultaneous multithreading in order to hide memory latency across threads. Compared to the Cortex-A55, a single-threaded Neoverse E1 core reduces the number of stalled cycles by half in various typical network and packet processing workloads. Arim claims that use of multithreading on the E1 can further reduce this by another 20-40%.
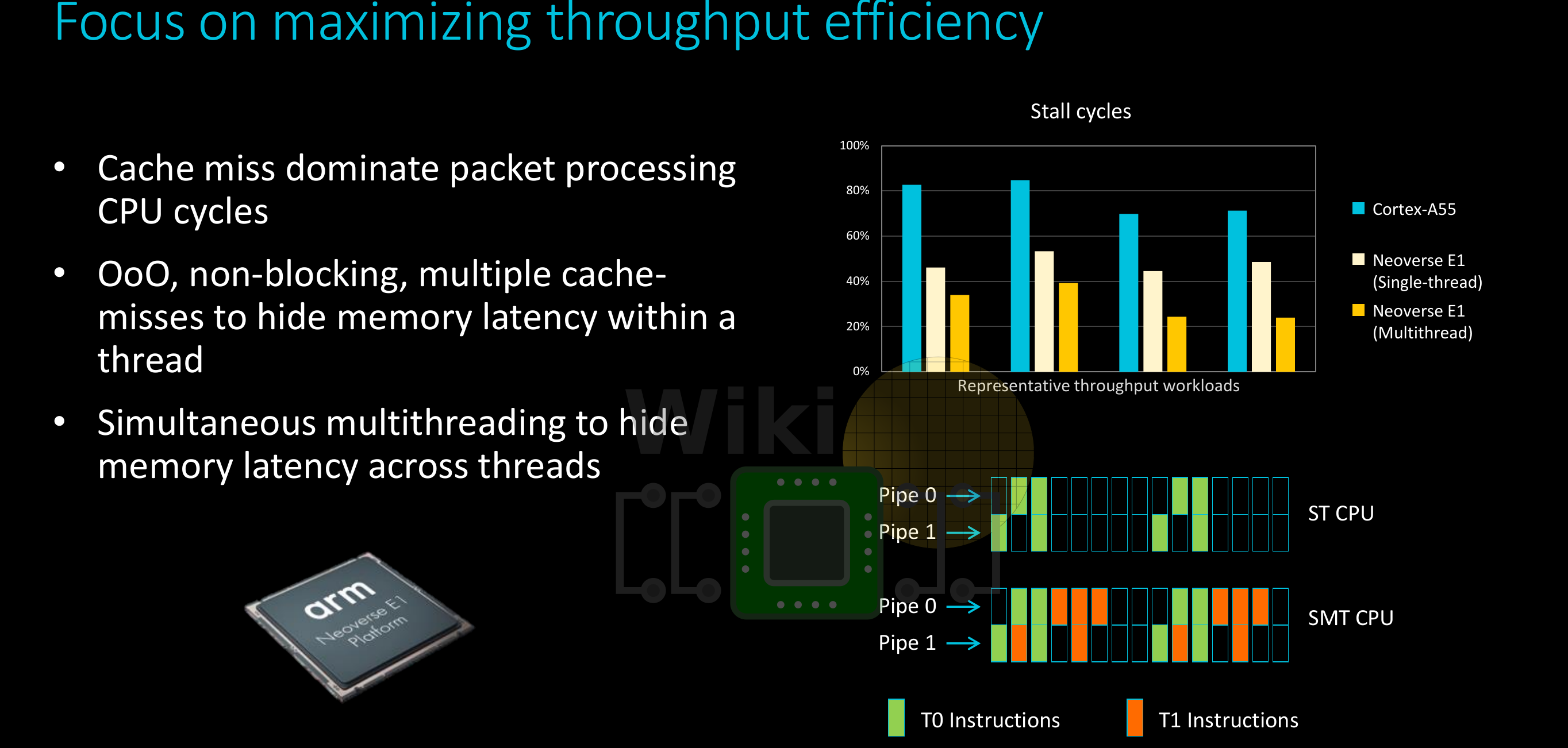
The E1 is fully multi-threaded – each thread can operate at a different exception level, running a different OS/VM. To the software, each hardware thread appears as a separate logical core. The E1 duplicates GP RF, Vector RF, and the system registers for each thread. Each cycle, the instruction fetch alternates round-robin between the threads, depending on availability. The OoO backend, starting from the reservation station all competitively share the resources between the two threads.
Customization
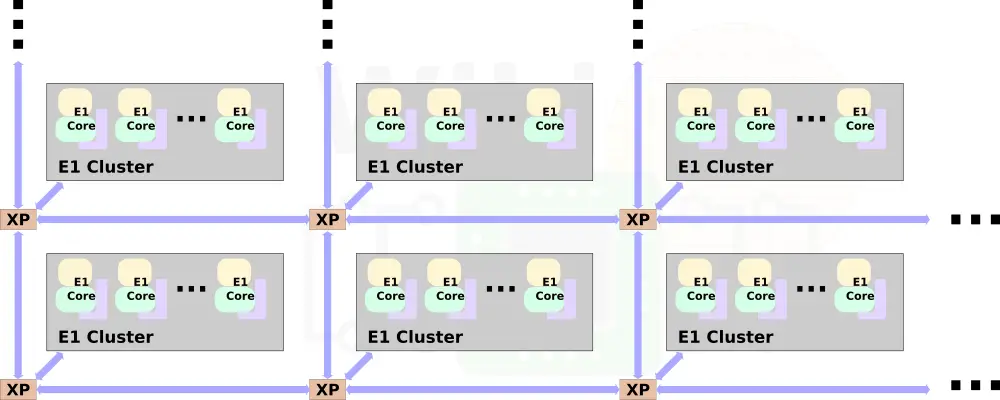
Customization is at the center of the Neoverse E1 platform. Like the N1 platform, multiple E1 clusters may be combined using Arm’s Coherent Mesh Network 600 (CMN-600) mesh architecture.
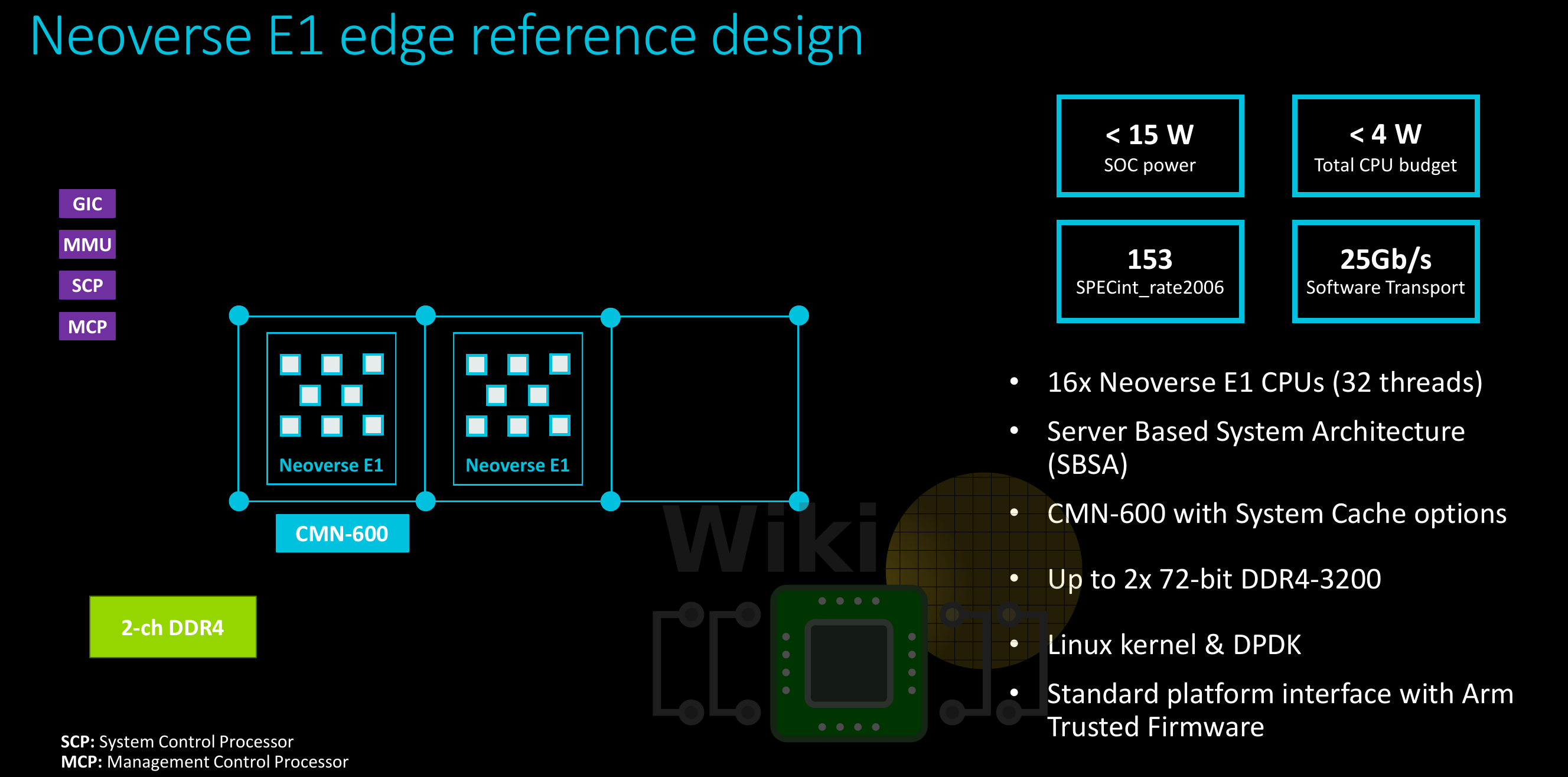
In fact, one of Arm’s reference design uses a two-cluster setup. The full SoC design has 16 cores and 32 threads along with a DDR4 memory controller (2 channels). For that design, the total CPU power budget is at less than 4 W with a total SoC power of less than 15 W.
Beyond the homogeneous design, it might be advantageous for some designs to feature a heterogeneous mixture of compute units. The Neoverse N1 and E1 are designed such that they can be mixed and matched along with other custom IP blocks to form a more complex SoC that addresses the needs for specific workloads.
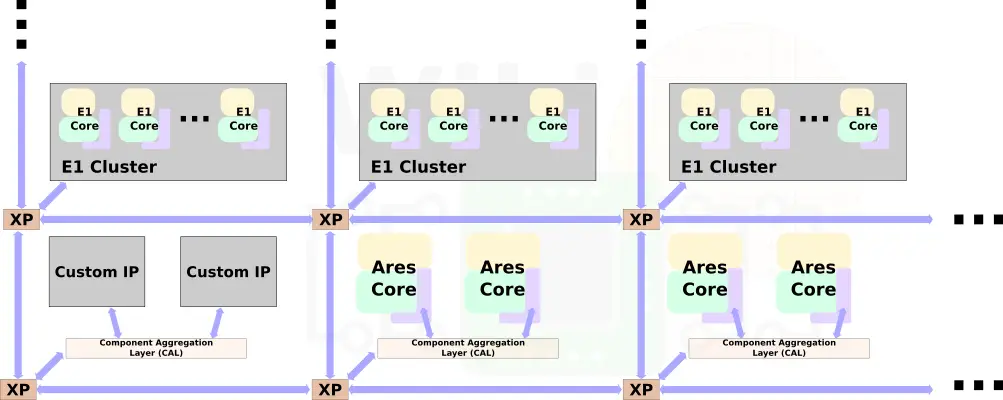
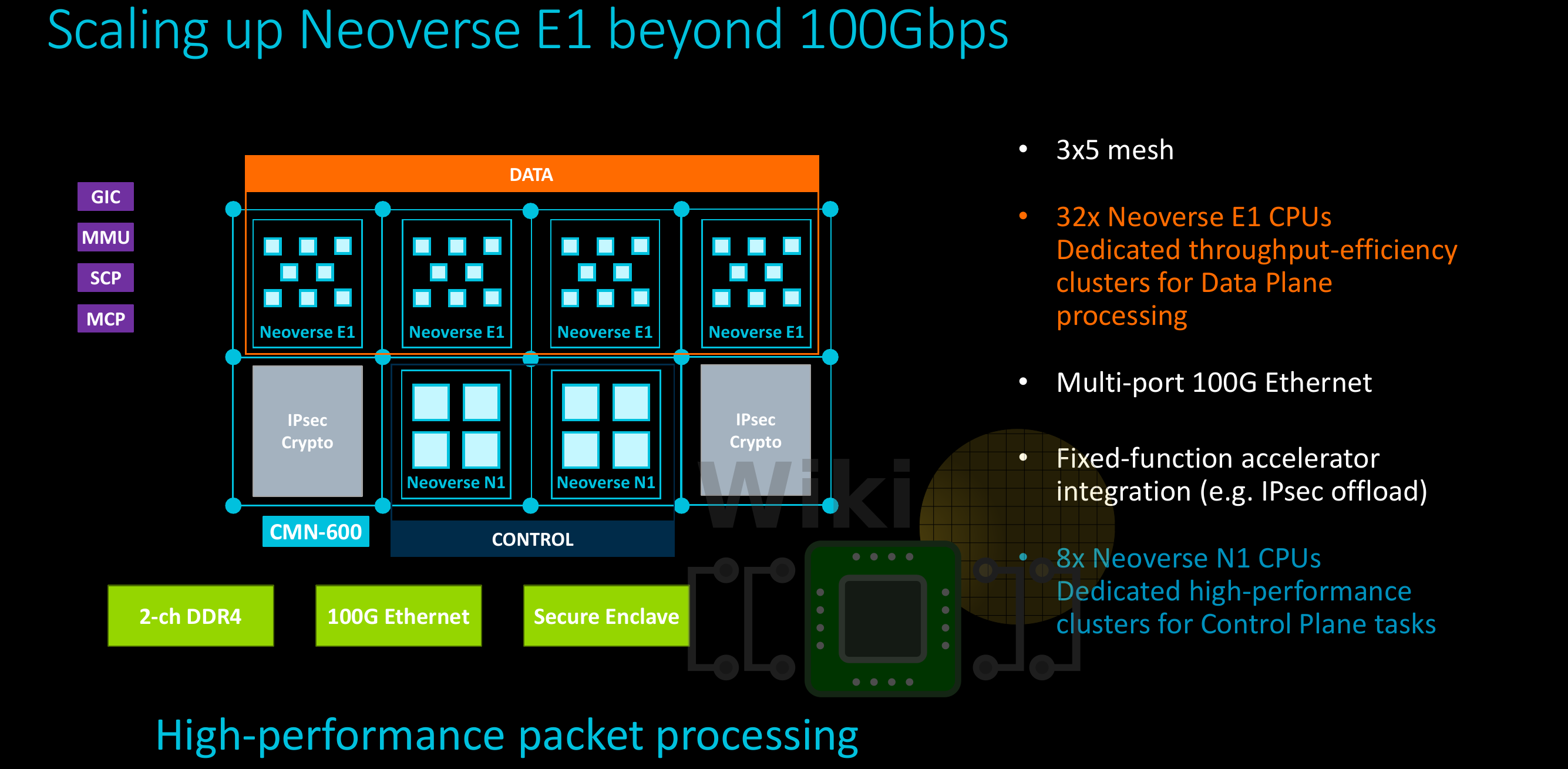
One of the other reference designs Arm talked about is for networking applications. This design incorporates 32 Neoverse E1 cores for throughput along with 8 Neoverse N1 cores for high-performance processing and management and some customer IP components.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–