
A Look At The AMD Zen 2 Core

Over the last month, we have been through numerous announcements by AMD. The company is preparing for the rollout of their 3rd-generation Ryzen desktop processors. Those processors will make use of AMD’s latest microarchitecture, Zen 2, which are fabricated on TSMC’s leading-edge 7-nanometer process.
AMD is expected to launch the new processors tomorrow morning at 9 AM Eastern. Ahead of the highly anticipated launch, we are taking a look at the core microarchitectural improvements.
Zen 2
At the heart of the new chips is the Zen 2 core. This core will make its way to AMD’s mobile APUs, high-performance desktop processors, and data center chips.
Zen 2 is the next major microarchitecture after Zen. With Zen 2, AMD is promising 13-15% IPC improvement based on Cinebench 1T and Spec2006 respectively. To see how they were able to extract this IPC gain we need to take a closer look at the underlying microarchitectural changes.

Front End
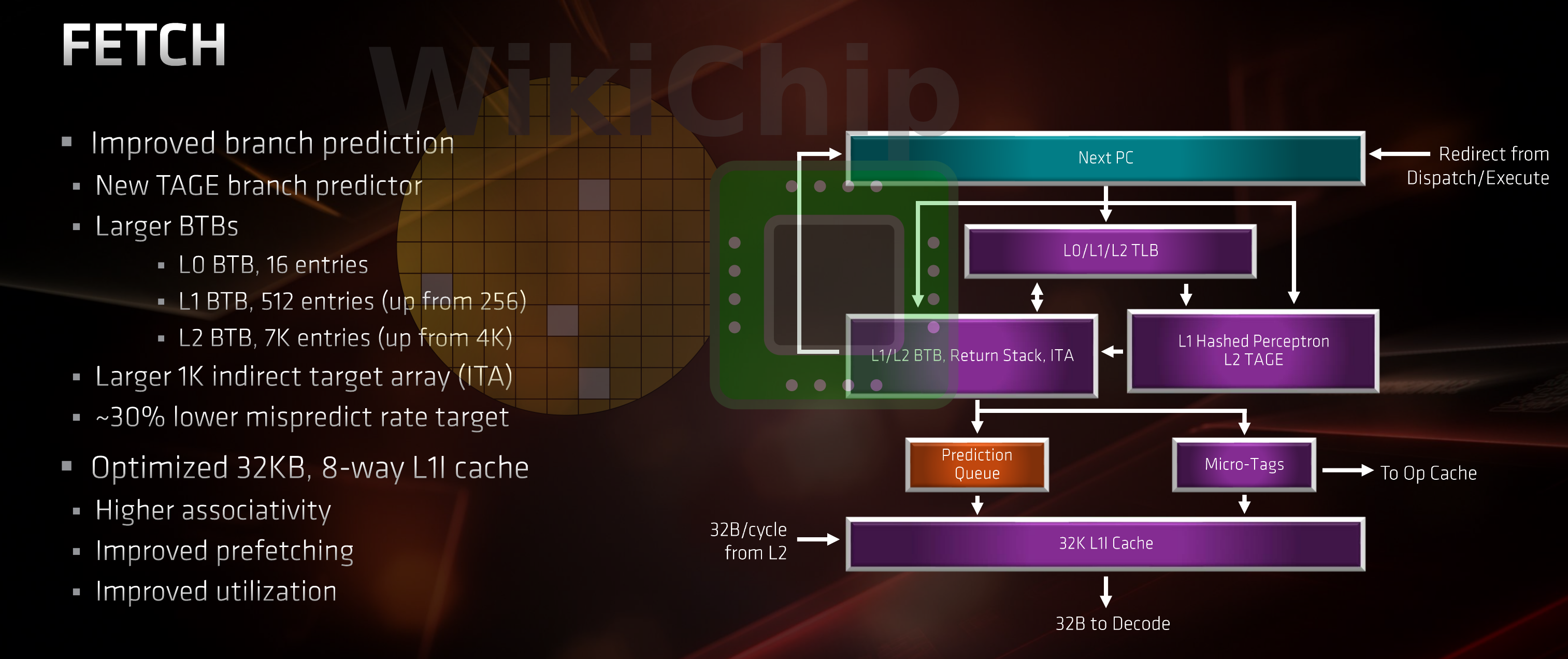
A big part of the front-end has been reworked. Under typical conditions when no branches are identified, instructions are fetched from the first level cache starting at the address of the next 64B block. Zen originally featured a 64 KiB L1 cache. It comprised of 4 ways of 256 sets. Zen 2 overhauled the L1. The associativity has changed to 8 ways of 64 sets, cutting the cache size by half to 32 KiB. Among other behavioral changes which are hard to characterized without further details from AMD, the higher associativity should reduce the miss rate as well. AMD noted that by reducing the size of the instruction cache and using that area in order to increase some other components, in particular, the BPU and OC, they are able to extract better performance per unit area of silicon. By the way, from an organizational point of view, Zen 2 is now identical to Intel’s Skylake and Sunny Cove. It’s worth noting that the level one instruction cache translation lookaside buffers remain unchanged. It’s still fully associative 64-entry deep buffer capable of storing 4 KiB, 2 MiB, and 1 GiB pages.
Cache lines remain 64 bytes and each cycle up 32 bytes can be fetched. On the less common scenario of a cache miss, the L1 will generate a fill request for the line containing the missed address. Each cycle up to 32 bytes may be transferred from the shared L2 to the instruction cache.
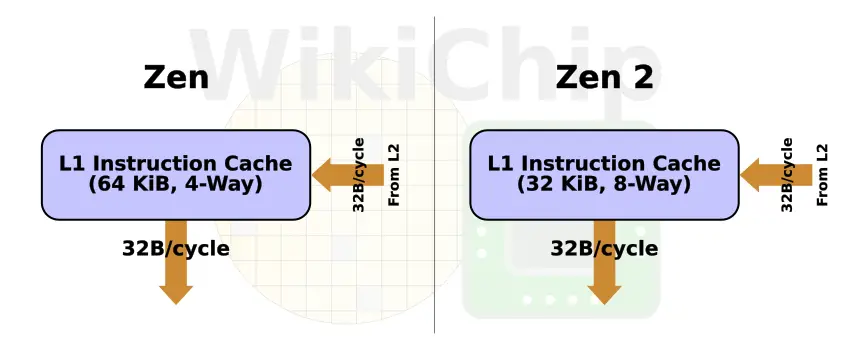
Along with the fill request generated by the fetch, additional requests may be issued by the branch predictor and the prefetcher. This is important as the prefetcher is able to take advantage of spatial locality in order to avoid stalls. This is another area AMD spent a lot of effort improving as you will see.
| Instruction Cache | ||||
|---|---|---|---|---|
| Company | AMD | Intel | ||
| µarch | Zen | Zen 2 | Coffee Lake | Sunny Cove |
| L1I Capacity | 64 KiB | 32 KiB | 32 KiB | 32 KiB |
| L1I Org | 4-way, 256 sets | 8-way, 64 sets | 8-way, 64 sets | 8-way, 64 sets |
May The Best Predictor Win
The goal of the branch prediction unit is to predict the next address of a conditional branch. In other words, guess whether it’s taken or not. The basic idea here is to guess the path of the instruction stream instead of wasting cycles by stalling the pipeline until the path is made conclusively known. This, however, must be done intelligently as poor predictions directly translate to wasted work. When a branch takes place, it is stored in the branch target buffer so that subsequent branches could more easily be determined and taken (or not). Modern microprocessors such as Zen take this further by not only storing the history of the last branch but rather last few branches in a global history register (GHR) in order to extract correlations between branches (e.g., if an earlier branch is taken, maybe the next branch will also likely be taken).
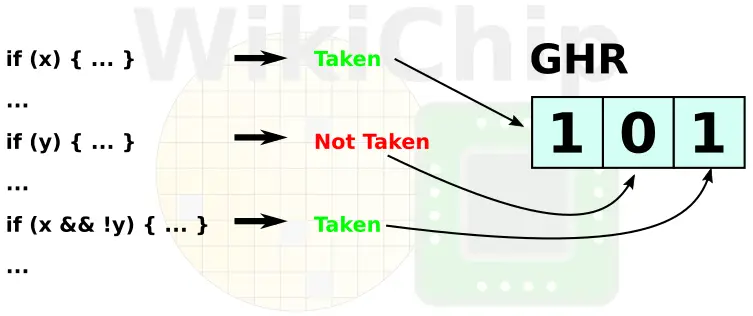
The BTB on Zen was a three-level cache – each one featuring higher capacity at the cost of higher latencies. Zen 2 keeps the structure the same, but close to doubles the number of entries in the second and third level BTBs to 512- and 7K- entries (up from 256 and 4K respectively).
By the way, on Zen a lookup in the first level (L0) BTB is a zero-latency lookup while consequent table lookups in the L1 and L2 BTBs results in one and four bubbles respectively. It’s unclear if those costs have changed with Zen 2.
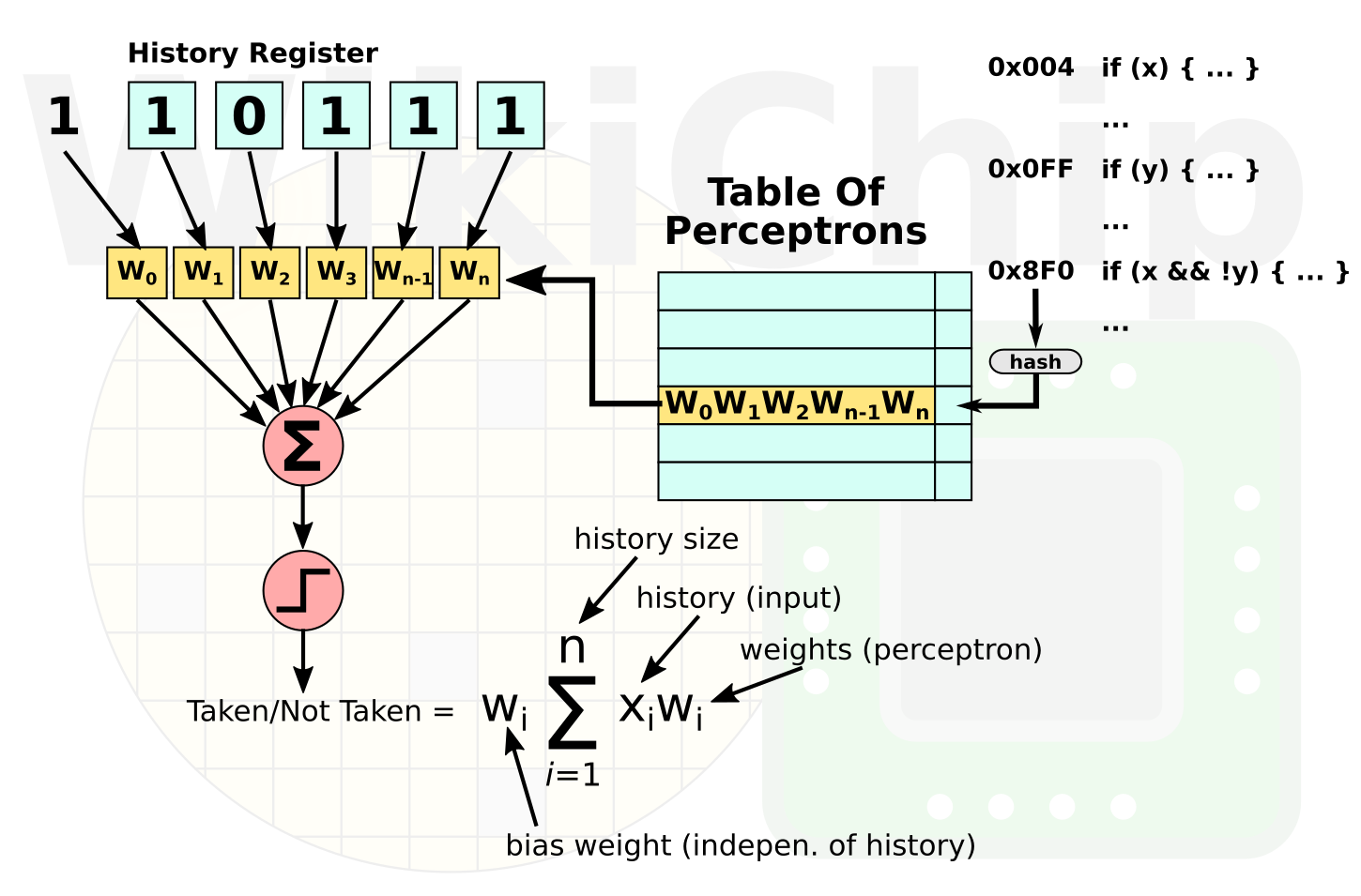
Zen employs a dynamic predictor known as a hashed perceptron. Taking advantage of the AI hype, marketing loves calling it a neural network predictor. Perceptrons are the simplest form of machine learning and lend themselves to somewhat easier hardware implementations compared to some of the other machine learning algorithms. They also tend to be more accurate than predictors like gshare but they do have more complex implementations. The actual implementation on Zen is not known but we can at least describe what a simple one would look like. When the processor encounters a conditional branch, its address is used to fetch a perceptron from a table of perceptrons. A perceptron for our purposes is nothing more than a vector of weights. Those weights represent the correlation between the outcome of a historic branch and the branch being predicted. For example, consider the following three patterns: “TTNâ€, “NTNâ€, and “NNNâ€. If all three patterns resulted in the next branch not being taken, then perhaps we can say that there is no correlation between the first two branches and assign them very little weight. The result of prior branches is fetched from the global history register. The individual bits from that register are used as inputs. The output value is the computed dot product of the weights and the history of prior branches. A negative output, in this case, might mean ‘not taken’ while all other values might be predicted as ‘taken’. It’s worth pointing out that other inputs beyond branch histories can also be used for inference correlations though it’s unknown if any real-world implementation makes use of that idea. The implementation on Zen is likely much more complex, sampling different kinds of histories. Nonetheless, the way it works remains the same.
Given Zen pipeline length and width, a bad prediction could result in over 100 slots getting flushed. This directly translates to a loss of performance. Zen 2 keeps the hashed perceptron predictor but adds a second layer new TAGE predictor. This predictor was first proposed in 2006 by Andre Seznec which is an improvement on Michaud’s PPM-like predictor. The TAGE predictor has won all four of the last championship branch prediction (CBP) contests (2006-2016). TAGE relies on the idea that different branches in the program require different history lengths. In other words, for some branches, very small histories work best. For example, 1-bit predictor: if a certain branch was taken before, it will be taken again. A different branch might rely on prior branches, hence requiring a much longer multi-bit history to adequately predict if it will be taken. The TAgged GEometric history length (TAGE) predictor consists of multiple global history tables that are indexed with global history registers of varying lengths in order to cover all of those cases. The lengths the registers used forms a geometric series, hence the name.
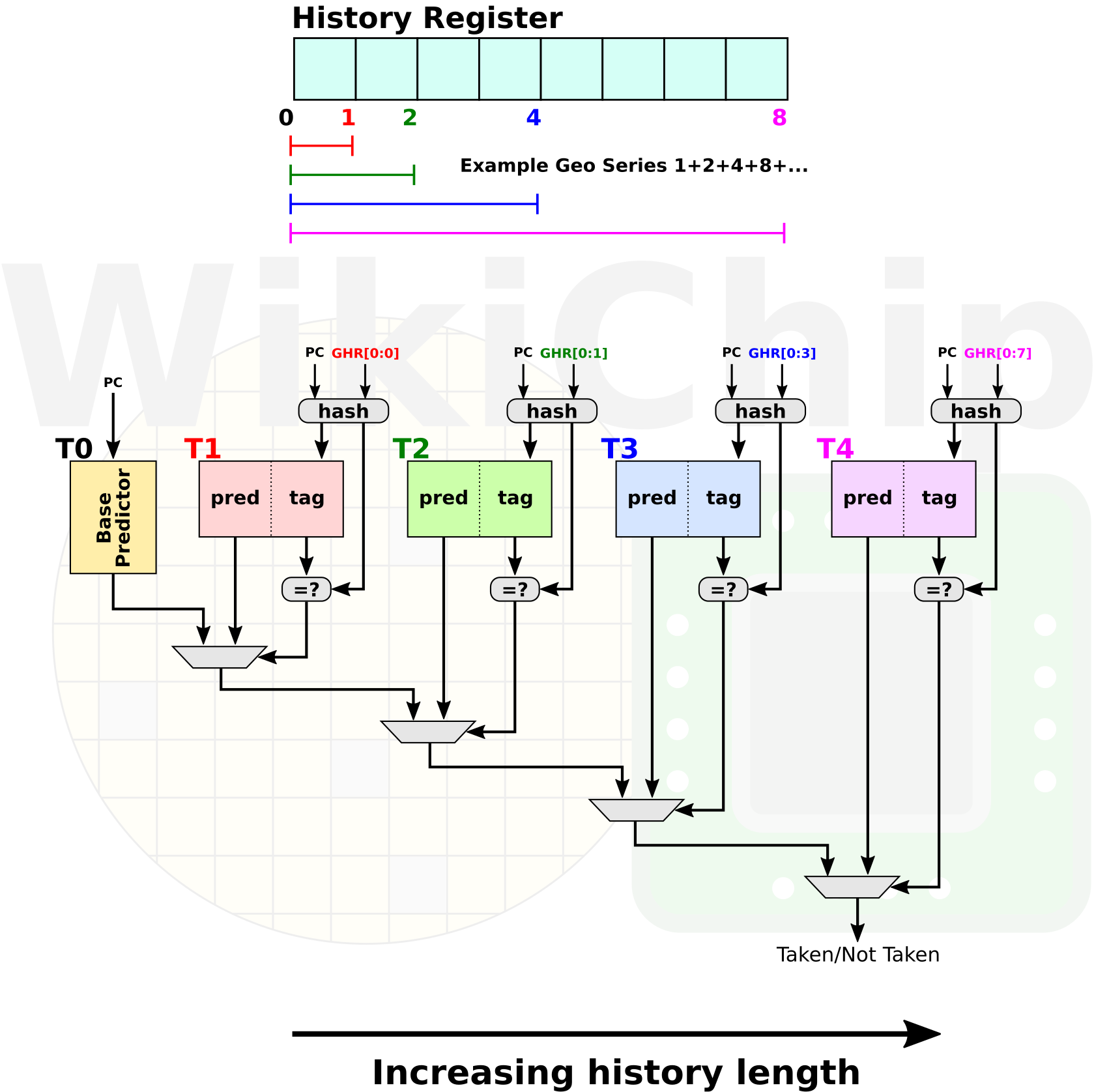
The idea with the TAGE predictor is that it tries to figure out which amount of branch history is best for which branch, prioritizing the longest history over shorter history.
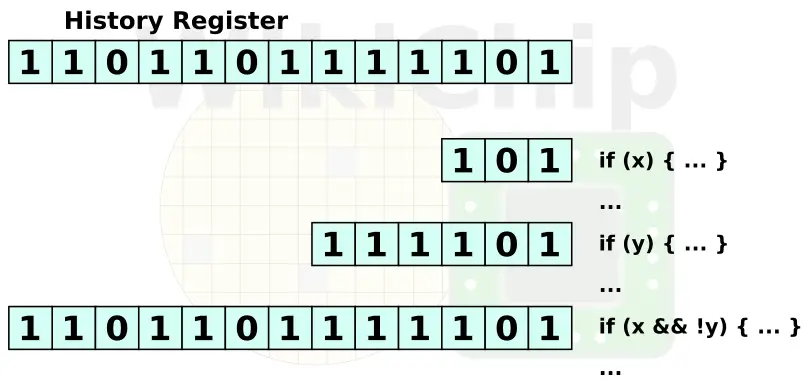
This multi-predictor scheme is similar to the layering of the branch target buffers. The first-level predictor, the perceptron, is used for quick lookups (e.g., single-cycle resolution). The second-level TAGE predictor is a complex predictor that requires many cycles to complete and therefore must be layered on top of the simple predictor. In other words, the L2 predictor is slower but better and is therefore used to double check the result of the faster and less accurate predictor. If the L2 predictor differs from the L1 one, a minor flush occurs as the TAGE predictor overrides the perceptron predictor and the fetch goes back and uses the L2 prediction as it’s assumed to be the more accurate prediction.
AMD did not disclose much more than they are using a TAGE predictor. It’s worth pointing out that the TAGE predictor is no longer considered the best, at least as far as literature goes. Seznec has since improved on the TAGE predictor with the addition of a statistical corrector (TAGE-SC) and later with a loop predictor (TAGE-SC-L). Alternative proposals include the BATAGE predictor. Nonetheless, the takeaway is that there is more opportunity for better branch predictors and this is a very active field of research.
AMD says that the new branch prediction unit exhibits 30% lower mispredict rate targets versus the prior perceptron implementation they had. Since modern microprocessors have an accuracy in the high-90s. Such a large reduction in the mispredict rate versus their implementation in Zen will translate directly to higher IPC. In fact, such a large improvement can single-handedly account for a large portion of the Zen 2 claimed performance improvement.
Change Of Status Quo
One thing that we have noticed about this generation of chips from AMD is the change in the status quo. Historically, Intel has invested considerable resources in designing the most advanced and highest performing predictors. On the other hand, AMD often lagged behind with a more conservative predictor that worked “well enough”. With the success of Zen, with Zen 2 things are a little different. While AMD is taking care of all the low-hanging fruits, they are now going directly after Intel where Intel has always had an indisputable lead. In other words, AMD appears to be confident enough with their current core design that they can spare more resources for the purpose of addressing secondary weaknesses.
OC Mode Improvements
Zen 2, like Zen, has two main operating modes: IC (instruction cache) mode and OC (op cache) mode. For those who are familiar with Intel’s terminology, those are analogous to Intel’s DSB and MITE paths. The IC mode path itself remains largely unchanged in Zen 2 and will not be discussed in this article. On the other hand, the OC mode has been enhanced.
As instructions get decoded, they get stored in the Op Cache. As is the L1I cache, the OC also operate on 64-byte cache lines. This gives you the ability to store up to 8 macro-operations per entry (goes without saying that 64b imm/etc will occupy two slots). In Zen, the OC was organized as 8 ways with 32 sets which means a total capacity for up to 2,048 MOPs. In Zen 2, AMD doubled the capacity to 4,096 MOPs. Presumably, this is done by doubling the number of sets. By the way, with SMT enabled, you are looking at half that capacity per thread. This means that on Zen 2, each thread now has an effective capacity that’s equal to the entire OP cache of Zen 1.
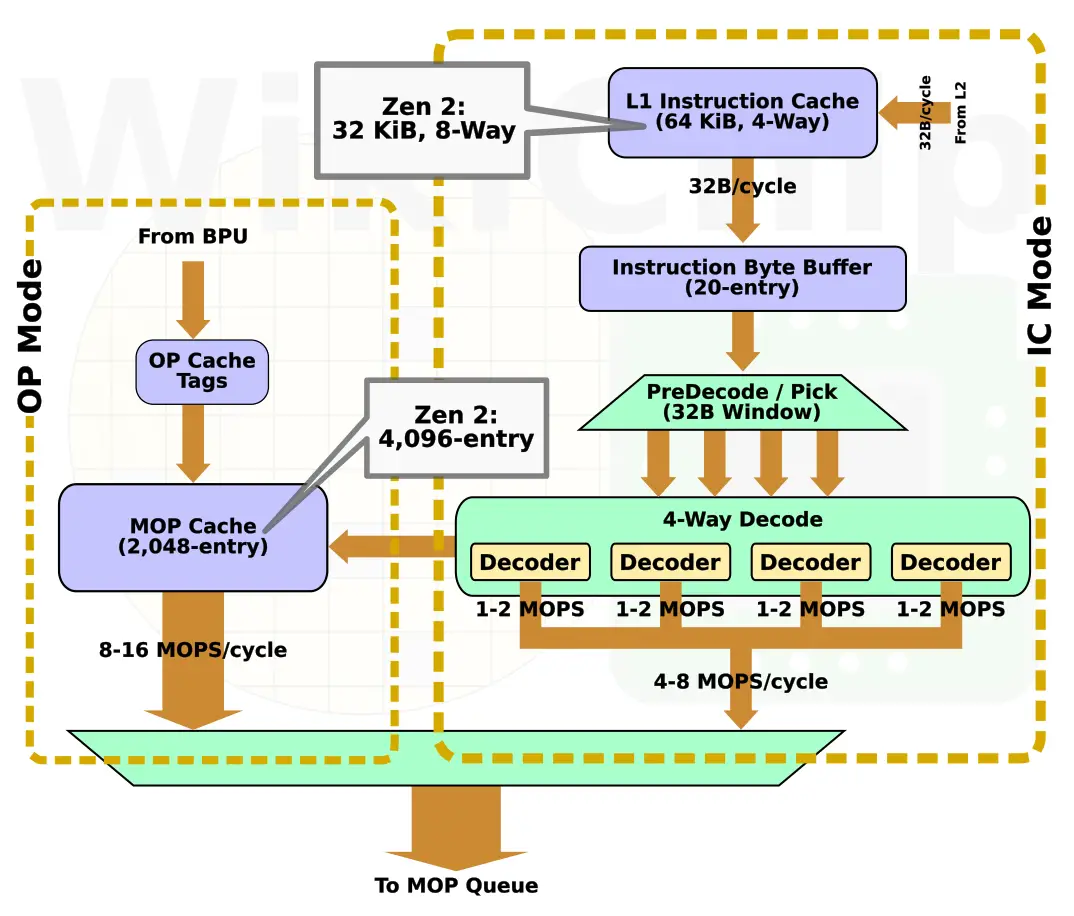
Once operating in OC Mode, the pipeline will remain in this mode until a miss occurs for a fetch address. When in OC Mode, the rest of the front-end is clock gated. Assuming all else is equal, the larger OC should allow Zen 2 to remain in OC Mode for longer instruction streams, elevating the IPC throughput all while reducing power in the front-end. As with Zen, the OC Mode is capable of delivering up to 8 instructions per cycle to the back-end – double the bandwidth of IC Mode. It’s worth noting that since the reorder buffer is still only capable of handling up to six MOPs per cycle, the higher throughput on the OP Cache is only helpful in ensuring the op queue stays filled.
| MOP/μOP Cache | ||||
|---|---|---|---|---|
| Company | AMD | Intel | ||
| µarch | Zen | Zen 2 | Coffee Lake | Sunny Cove |
| Capacity | 2,048 | 4,096 | 1,536 | 2,304 |
| Line size | 8 | 8 | 6 | 6 |
| Bandwidth | 8/cycle | 8/cycle | 6/cycle | 6/cycle |

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–