
A Look at Cerebras Wafer-Scale Engine: Half Square Foot Silicon Chip

The Fabric
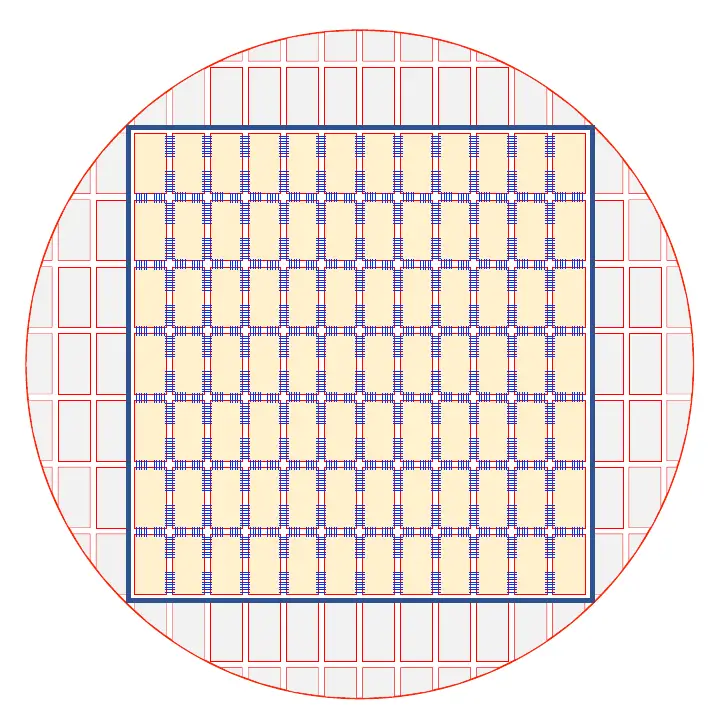
On the WSE, all the cores are interconnected using a uniform 2D mesh fabric with an emphasis on low latency for local communication. Cerebras uses a fully configurable fabric (a little bit more detail on that later). The fabric relies on fine-grain single-word message passing. Communication is done entirely in hardware, eliminating any software overhead.
This fabric is not only used for intra-die communication but with the uniform array of dies, Cerebras extended the inter-die connections to each of the adjoining dies across the scribe lines isolation region. This is part of their wafer-scale secret sauce. A single uniform 2D mesh connects all the core together as well as across dies. Wires between dies are done in essentially the same conventional way die stitching has always been done – via overlapping the reticle over the inter-die connections.
Cerebras partnered up with TSMC in order to solve the inter-die connections. They re-purposed the scribe lines – the mechanical barrier between two adjacent dies that are typically used for test structures and eventually for strangulation. With the help of TSMC, the metal deposition was extended across the scribe lines, enabling Cerebras to seamlessly extended the 2D mesh across the dies. In other words, the same communication that happens within a die is extended between dies. Driving signals over silicon in less than a millimeter of distance translates directly to an order of magnitude lower power for inter-chip communication.
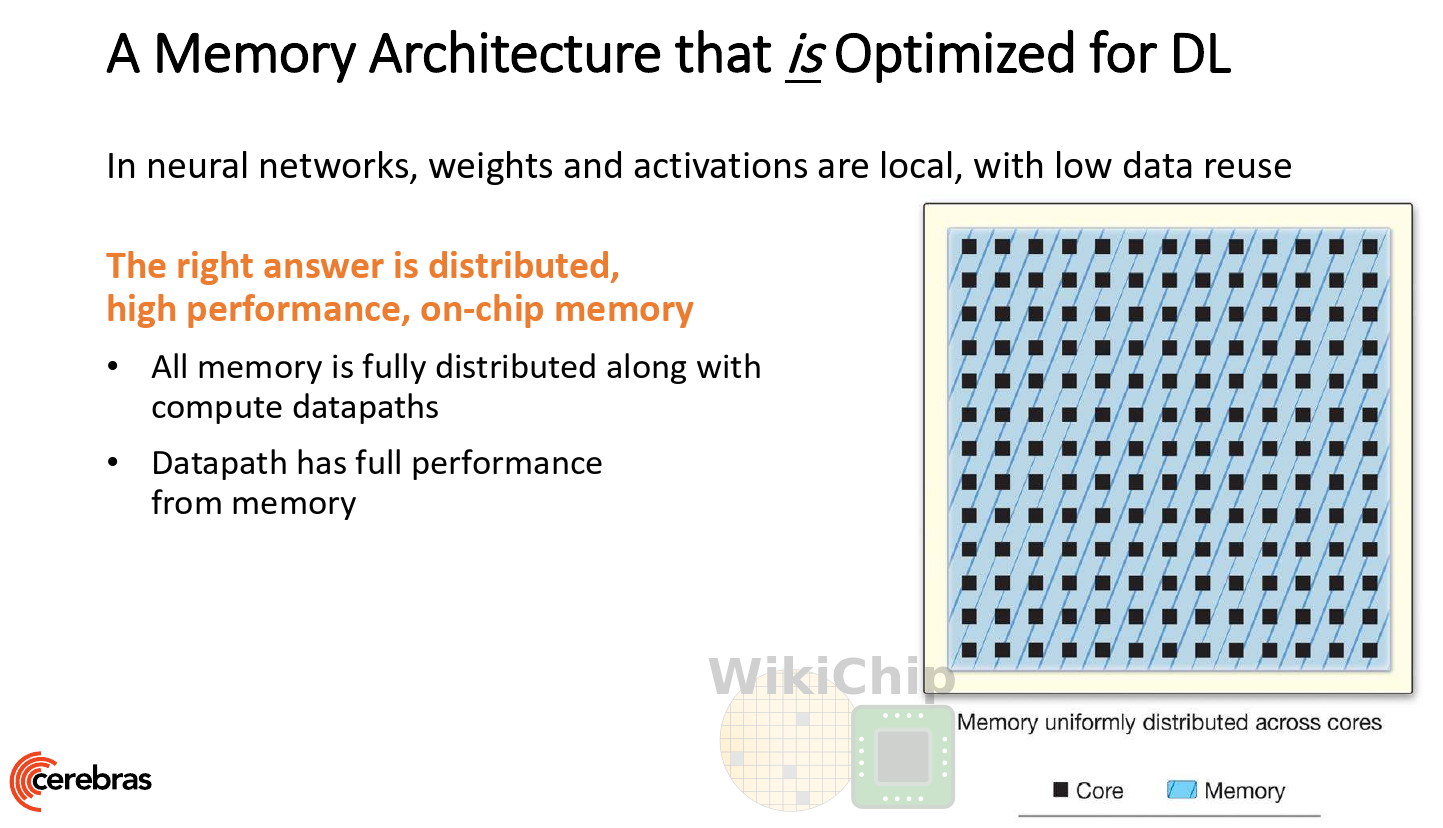
No External Memory
One of the drastic differences with the WSE versus all other designs is the memory. The WSE has no external memory. The entire memory is fully distributed across the cores in the on-chip SRAM. This isn’t much different from a big NPU with a large cache. However, the sheer size of the chip alone means that you simply get a lot of. With over 400K processing cores, there is over 18 GiB of memory with a memory bandwidth of 9 PiB/s. Since it’s all on-die, the power saving of not having to shift it all in and out of the chip is quite advantageous.
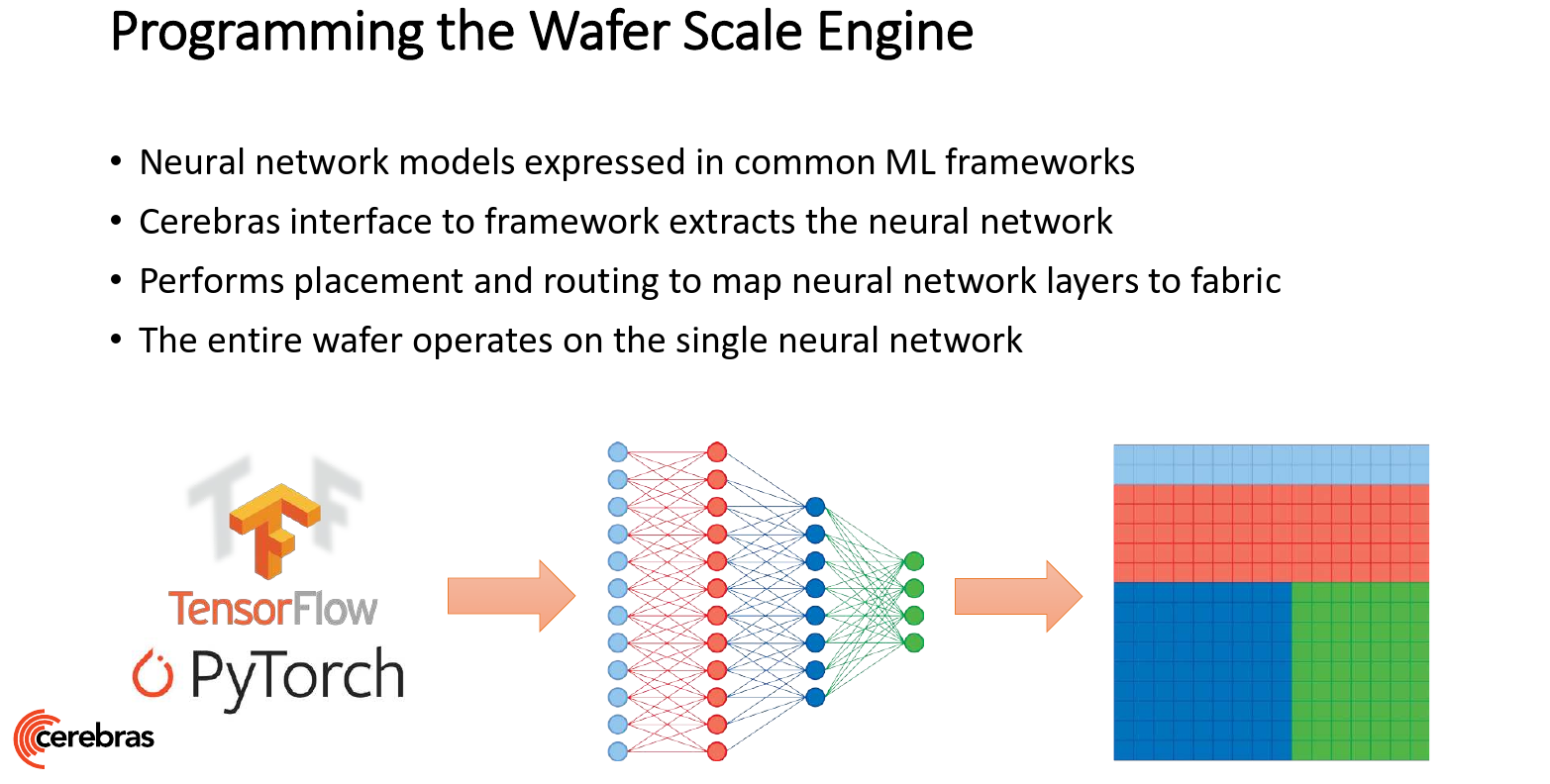
Cerebras says it has co-designed the software stack to match the architecture. Developers are able to use their existing ML framework such as PyTorch and TensorFlow. Cerebras software then executes its own place & route routine on the extracted the network from the framework. Cerebras says each layer gets sized up based on the compute, size, and bandwidth needs. Each layer is then optimally mapped onto a portion of the full wafer, allowing the entire wafer to operate on a whole neural network model at once.
Big Has Its Disadvantages
How’s the Yield?
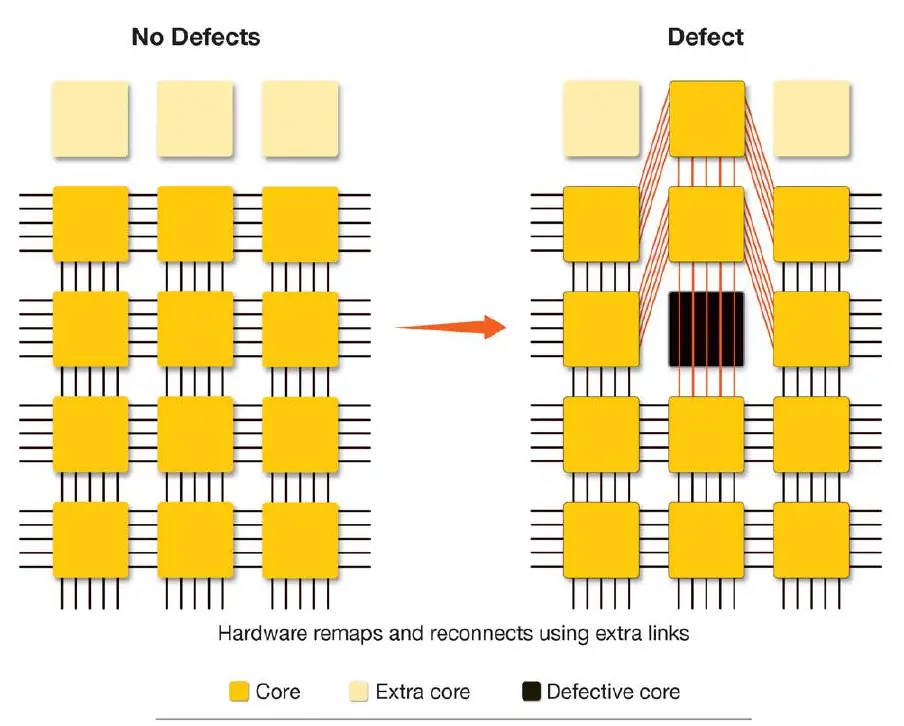
We know what everyone is thinking – how do they yield this thing? Let’s assume that 16FF+ has excellent defect density at this point due to its maturity. They are still not getting even a single perfect wafer – ever.
The answer is ‘simple’ – they copy the memory guys. The reason Cerebras designed their chip with 1000s of tiny cores per wafer is for this very reason – the ability to address yield in a relatively low-cost way. Baked into their architecture are both redundant cores and redundant fabric links. Each wafer incorporates around 1-1.5% of additional AI cores for redundancy reasons. It’s worth noting that the redundant cores are always reserved for redundancy. In other words, when there are no defects in a certain area, the redundant cores are simply disabled. In an area affected by a defect, a local redundant core is used to replace the defective core. The local fabric is then appropriately reconnected using the redundant fabric links. “By using this technique, we can drive yield incredibly high and it’s all transparent to the software since it shows up as a single uniformed fabric,†says Sean Lie, Founder and Chief Hardware Architect at Cerebras.
Thermal Expansion and Packaging
Unfortunately, just getting good yield is not sufficient, With a whole wafer, the thermal, the power, and the current involved are mind-blowing. Cerebras says that just delta in thermal expansion between the silicon wafer and the PCB results in too much mechanical stress, resulting in cracks.
To solve this problem, Cerebras designed a custom connector sandwiched between the silicon wafer and the PCB. The connector is designed such that it can absorb much of the variation while maintaining operational connectivity. More care was needed to handle the edges of the wafer where the more extreme variations occur.
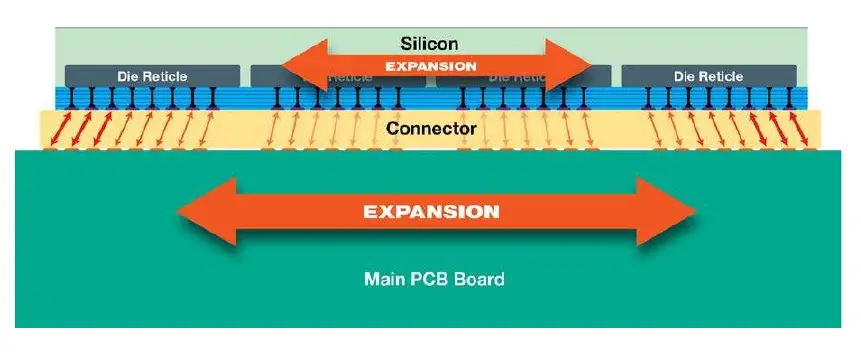
It goes without saying that due to its size, no standard packaging solution exists either. No standard design flow exists. Cerebras was entirely in uncharted territory here. It ended up developing its own custom package for its product that includes the PCB board, the connector, the WSE, and a cold plate. Cerebras says it had to develop its own custom packaging tools and process designed to ensure alignment and special handling.

Cooling and Power
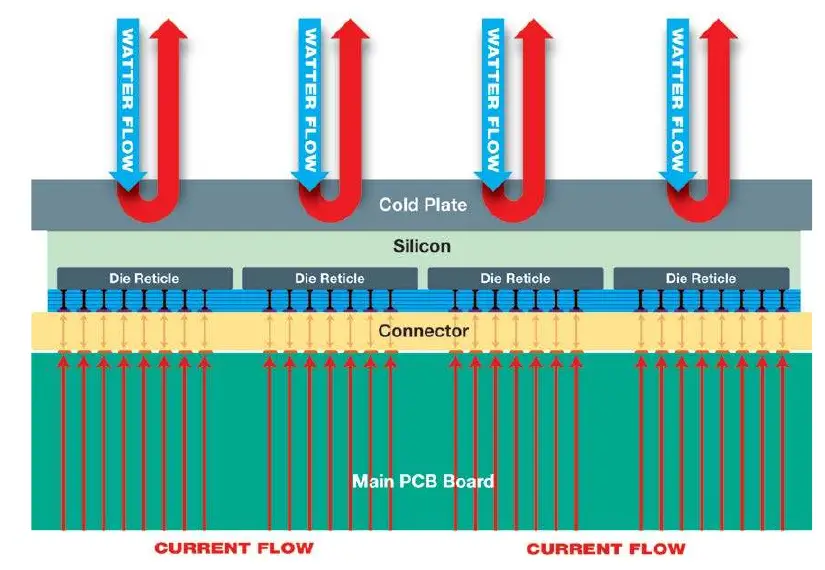
A wafer-scale engine is big and that also means a lot of current. Relying on a traditional PCB power plane delivery doesn’t work. The high current density means the usual lateral distribution system cannot be extended to the entire wafer. In other words, there is not enough copper in the PCB to sufficiently reach across the entire wafer. Cerebras experienced a similar problem with heat removal. The high concentration of heat meant running cool air across the entire wafer is not effective enough in removing the heat fast enough.
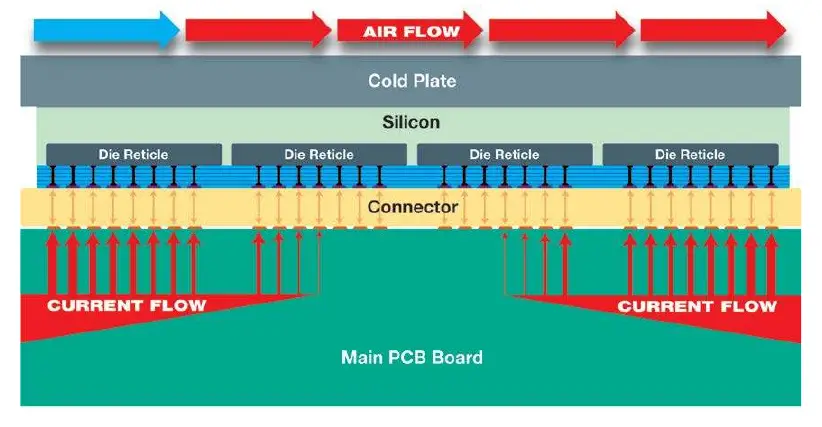
The solution Cerebras came up with is going vertical. Current distribution is done perpendicular to the wafer, avoiding the need for impossibly thick copper traces that would otherwise be required. In a similar manner, cold water carries heat from the cold plate directly out of the package perpendicular to the wafer. The two techniques enable highly uniform distribution of both power and cooling to the wafer, including at the edges of the wafer and in the middle.
Related Stories
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–