
Hot Chips 30: AMD Raven Ridge
To Infinity and Beyond
At the heart of Raven Ridge is the Infinity Fabric. The fabric was designed to accommodate a plethora of different engines and components. At the heart of the infinity fabric coherence protocol is the Coherent HyperTransport. Bouvier explains that at the edges of the scalable data fabric (SDF) are the scalable data ports (SDP) which was defined as a standard port definition for all IP connections on the chip. The goal was simplify verification and turnaround time by keeping the coherency complexity at the SDP. Since all the various components were being designed simultaneously by different groups, ensuring everyone follows the same underlying protocols greatly simplified development. By the way, much of this appears to be fairly identical to the original Coherent HyperTransport (cHT) interface developed by AMD as a proprietary extension to the HyperTransport interconnect. Previously, AMD used the cHT extension as the means of supporting coherency on their Athlon 64 FX and Opteron processors.
For the most part, Raven Ridge is quite similar to the standard Zeppelin with an addition of a GPU, Multimedia Hub, and the Display Controller.
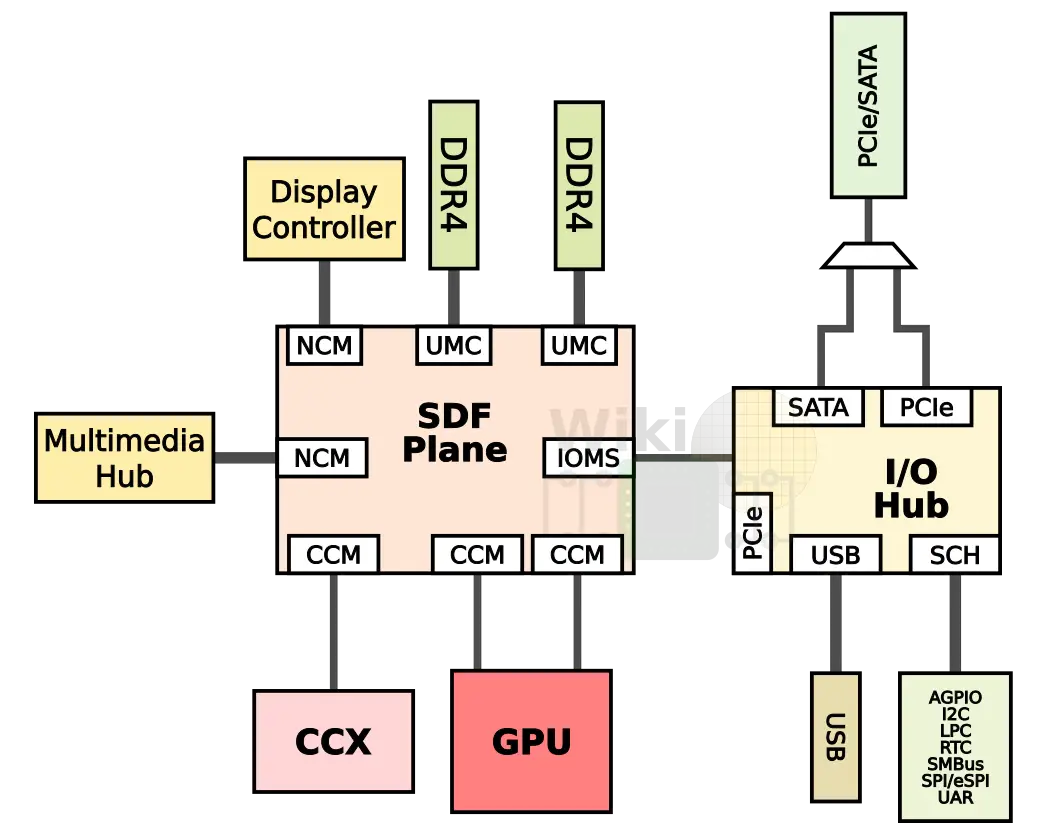
Like the Zeppelin, Raven Ridge uses an internal datapath width of 32 bytes supporting a frequency of up to 1.6 GHz (MEMCLK) for a bandwidth of 51.2 GB/s in each direction. Whereas the CCX has a single port (i.e., a single connection to the transport layer via the cache-coherent master (CCM)) like in the Zeppelin, the GPU has double the ports for double the bandwidth.
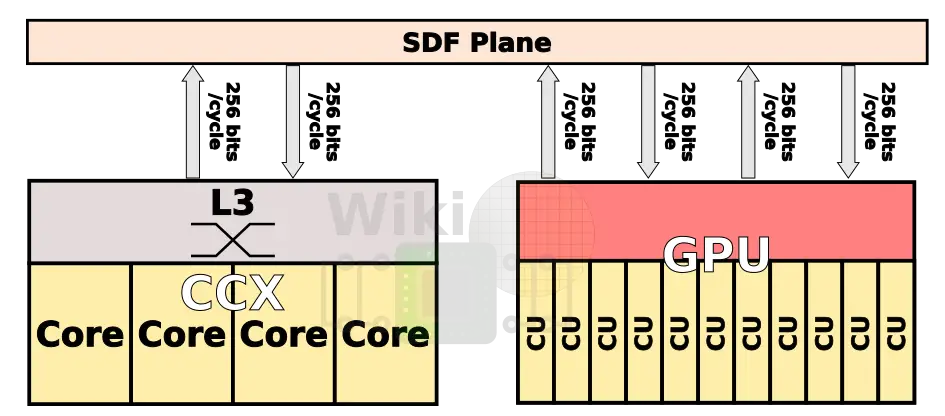
Even with double the ports, the memory bandwidth is a problem for the Vega GPU. Deferred primitive batch binning also helps increase the memory efficiency by delaying processing operating until there is a complete set of pixels for a given primitive bin which allows discarding of non-contributing fragments prior to shading. Other enhancements such as a large 1 MiB L2 dedicate GPU cache and the lossless delta color compression carried over from prior generation also helps improve the effective bandwidth.
The transport layer itself consists of four switches (crossbars) capable of doing 5 transfers per cycle. The CCX/GPU interface via the cache-coherent masters whereas the memory controllers interface via the cache-coherent slaves.
The transport layer itself is structured for dual-region power gating. Under certain low-power situations (e.g., display refresh), various regions of the silicon can be entirely power-gated to save power. Region B consists of the CPUs and GPU along with the I/O Hub. Under operations such as video playback, Region B can be entirely power gated to save on power.
QoS
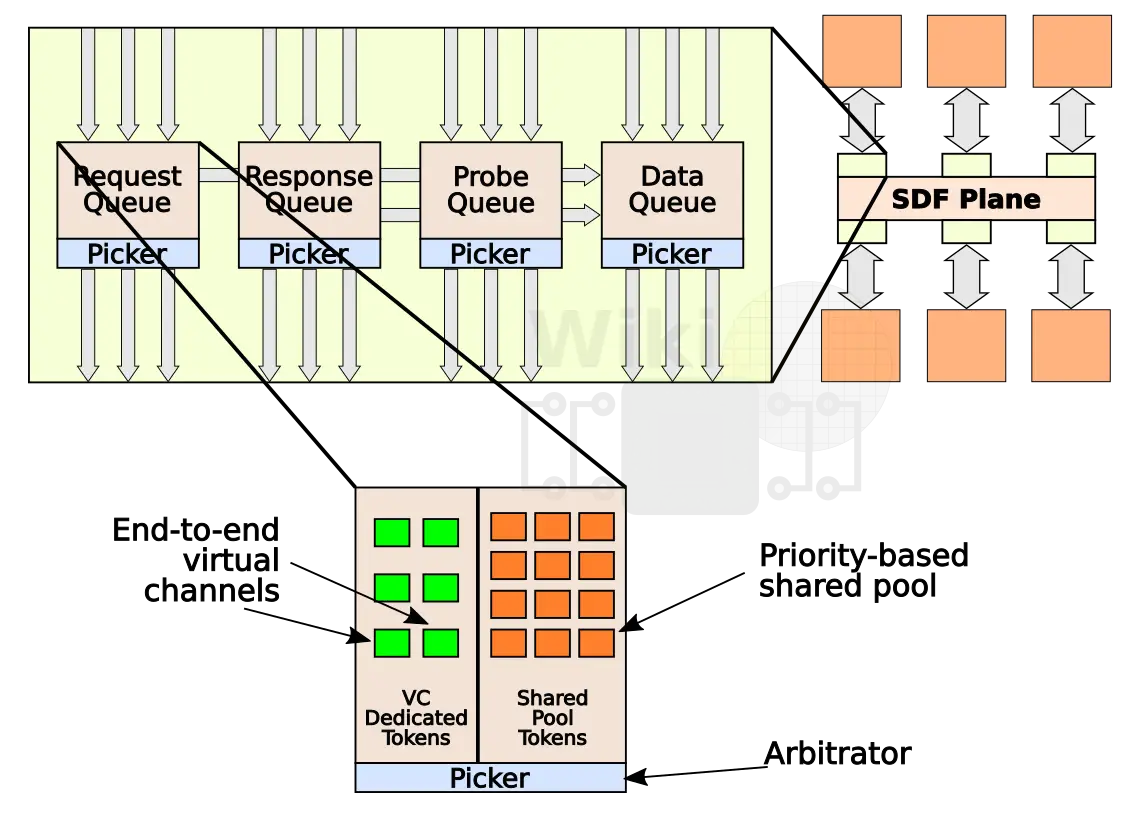
Enhancing user experience requires a good QoS implementation. At each end-point to the transport layer are transport request queues, each supporting multiple virtual channels as well as a shared request pool. Those queues support three request classes: non-real time requests, soft real-time, and hard real-time. Picker arbitration is age-based with overriding priory and virtual channel availability. By the way, with end-to-end virtual channels, channel priority escalation is also possible.
Bouvier presented a graph of frequency vs frame rate for Shadows of Mordor at 1080p which generates a lot of memory traffic. Two parts were compared: Bristol Ridge and Raven Ridge with 8 CU (same configuration as BR). It can be seen that at the high frequency range, better memory utilization results in higher frame rate for the Vega GPU.

–
Spotted an error? Help us fix it! Simply select the problematic text and press Ctrl+Enter to notify us.
–