
A Look at Cavium’s New High-Performance ARM Microprocessors and the Isambard Supercomputer
A Long Time Ago in a Land Far Far Away … That Executed MIPS64
So how similar is the ThunderX2 to the ThunderX(1)? Well, turns out there is really no relation whatsoever. You see, in May of 2005, Raza Microelectronics (RMI) introduced the XLR brand. This was their first custom family of MIPS64 processors. Those processors packed up to eight MIPS64-compatible cores operating at up to 1.5 GHz, each supporting 4-way multithreading for a total of 32 threads. Each core supported fine-grained multithreading whereby thread executions was switched each cycle depending on thread readiness. Each core had 32 KiB of L1 data and 32 KiB of L1 instruction cache and a single shared 2 MiB L2 cache. Though the 10-stage pipeline design was fairly simple, the goal of introducing support for four hardware threads in order to reduce bubbles and stalls was achieved. XLR was fabricated on TSMC’s 90nm process, containing 333M transistors on a 226.44 mm² die.
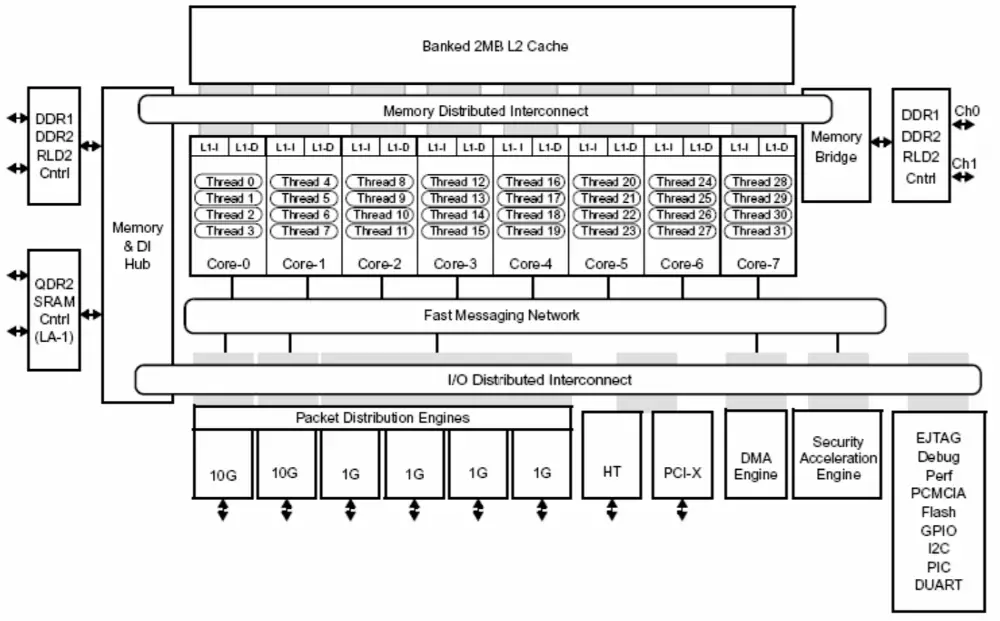
In 2009 things got a little more interesting when NetLogic announced that they will acquire RMI. Shortly before that announced, RMI introduced their 2nd generation design along with their XLP processor family. NetLogic’s XLP family moved to 40nm, bumping the clock to 2 GHz. The design was modified quite substantially too, reverting to a more contemporary design. Whereas the original XLR design was a single issue in-order machine that switched between ready threads each cycle, the new XLP design is a 4-way issue out-of-order design. The new design added two additional stages. Each cycle, four instructions from a ready thread would be fetched and decoded into one of the five slots in the instruction queue. Four instructions from a single thread from one of the slots would then get issued to the execution units. The XLP was much more complex than the XLR. Dispatch performs register renaming and instructions within the instruction queue slot can be dispatched for execution out of order.
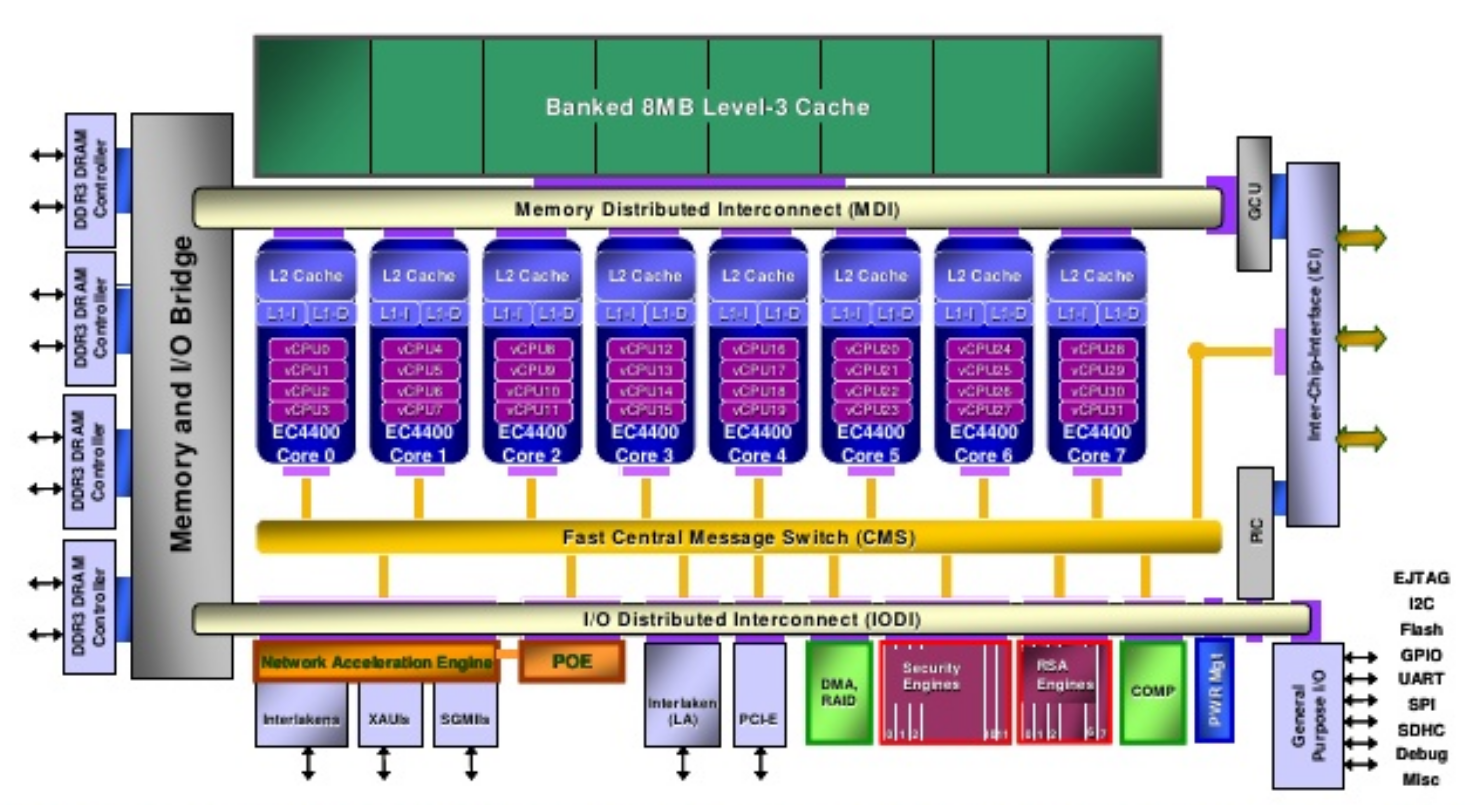
By Late 2011 NetLogic introduced the XLP II family which brought a set of more incremental improvements to the core while reworking most of the overall system architecture. The XLP II was fabricated on a much smaller 28nm process, allowing for more cores to be packed on a single chip. Before NetLogic’s design ever made it to market, Broadcom acquired them. They did keep the XLP II brand name and finally introduced those processors into the market in late 2012.
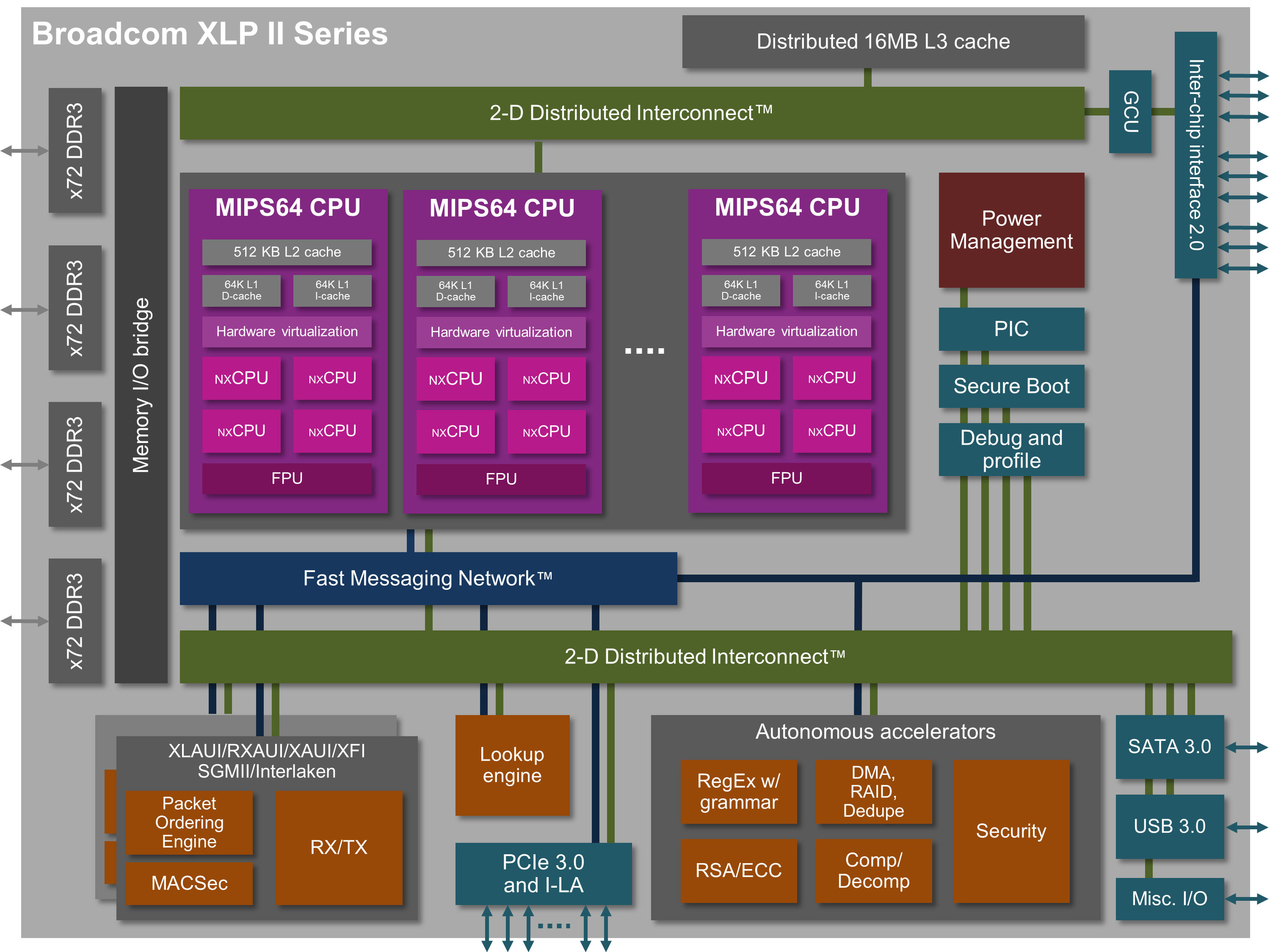
Introducing Project Vulcan
In 2012 Broadcom started working on a new project, codename Vulcan. This time going with the ARM instruction set architecture. The new design was to be fabricated on TSMC’s leading-edge 16nm FinFET process and deliver Xeon-class performance. The new design builds heavily on the prior XLP II core. Broadcom replaced the MIPS64 decoder with an ARMv8 decoder. Since the ARM ISA is much more complex than the MIPS64 they had implemented before. the new decoder is beefier, emitting µOPs to handle some of the more complex ARM instructions which can result in more than a single µOP being emitted.
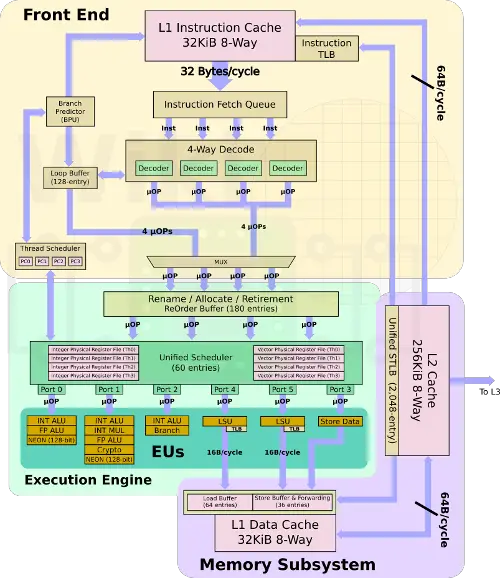
As with many of ARM’s own cores, Vulcan has a 128-entry loop buffer which replays the same sequence of decoded µOPs operations until a branch taken is hit, terminating the loop. During this time the entire front-end is clock gated in order to save power.
Like their older design, Vulcan kept the 4-way SMT support which was done by duplicating much of the architectural logic (states, PC, register files, etc..). The threader scheduler, with the help of the branch predictor, determines the next thread to fetch instructions from – fetching eight instructions and decoding four of them each cycle. Vulcan replaced the previous distributed instruction queue dispatch mechanism with a more efficient unified scheduler similar in design to Skylake’s. The new 60-entry scheduler can issue up to six µOPs from any thread every cycle. As with Skylake, both renaming and commit are done on 4 µOPs/cycle, capping IPC at that number.
Major changes were made to the execution units. Broadcom doubled the number of floating point units. Both units also support the NEON vector extension and are 128-bit wide (double the XLP II), providing a peak theoretical performance of 8 single-precision FLOPs/cycle or 8 GFLOPS at 1 GHz. By comparison, Skylake can do 32 SP FLOPs/cycle with the server variants that have a second FMA unit doubling that number to 64 SP FLOPs/cycle.
| High-Level Microarchitecture Analysis | |||
|---|---|---|---|
| Cavium | AMD | Intel | |
| Micro Arch | Vulcan | Zen | Skylake |
| Pipeline | 13-15 | 15-19 | 14-19 |
| L1I$ | 32 KiB 8-way | 64 KiB 4-way | 32 KiB 8-way |
| L1D$ | 32 KiB 8-way | 32 KiB 8-way | 32 KiB 8-way |
| L2$ | 256 KiB 8-way | 512 KiB 8-way | 1 MiB 16-way |
| Fetch | 32B/cycle | 32B/cycle | 16B/cycle |
| Decode | 4-Way | 4-Way | 5-Way |
| ROB Size | 180 | 192 | 224 |
| Scheduler | Unified (60) | Split Int (6×14)/FP (96) | Unified (97) |
| Issue | 6 | 10 (6+4) | 8 |
| LD Q | 64 | 72 | 72 |
| ST Q | 36 | 44 | 56 |
| L3$ | 1 MiB/core | 2 MiB/core | 1.375 MiB/core |
ThunderX2 incorporates 32 of those Vulcan cores onto a single die manufactured by TSMC on their 16nm process.
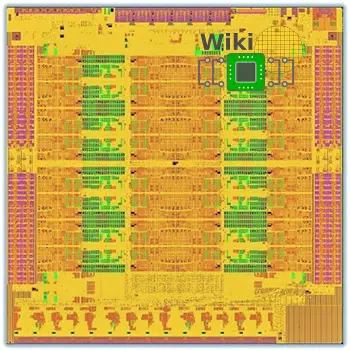
For reasons not well understood, Broadcom decided to terminate the project. In 2016, after years of dormant existence, Cavium acquired the designs from Broadcom which is how the new ThunderX2 came about. It’s unclear how much Cavium has actually modified the die from its Broadcom days but it was originally rumored to be around 600 mm².

Arranged in quad-core clusters, the quadplexes are attached to a bidirectional ring bus via the L3 which presumably also functions as a crossbar for the cores.

Multiprocessing
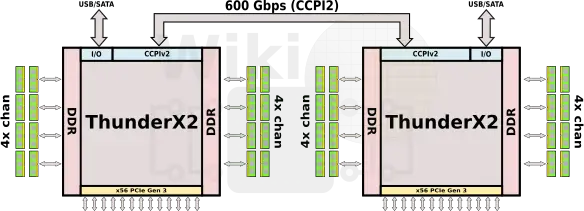
Targeting the server market, the ThunderX2 has 2-way multiprocessing support through Cavium’s 2nd-generation Cavium Coherent Processor Interconnect (CCPI2). Each die integrates 24 25-Gbps SerDes for a total aggregated bandwidth of 600 Gbps between the two sockets. That’s 2.5 times the bandwidth of their original (ThunderX(1)) interconnect and just under the 624 Gpbs that’s offered by Intel’s top Xeon Platinums models.
| 2-Way Multiprocessing Comparison | |||
|---|---|---|---|
| Cavium | AMD | Intel | |
| Micro Arch | Vulcan | Zen | Skylake |
| Interconnect | CCPI2 | IF | UPI |
| Max Cores | 64 | 64 | 56 |
| Max Threads | 256 | 128 | 112 |
| Max Channels | 16 × DDR4-2666 | 16 × DDR4-2666 | 12 × DDR4-2666 |
| Max Memory | 4 TiB | 4 TiB | 3 TiB |
| PCIe Lanes | 112 | 128 | 96 |
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–