
A Look at Spring Crest: Intel Next-Generation DC Training Neural Processor

NoC
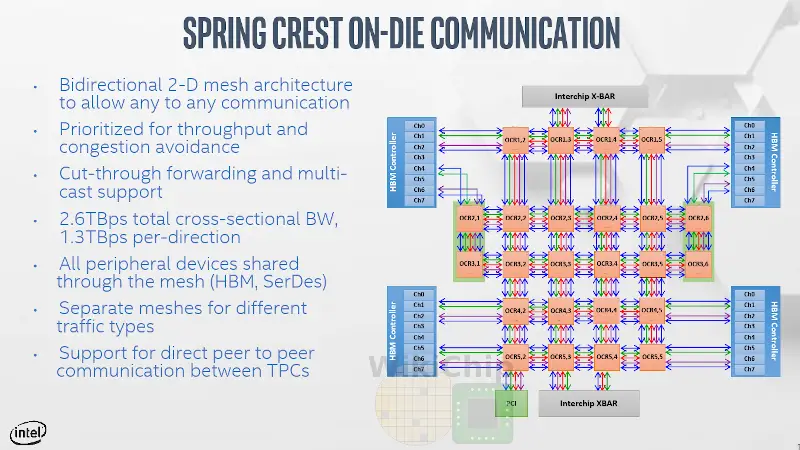
As we mentioned earlier, Spring Crest integrates a 2-dimensional mesh architecture. The chip is partitioned into quadrants Intel calls pods. Each pod includes six tensor procesing clusters and is linked to an HBM stack and ICL links. Each pod is interconnected to the nearest HBM stack and to the nearst ICL peripheral. There are a total of three full-speed bidirectional meshes – for the HBM, external InterChip interconnects, and neighboring pods.
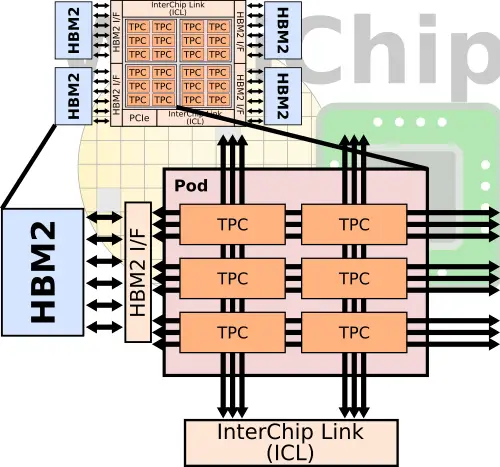

The different busses are designed to reduce interference between the different types of traffic (e.g., short TPC-TPC traffic versus HBM operations). As noted earlier, software statically schedules everything in an attempt to maximize data reuse and data fetches for higher utilization. Ideally, the software keeps the data for the TPCs in the HBM that’s directly linked to that pod for performance reasons. There is a total of 1.3 TB/s of bandwidth in each direction for a total of 2.6 TB/s of cross-sectional bandwidth on the network.
Scale-Out
Spring Crest has scale-out support in order to run very large models efficiently across multiple chips and chassis. On each die are 64 SerDes lanes that are grouped into quads. Each quad operates at 28 GT/s for a total bandwidth of 28 GB/s. There are a total of four InterChip Link (ICL) ports, each comprising of four quads. This gives you a peak theoretical bandwidth of 112 GB/s per port and close to 450 GB/s (3.6 Tb/s) of peak aggregated bandwidth.
The ICL links come with a fully programmable router built-in designed for glue-less connections in various topologies. Yang mentioned a couple of popular ones that the chip supports including a ring topology, a fully connected topology, and a hybrid cube mesh topology. Other topologies are also possible. There is support for virtual channels and priorities for traffic management and complex topologies as well as to avoid deadlocks. There is also built-in support for direct transfer to local memory.

To simplify scalability, the Nervana NNP-T uses a hierarchical and consistent programming model for both on-die and off-die. Both communication and synchronization primitives are consistent on-chip and off-chip, allowing problems to get partitioned hierarchically – at the TPC level, pod level, chip level, and system level. In other words, a problem can be mapped to a few TPCs initially, and as the model size grows, it can scale to more TPCs as well as to multiple chips in the very same manner.
Shipping
Intel says it will be sampling the NNP-T to lead customers by the end of this year. Broader availability is expected sometimes in 2020.
Related Stories
Derived WikiChip articles
- Spring Crest – Microarchitectures – Intel Nervana – WikiChip
- Neural Network Processors (NNP) – Intel Nervana – WikiChip
- Flexpoint – WikiChip
–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–