
Intel Unveils the Tremont Microarchitecture: Going After ST Performance
Front End
The most drastic change in Tremont is not the back-end but rather the front-end. Intel upgraded the branch prediction unit, now considering it close to their big core levels of accuracy. It’s beefier with long target arrays and long histories. Tremont features a multi-level predictor. The first level predictor which is lighter can predict with no bubbles while the second-level predictor adds two cycles of bubbles before switching over. Intel says that this gives them a fairly balanced machine with good throughput on well-predicted tight loops at the L1 PB level and good coverage from the L2 PB.
The branch predictor runs ahead on the 64B cache line, decoupled from the rest of the front-end, scanning 32 bytes at a time (half a line). Predict scans for branches. If a branch is encountered but is not taken, it continues to scan on. If it’s taken, you get the next starting address of the new decode stream – this is important for later on. When a branch is taken, it’s directed to fetch which will do your standard TLB and tag lookups and determine if the data is resident in the L1 cache. If the line is not in the L1 cache, a miss starts. Tremont supports up to eight outstanding misses. Likewise, if the branch is a hit, fetch will direct to retrieve it from the cache to the instruction cache data queue.

Dual-Cluster Out-of-order 3-Way Symmetric Decode
Here is why the discussion about finding new instruction streams was important. Tremont took the whole decode portion of Goldmont Plus and essentially doubled it. In other words, Tremont has a dual-cluster 3-way symmetric decode. Each cluster incorporates its own I$ data queue, 3-way decoder, and an instruction decode queue. The reason is so that each cluster can be given its own instruction stream and operate as if it’s an independent core front end.

Going back to the branch predictor discussed earlier. Suppose a subroutine is called. Cluster 0 will start operating on that instruction stream, decoding instructions and storing them in its instruction decode queue. While this is happening, suppose there is a function call to another subroutine in the instruction stream. The predictor will encounter a predicted taken, determine the new target address of the new instruction stream will be set up on the second cluster to start running in parallel to the first – essentially out of order. The front end will continue to load-balance between the two decode clusters while it detects new branches, allowing predict, fetch, and decode to operate concurrently without one necessarily blocking the other.
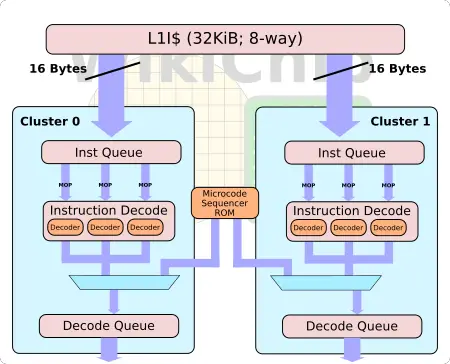
But what does this buy them? At a high level, Tremont is now a 6-wide decode with a peak decode throughput of six x86 instructions per cycle (for the most part, ignoring some of the really complex stuff that will incur throughput penalties). You can take the standard approach which is to widen the entire front end to something like a 5-wide or even 6 inline decoders but this is quite taxing which is why you’d usually add something like a big micro-op cache to improve the power efficiency by storing decoded instructions. Tremont took a slightly different approach. Like its predecessor, Goldmont Plus, an instruction stream only passes through 3 decoders so it’s essentially the same as before, but by doubling the whole decode cluster, Tremont can operate on two instruction streams simultaneously, significantly improving the front-end throughput without the area requirement.
By the way, Tremont has the option to operate in a single-cluster mode – this is a fused option so it must be done by Intel per-chip per product. What this does is essentially disable one of the clusters entirely so you get a similar front-end to Goldmont Plus (i.e., just a standard 3-way decode). This limits the decode throughput to just three instructions per cycle, limiting the peak throughput of the machine to three. This option makes different performance-power tradeoffs and for some workloads, the lower peak power consumption per core. This mode might be set by Intel for certain products where they believe the per-core power-efficiency tradeoffs are better.
Finally, the decoded results from the decoders are queued up in its own instruction decode queues. Note that while the two streams might be decoding out of order, they are queued up in their own decoded queues in order so they can be picked up in order.
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–