
Arm Introduces The Cortex-X4, Its Newest Flagship Performance Core

Today, Arm is launching the Cortex-X4, the company’s next-generation flagship performance core and the highest-performance Arm core designed to date.
This article is part of a series of articles from Arm’s Client Tech Day:
- Arm Launches Next-Gen Efficiency Core; Cortex-A520
- Arm Introduces A New Big Core, The Cortex-A720
- Arm Introduces The Cortex-X4, Its Newest Flagship Performance Core
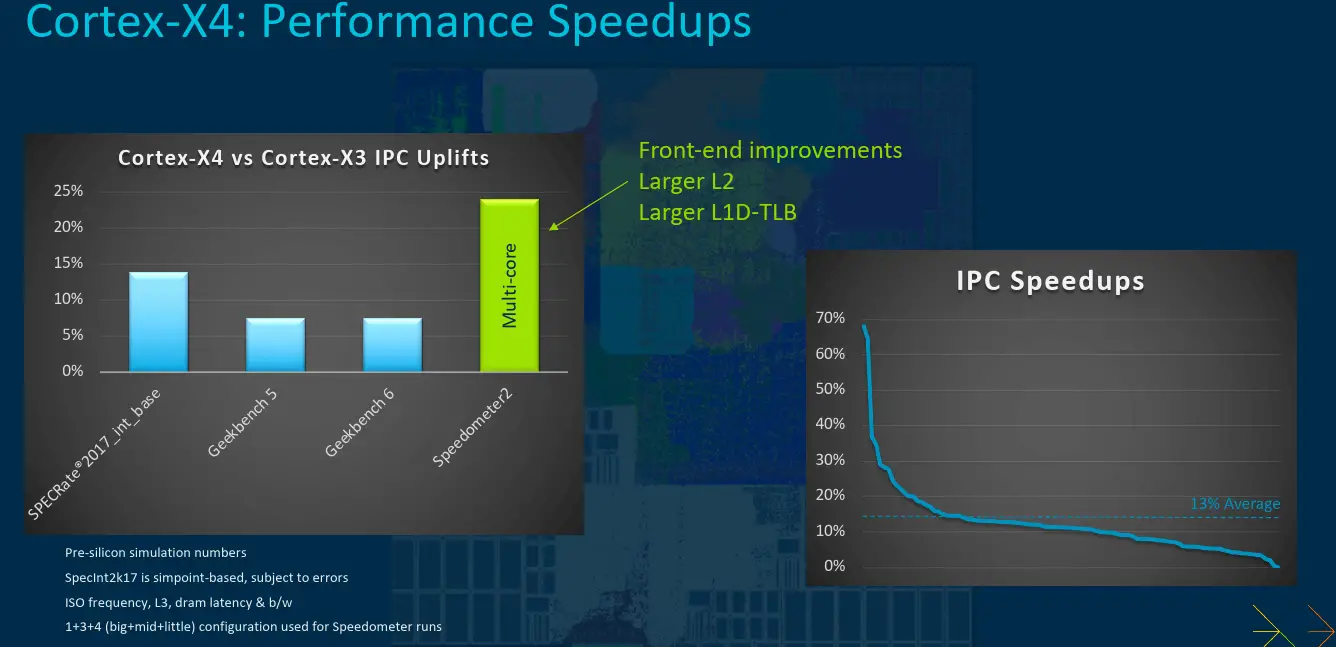
The Cortex-X4 is Arm’s newest flagship core. Arm says it offers 15% performance uplift over the Cortex-X3. Arm wanted to highlight that this represents the 4th generation in a row to deliver double-digit IPC improvement which is also every generation since the Cortex-X series introduction. The performance uplift in the Cortex-X4 comes at minimal area cost of less than 10% for identical cache sizes.

Like its predecessor, the Cortex-X4 focuses on peak performance that’s needed beyond the performance offered by the Cortex-A720 under various workloads. The Cortex-X4 achieves its performance improvements through numerous changes throughout the pipeline. We will detail some of them here.
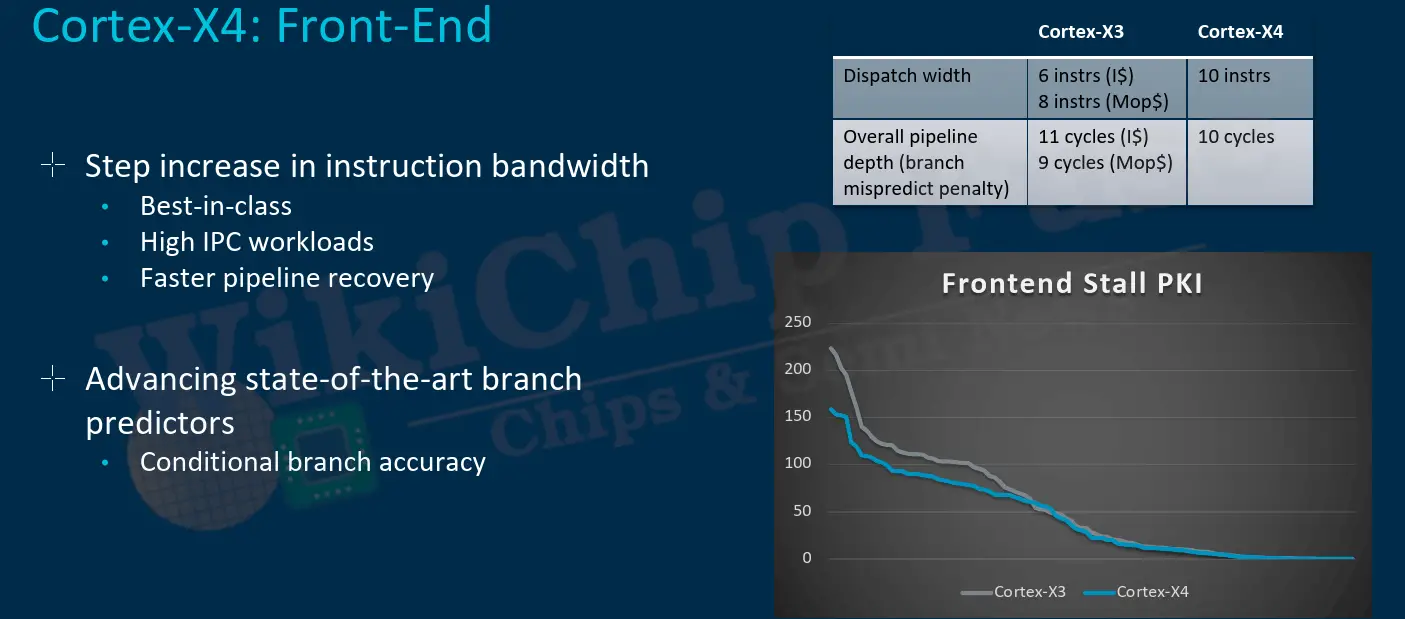
Front-End
Arm says that the front-end of the Cortex-X4 has seen some significant changes. The instruction fetch delivery has been completely redesigned. As with the Cortex-A715, it seems that the Cortex-X followed suit and also dropped the macro-operations cache entirely. Instead, the Cortex-X4 widened the pipeline to support up to 10 instructions. The instruction cache was also enhanced accordingly. With a bandwidth increasing to 10 instructions per cycle.
Arm says the new branch predictors accuracy have also been improved with measurable reduction in stalls observed in real workloads. With the changes to the instruction cache and macro-operation cache, branch misprediction penalty was unified and reduced to 10 cycles.
Back-End
The out-of-order back-end has been enhanced as well. On the integer side of the execution unit, Arm updated the MUL unit in the prior generations into a full MAC unit. That means the X4 now has 2 integer MAC units. A third branch unit has also been added. Finally, two additional integer ALUs were added for a total of 8 – 6 of which are on dedicated pipes.
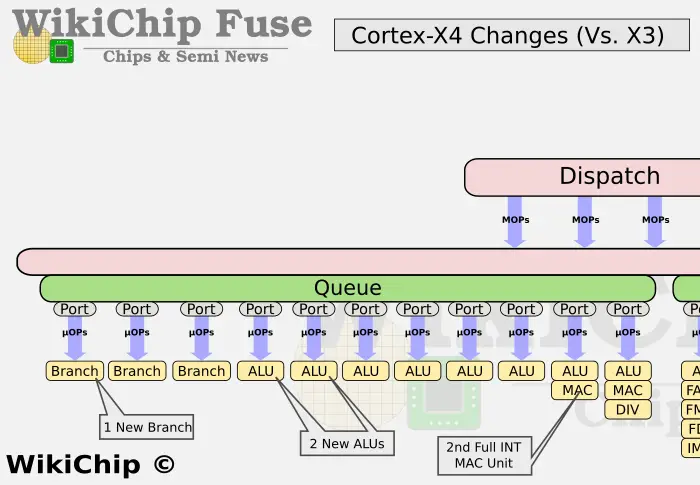
The out-of-order buffer on the Cortex-X4 was increased by 20% from 320 on the Cortex-X3 to 384 here. In fact, Arm has been increasing the ROB by anywhere from 10-30% each generation. To put that in perspective, the Cortex-X4 ROB is now bigger than Intel’s Sunny Cove core which had 352 entries – albeit not nearly as much as Golden Cove with a whopping 512-entries ROB.
| Reorder Buffer | |||||
|---|---|---|---|---|---|
| uArch | Cortex-X1 | Cortex-X2 | Cortex-X3 | Cortex-X4 | |
| Dispatch | 8/cycle | 8/cycle | 8/cycle | 10/cycle | |
| Max In-flight | 224 | 288 | 320 | 384 | |
On the floating-point side, Arm fully pipelined the divider/sqrt units. The pipes and units themselves remain unchanged.
Memory
On the memory subsystem side, Arm re-balanced the pipes. Whereas previously, the Cortex-X3 had two generic AGUs and a single dedicated load AGU, the Cortex-X4 now only has a single generic AGU along with two load AGUs and one store AGU.
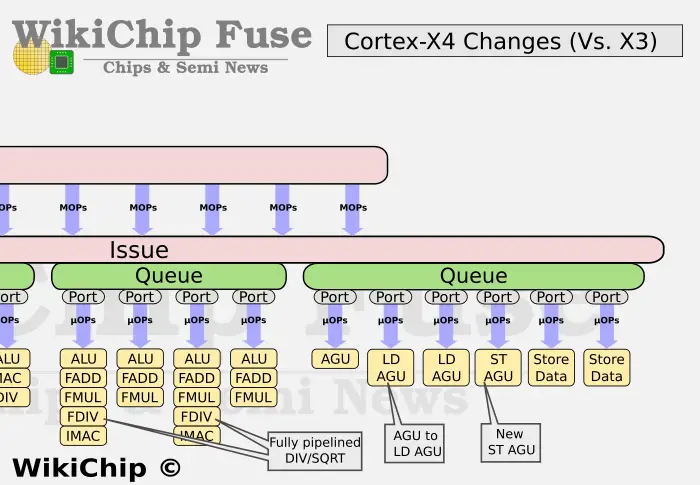
As with the instruction caches, the Cortex-X4 also received enhancements to the data prefetchers. Arm says it has also added a new L1 temporal data prefetcher. Arm says it also reduced L1 data bank conflicts and doubled the L1 TLB as part of the L1 changes.
The private L2 cache on the Cortex-X4 is also enlarged. System integrators can now opt to integrate as much as 2 MiB of L2 cache which would double the L2 cache over the prior generation. System designers can opt to use smaller cache sizes in more restricted environments if too, if desired. Arm says that there is no latency hit for the larger caches. This option allows for higher performance on applications with large memory footprint that could use the closer proximity to the cores for frequent references.
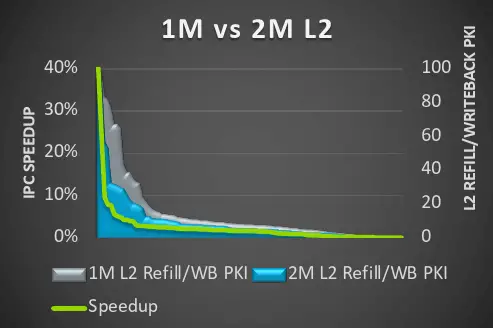
All in all, the Cortex-X4 delivers around 13% IPC improvement at ISO-frequency and L3 (albeit with the larger L2).
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–