
A Look at Cavium’s New High-Performance ARM Microprocessors and the Isambard Supercomputer
Introducing Isambard
Isambard is new Tier 2 supercomputer named in honor of Isambard Kingdom Brunel, a famous English Victorian civil engineer. Tier 2 means this is a regional HPC center in the UK and is the only Tier 2 ARM-based supercomputer being researched at that tier. The goal of the system is to act just like any of the other Tier 2 x86-based supercomputers, running all the typical HPC workloads with the underlying ISA being transparent to the end user. Isambard builds on prior work done by Mont-Blanc as part of the European Union 7th Framework Program (7FP) which explored the feasibility of the ARM architecture for HPC-related workloads. Though encouraging, mobile ARM chips proved to be inadequate for HPC workloads. Custom designed server-class ARM processors were necessary to compete with current HPC-optimized hardware. Cavium’s introduction of the ThunderX2 provided a unique opportunity to continue this research using far more competitive hardware.
Isambard is a Cray XC50-series supercomputer. While typically based on Intel’s Xeon Scalable processors, this system uses dual-socket Cavium’s ThunderX2 processors. Consisting of a little over 10,000 cores and using Cray’s Aries 1 interconnects, Isambard is expected to be the highest-performance ARM supercomputer. The full computer is expected to feature somewhere around 160 nodes. Each node includes two 32-core ThunderX2 processors running at 2.1 GHz for a total of 10,240 cores and 172 teraFLOPS of peak theoretical performance (though not high enough to make it to the TOP500). While the full XC50 ARM system will be installed in July, the University of Bristol does currently have access to a few early-access nodes which they have been using for development and testing. Those nodes use the same Cavium ThunderX2 processors as the full Isambard XC50 system, but in a Foxconn white box form-factor.
At the recent Cray User Group (CUG) 2018 conference, they presented their initial benchmarks based on the Isambard early-access nodes. They expect the full production system to deliver even higher performance.
Their tests were based on ThunderX2, Knights Landing, Xeon Platinum (Skylake), Xeon Gold, and Broadwell.
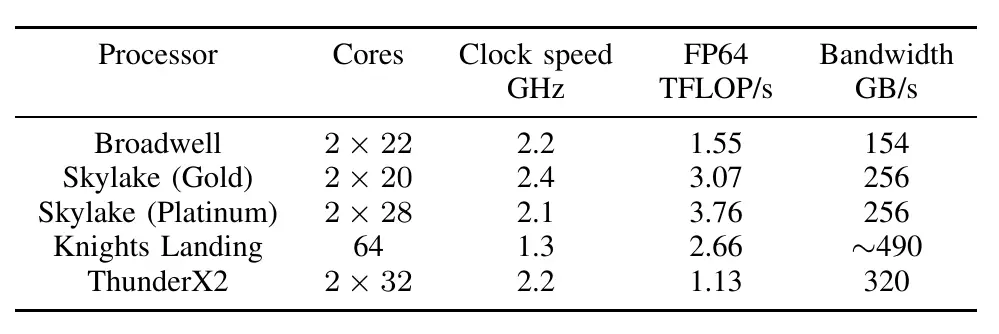
As far as Xeon Phis go, they used the 64-core 1.3 GHz Xeon Phi 7210 with 96 GiB of DDR4-2400 memory and 16 GiB of MCDRAM. For the Broadwell comparison, they used the 22-core Xeon E5-2699 v4 operating at 2.2 GHz in dual-socket configuration with 128 GiB of DDR4-2400. For the two Skylake parts, they used the dual-socket 20-core 2.4 GHz Xeon Gold 6148 and the 28-core 2.1 GHz Xeon Platinum 8176, both with 192 GiB of DDR4-2666 memory. Those parts were accessed through the Cray XC40 supercomputer ‘Swan’.
Mini-Apps
A number of common HPC-related synthetic benchmarks were tested; simple tests that serve quite well as performance proxies for actual HPC production code, incorporating traits such as memory access patterns, floating point throughput, and communication patterns. It’s worth noting that the five benchmarks the University of Bristol has chosen happen to be more memory-bound than anything else thereby somewhat skewing the picture in ThunderX2 favor.
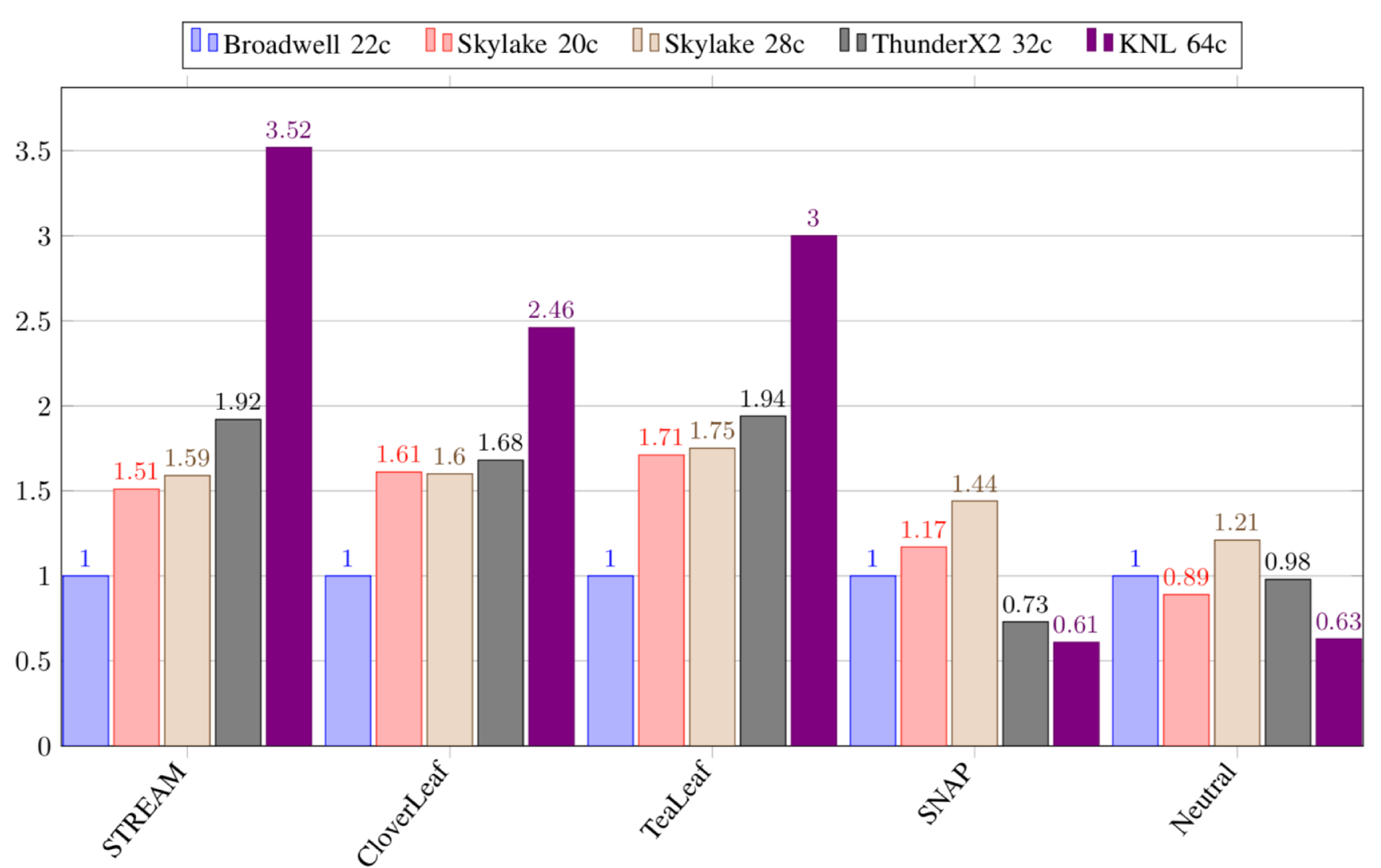
In the graph above, all values were normalized to Broadwell.
Since STREAM measures the sustained memory bandwidth of the system, we expect it to scale with the memory channels offered by the processor. The benefits of Cavium’s ThunderX2 extra memory channels are quite obvious in the benchmark. They reported 84.4%, 80.4%, and 77.8% of theoretical peak memory bandwidth for Broadwell, Skylake, and ThunderX2 respectively. They also found that the best STREAM Triad performance was achieved running 16 OpenMP threads on the ThunderX2, instead of one thread per core.
The CloverLeaf mini-app solve compressible Euler equations on a Cartesian grid. Similar to the STREAM Triad performance, CloverLeaf is also bound by the memory bandwidth. One phenomenon reported exclusively for the ThunderX2 is that as the simulation progress, the time per iteration also increases. No such effect was noticed on the x86 chips. They attribute this phenomenon to the increase in data-dependent floating-point intrinsic operations (e.g., abs/min/sqrt). That is, as the simulation progresses, the reliance on those operations also increases which in turn becomes less memory bound and more compute intensive, giving the x86 parts a slight edge.
The SNAP mini-app proxy application is a little more interesting. Both Knights Landing and the ThunderX2 perform worse despite higher memory bandwidth. SNAP main kernel keeps a small working set data in the low-level caches while sifting through very large data sets. Whereas ThunderX2 operates on 128-bit wide vectors as well as loads and stores which means about a quarter and half of a cache line is loaded, Broadwell operates on 256 bits and Skylake doubles it to 512. Those wider operations mean full cache lines are loaded at a time, giving Skylake a clear advantage despite lower memory bandwidth. It’s worth pointing out that Knight Landing also operates on 512-bit blocks, however, since caches operate at core frequency, the low operating frequency negatively impacts its performance.
The results for Neutral are expected given the random memory access nature of the program coupled with its low cache reuse. Higher memory bandwidth does not provide any real advantage for this type of workload.
The results for the graph above are the best performance obtained after testing all available compilers. As expected, the best performance for the Intel processors came from Intel’s own C++ Compiler. As for the ThunderX2, no one compiler dominated the performance across all benchmarks.
HPC Workloads
In addition to the mini-apps, the University of Bristol has tested the performance of the most heavily used real application code that runs on ARCHER (Advanced Research Computing High-End Resource) which is the UK’s primary academic research supercomputer.
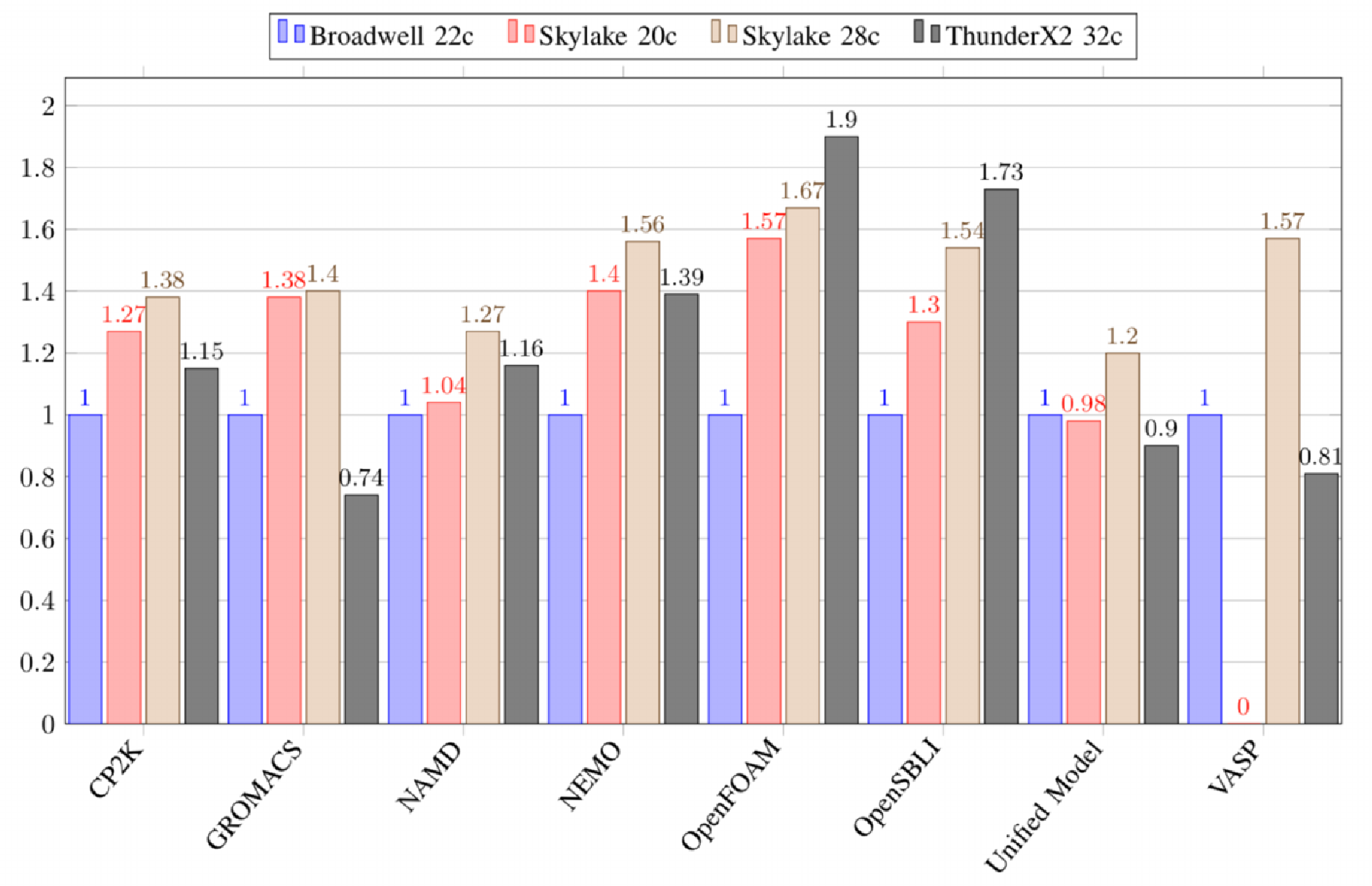
It’s worth pointing out that eight out of the top ten application codes are written in Fortran. For actual HPC workloads, the results above paint a slightly different picture. Whereas some benchmarks, such as OpenFOAM and OpenSBLI, directly benefit from higher memory bandwidth, most other workloads require a much finer balance between memory bandwidth, vector operations, and core and cache architecture in order to deliver higher performance.
Final Thoughts
Overall, initial Isambard supercomputer-related research has been very encouraging; showing that high-performance ARM microprocessors such as the ThunderX2 can compete well against Intel’s top offerings – at least in the workloads they have been working with. While the software ecosystem is not entirely ready, Cray’s software stack for their ARM-based supercomputers is already proving to be quite robust. ThunderX2 has arrived at an interesting time to aid the ARM server ecosystem with a product that is not only cost-competitive but also deployment-ready.
Unfortunately, a single decent initial product won’t be enough. Trying to enter this very lucrative market is not without risk, and Cavium is going to have to commit to a multi-generational roadmap which is going to be a very a costly endeavor. Cavium’s ThunderX2 introduction comes at the time when both Intel and AMD have very competitive products for the data center. Competition between the two will likely to intensify as we head into 2019. Only time will tell if Cavium is capable of breaking into a market that is essentially exclusive x86. For now, Cavium is definitely off to an excellent start.
Update: Our original story erroneously reported that the benchmarks presented were based on the Scout SC50 System. As noted, the system will only be installed later this year. Instead, the initial benchmarks are based on the Foxconn white box form-factor early-access nodes. This article has since been corrected. We apologize for the mistake.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–